FCL taco2
1.0.0
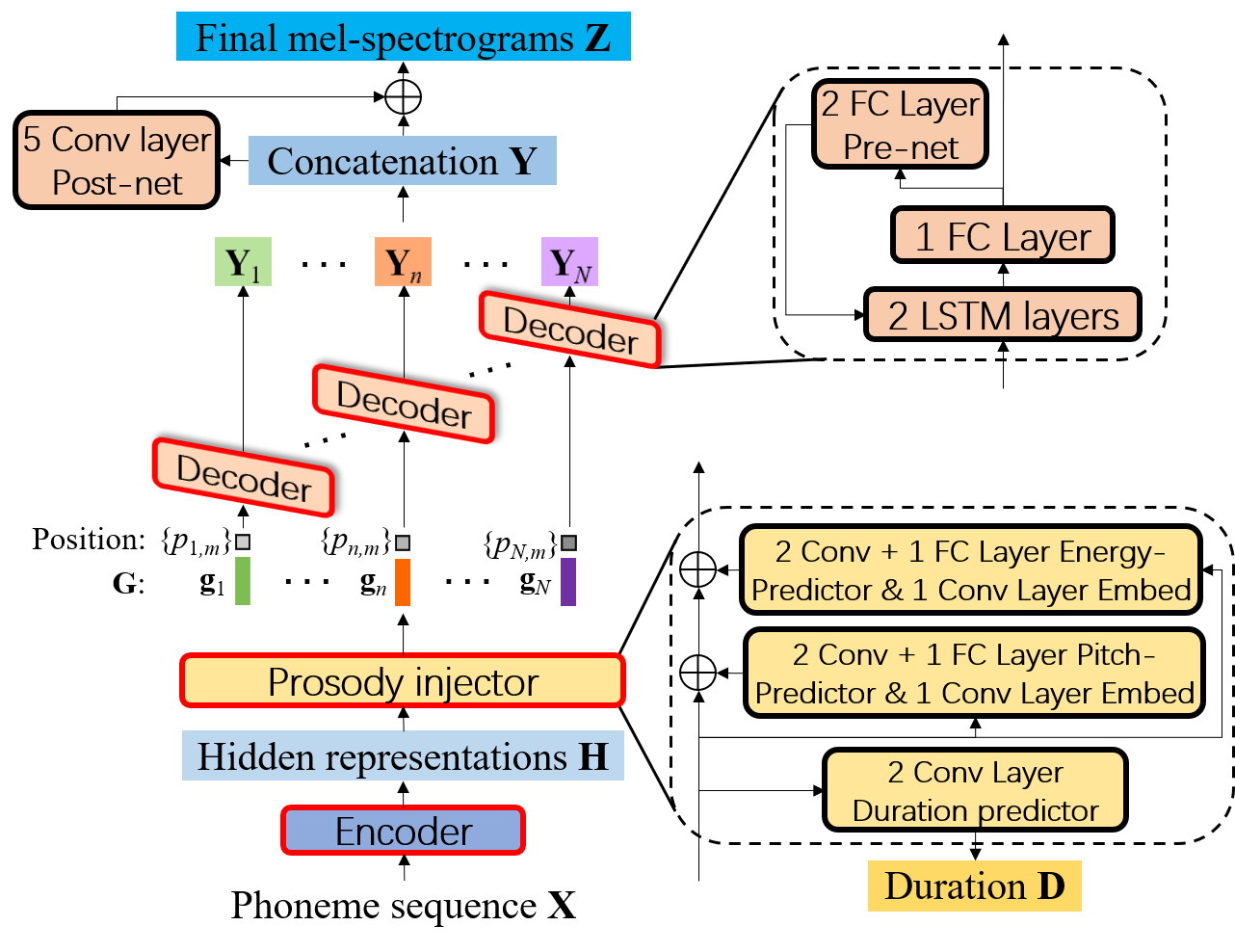
Diagrama de bloques de Fcl-Taco2, donde el decodificador genera espectrogramas MEL en modo AR dentro de cada fonema y se comparte para todos los fonemas.
Descargar ljspeech
Descargar descargado ljspeech-1.1.tar.bz2 a /xx/ljspeech-1.1
Obtenga la información de alineación forzada utilizando la herramienta de alineador forzado de Montreal. O puede descargar nuestros resultados de alineación, luego desempaquetelo a /xx /textgrid
Preprocese el conjunto de datos para extraer espectrogramas MEL, duración del fonema, tono, energía y secuencia de fonemas por:
python preprocessing.py --data-root /xx/LJSpeech-1.1 --textgrid-root /xx/TextGrid
Modelo de maestro de capacitación FCL-Taco2-T:
./teacher_model_training.sh
Capacitación de estudiantes modelo FCL-Taco2-S:
./student_model_training.sh
Entrenamiento de Vocoder de Wavegan Parallel: siga las instrucciones aquí. También puede descargar el Vocoder PWG previamente capacitado y colocar el modelo PWG en el directorio "Vocoder".
Evaluación FCL-Taco2-T:
./inference_teacher.sh
Evaluación FCL-Taco2-S:
./inference_student.sh
Si el código se usa en su investigación, establezca nuestro repositorio y cita nuestro documento:
@inproceedings{wang2021fcl,
title={Fcl-Taco2: Towards Fast, Controllable and Lightweight Text-to-Speech Synthesis},
author={Wang, Disong and Deng, Liqun and Zhang, Yang and Zheng, Nianzu and Yeung, Yu Ting and Chen, Xiao and Liu, Xunying and Meng, Helen},
booktitle={ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={5714--5718},
year={2021},
organization={IEEE}
}


