FCL taco2
1.0.0
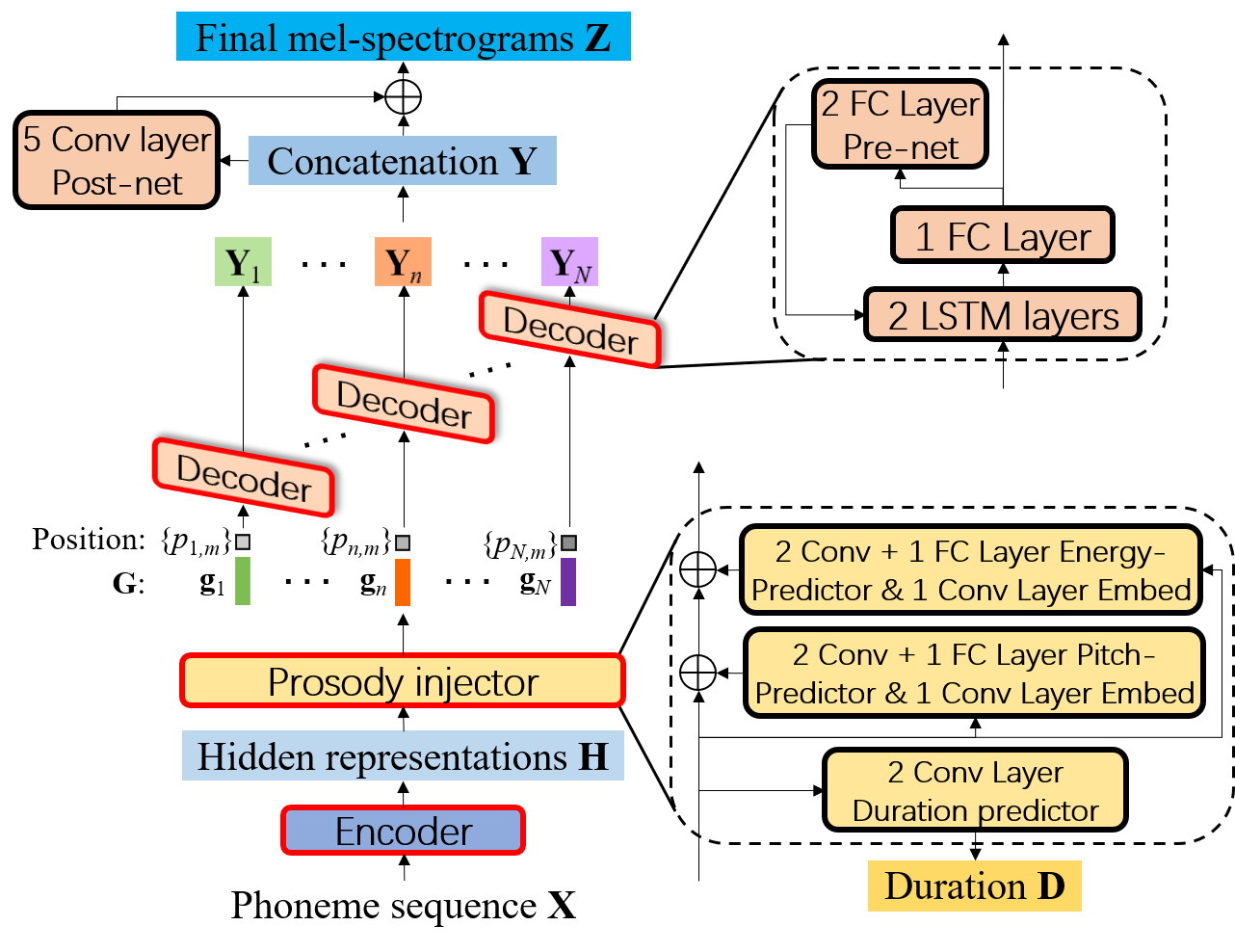
Diagramme de blocs de FCL-TACO2, où le décodeur génère des spectrogrammes de MEL en mode AR dans chaque phonème et est partagé pour tous les phonèmes.
Télécharger LJSpeech
Déballer LJSpeech-1.1.tar.bz2 vers /xx/ljSpeech-1.1
Obtenez les informations d'alignement forcées à l'aide de l'outil d'aligneur forcé Montréal. Ou vous pouvez télécharger nos résultats d'alignement, puis le déballer sur / xx / textgrid
Prétraitez l'ensemble de données pour extraire les spectrogrammes de MEL, la durée des phonèmes, la hauteur, l'énergie et la séquence de phonèmes par:
python preprocessing.py --data-root /xx/LJSpeech-1.1 --textgrid-root /xx/TextGrid
Modèle de professeur de formation FCL-TACO2-T:
./teacher_model_training.sh
Formation du modèle étudiant FCL-TACO2-S:
./student_model_training.sh
Formation de vocodeur parallèle-Wavegan: Suivez les instructions ici. Vous pouvez également télécharger le Vocoder PWG pré-formé et mettre le modèle PWG sous le répertoire "Vocoder".
Évaluation FCL-TACO2-T:
./inference_teacher.sh
Évaluation FCL-TACO2-S:
./inference_student.sh
Si le code est utilisé dans vos recherches, veuillez jouer notre dépôt et citer notre article:
@inproceedings{wang2021fcl,
title={Fcl-Taco2: Towards Fast, Controllable and Lightweight Text-to-Speech Synthesis},
author={Wang, Disong and Deng, Liqun and Zhang, Yang and Zheng, Nianzu and Yeung, Yu Ting and Chen, Xiao and Liu, Xunying and Meng, Helen},
booktitle={ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={5714--5718},
year={2021},
organization={IEEE}
}


