FCL taco2
1.0.0
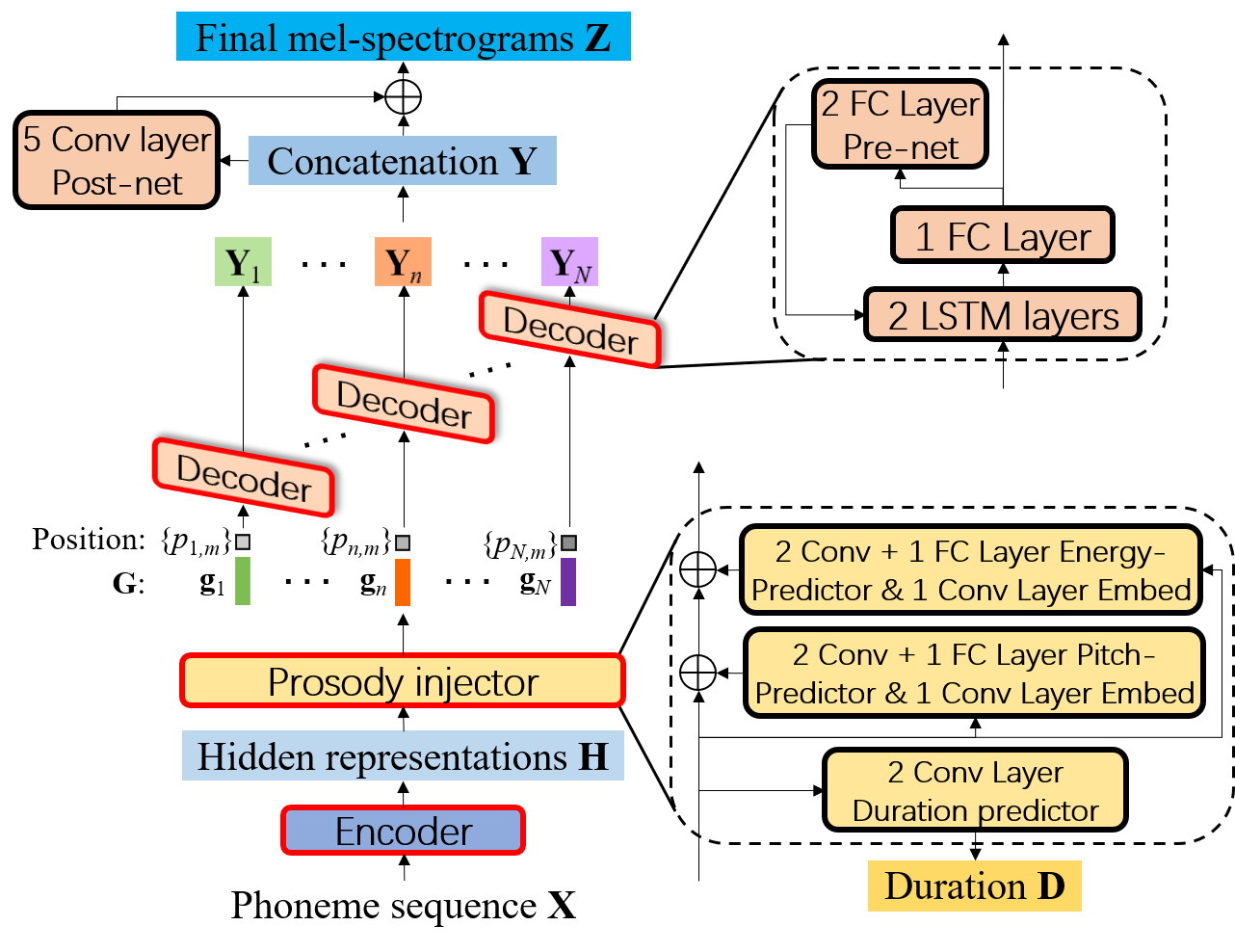
مخطط كتلة FCL-TACO2 ، حيث يقوم وحدة فك الترميز بإنشاء طيف الميل في وضع AR داخل كل صوت ويتم مشاركته لجميع الصوتيات.
تحميل ljspeech
إلغاء تنزيل ljspeech -1.1.tar.bz2 to /xx/ljspeech-1.1
الحصول على معلومات المحاذاة القسرية باستخدام أداة maligner القسرية Montreal. أو يمكنك تنزيل نتائج المحاذاة الخاصة بنا ، ثم قم بفكها على /xx /textgrid
المعالجة المسبقة لمجموعة البيانات لاستخراج طيف الميل ، ومدة الصوت ، والملعب ، والطاقة والتسلسل الصوتي بواسطة:
python preprocessing.py --data-root /xx/LJSpeech-1.1 --textgrid-root /xx/TextGrid
نموذج تدريب نموذج FCL-TACO2-T:
./teacher_model_training.sh
نموذج تدريب طالب FCL-TACO2-S:
./student_model_training.sh
تدريب المفرطات الموازي Wavegan: اتبع التعليمات هنا. يمكنك أيضًا تنزيل VOCODER PWG المدربين مسبقًا ، ووضع نموذج PWG ضمن الدليل "Vocoder".
تقييم FCL-TACO2-T:
./inference_teacher.sh
تقييم FCL-TACO2-S:
./inference_student.sh
إذا تم استخدام الرمز في بحثك ، فيرجى قيامه بدور ريبونا واستشهاد ورقتنا:
@inproceedings{wang2021fcl,
title={Fcl-Taco2: Towards Fast, Controllable and Lightweight Text-to-Speech Synthesis},
author={Wang, Disong and Deng, Liqun and Zhang, Yang and Zheng, Nianzu and Yeung, Yu Ting and Chen, Xiao and Liu, Xunying and Meng, Helen},
booktitle={ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={5714--5718},
year={2021},
organization={IEEE}
}


