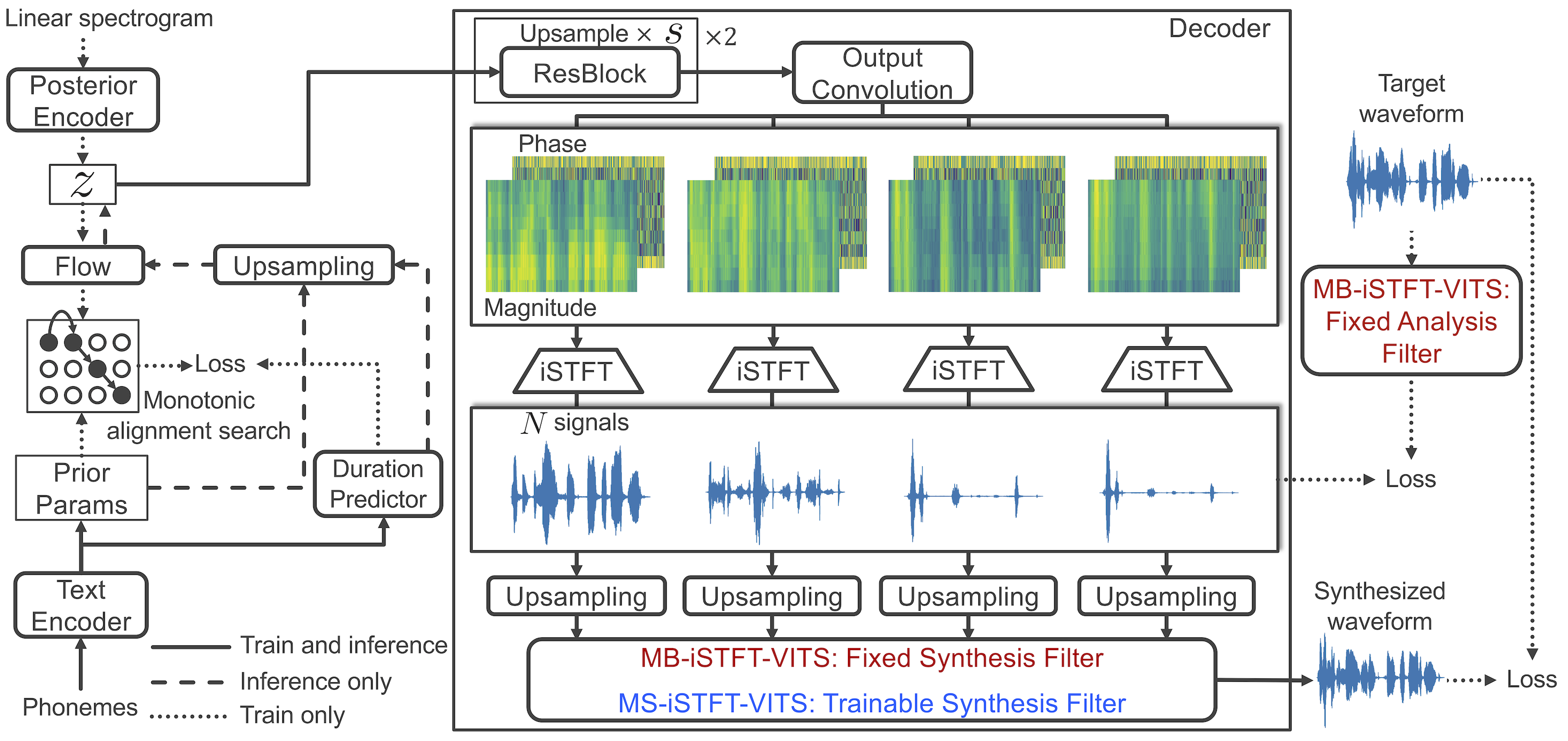
MB iSTFT VITS with AutoVocoder
1.0.0
A partir de Vits, o MB-ISTFT-VITS melhora a velocidade de síntese usando as técnicas abaixo:
Com base nessa estrutura bem projetada, esse repositório visa melhorar ainda mais a qualidade do som e a velocidade de inferência com o Autovocoder.
Este repositório é baseado em mb-istft-vits, e as modificações e aprimoramentos esperados estão abaixo:
1. Substitua o decodificador baseado em ISTFTNET pelo decodificador baseado em autovocodificador.
2. Na operação ISTFT, use componentes reais/imaginários em vez de fase/magnitude para construir espectrograma complexo. Adicione perda de reconstrução no domínio do tempo.
3. Revise o codificador posterior para aceitar 4 componentes complexos em vez de espectrograma linear.
(1024, 256, 1024) FFT/HOP/WIN sem módulos UPSMPling. (Stargy de várias bandas será mantido)Mod 3. , Ao fornecer informações de fase aos latentes, testamos se o anterior pode aproxer com segurança esses latentes. Disclaimer : This repo is built for testing purpose. Performance is not guaranteed. Welcome your contributions.
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1 # Cython-version Monotonoic Alignment Search
cd monotonic_align
mkdir monotonic_align
python setup.py build_ext --inplaceNo caso do treinamento MB-ISTFT-VITS, execute o seguinte script
python train_latest.py -c configs/ljs_mb_istft_vits.json -m ljs_mb_istft_vits
Após o treinamento, você pode verificar o áudio de inferência usando inference.ipynb


