FCL taco2
1.0.0
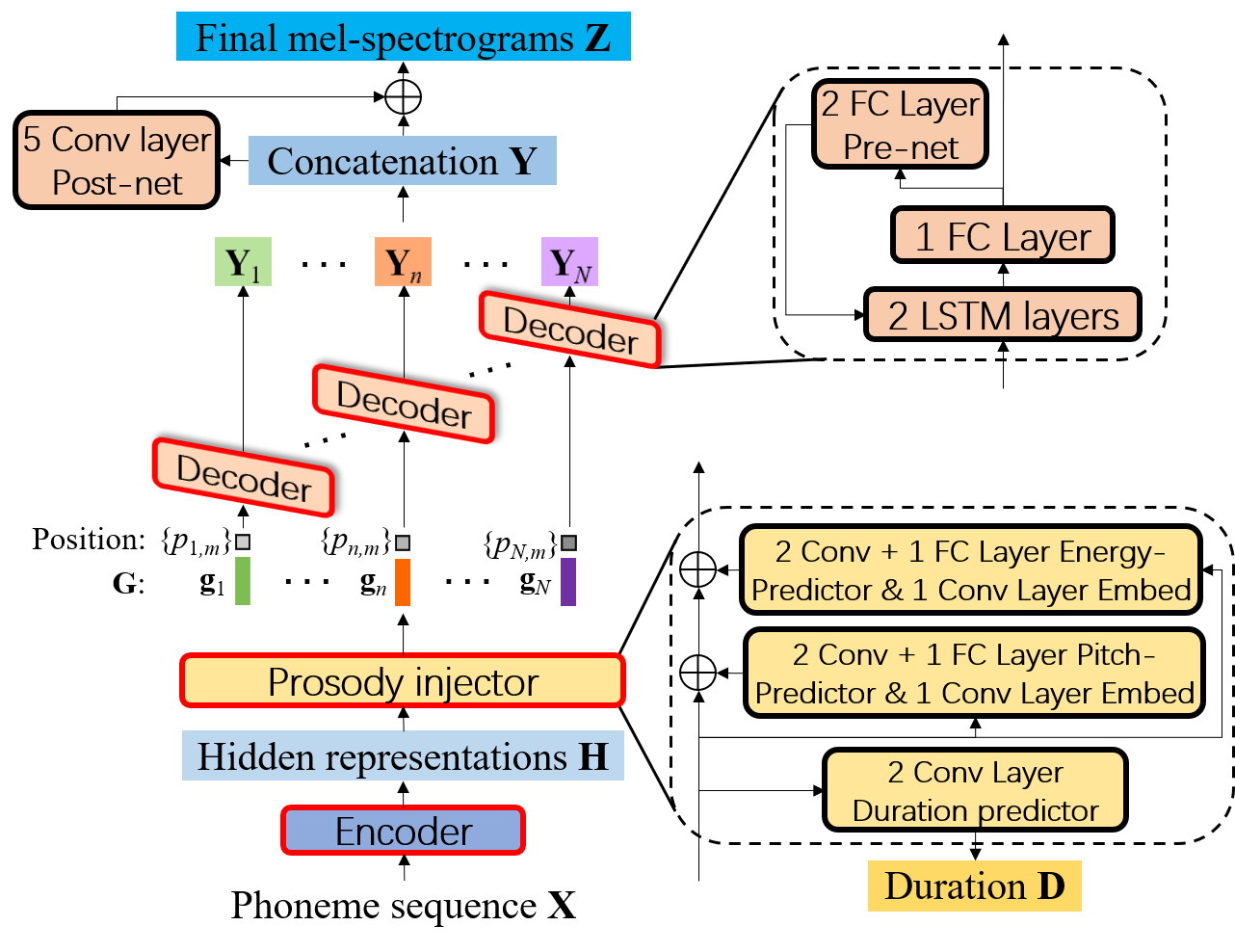
Blockdiagramm von FCL-TACO2, bei dem der Decoder im AR-Modus in jedem Phonem Melspektrogramme erzeugt und für alle Phoneme geteilt wird.
Laden Sie ljspeech herunter
Packen Sie ljspeech-1.1.tar.bz2 an /xx/ljspeech-1.1 aus
Erhalten Sie die erzwungenen Ausrichtungsinformationen mithilfe von Montreal erzwungenen Aligner -Tool. Oder Sie können unsere Ausrichtungsergebnisse herunterladen und dann an /xx /textGrid auspacken
Vorverarbeitet den Datensatz, um Melspektrogramme, Phonemdauer, Tonhöhe, Energie und Phonemsequenz zu extrahieren, um:
python preprocessing.py --data-root /xx/LJSpeech-1.1 --textgrid-root /xx/TextGrid
Schulungslehrermodell FCL-TACO2-T:
./teacher_model_training.sh
Schulungsmodell FCL-TACO2-S::
./student_model_training.sh
PARALLEL-WAVEGAN VOCODER-Training: Befolgen Sie die Anweisungen hier. Sie können auch den vorgebildeten PWG-Vokoder herunterladen und das PWG-Modell in das Verzeichnis "Vocoder" einstellen.
FCL-TACO2-T-Bewertung:
./inference_teacher.sh
FCL-TACO2-S-Bewertung:
./inference_student.sh
Wenn der Code in Ihrer Recherche verwendet wird, spielen Sie bitte unser Repo und zitieren Sie unser Papier:
@inproceedings{wang2021fcl,
title={Fcl-Taco2: Towards Fast, Controllable and Lightweight Text-to-Speech Synthesis},
author={Wang, Disong and Deng, Liqun and Zhang, Yang and Zheng, Nianzu and Yeung, Yu Ting and Chen, Xiao and Liu, Xunying and Meng, Helen},
booktitle={ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={5714--5718},
year={2021},
organization={IEEE}
}


