MB iSTFT VITS with AutoVocoder
1.0.0
Ausgehend von Vits verbessert MB-ISTFT-Vits die Synthesegeschwindigkeit unter Verwendung der folgenden Techniken:
Basierend auf diesem gut gestalteten Framework zielt dieses Repository darauf ab, die Klangqualität und Inferenzgeschwindigkeit mit Autovocoder weiter zu verbessern.
Dieses Repo basiert auf MB-ISTFT-Vits, und die erwarteten Modifikationen und Verbesserungen finden Sie unten:
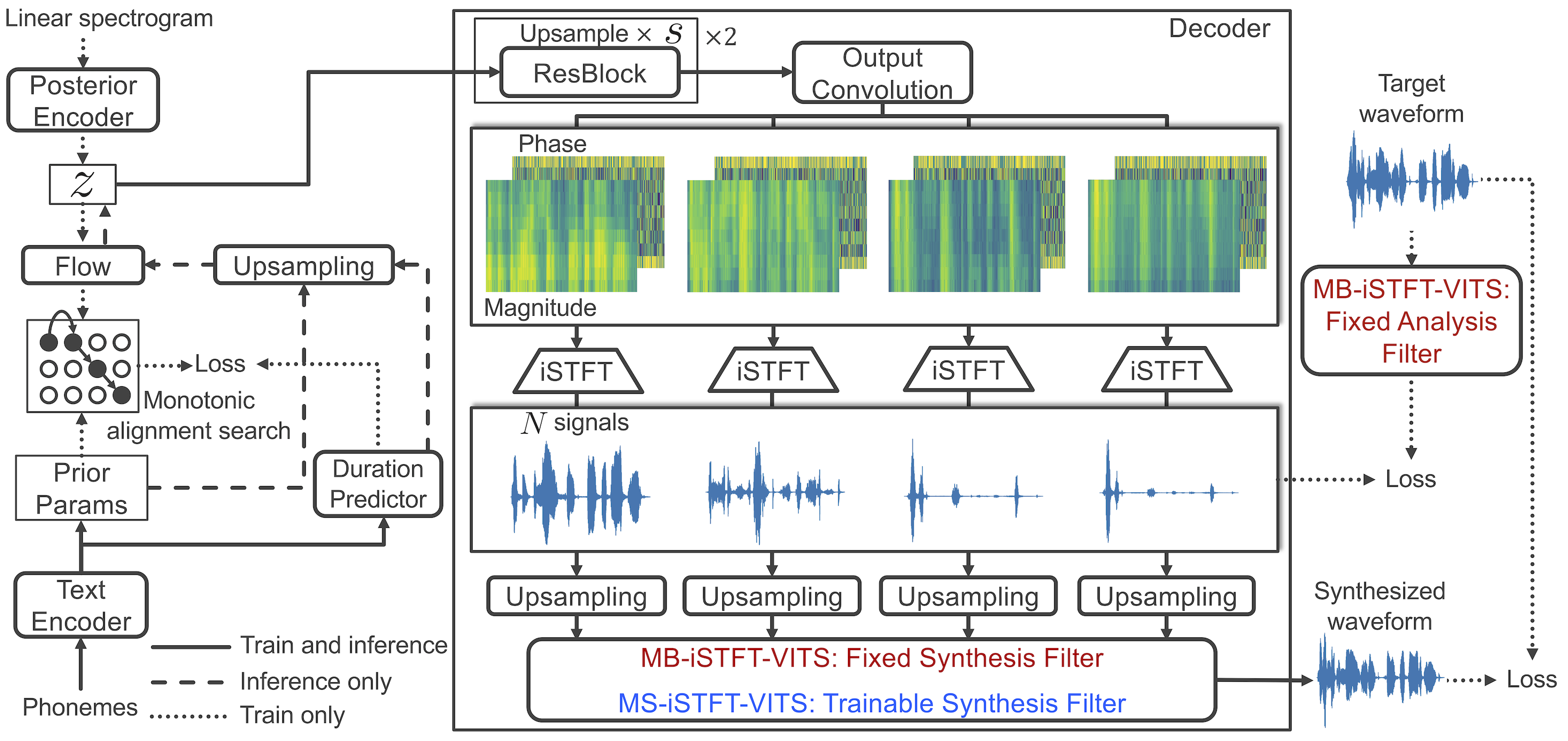
1. Ersetzen Sie den ISTFTNET-basierten Decoder in autovokoderbasierten Decoder.
2. Verwenden Sie im ISTFT -Betrieb real/imaginär anstelle von Phasen-/Größenkomponenten, um ein komplexes Spektrogramm zu konstruieren. Fügen Sie Zeitdomänenrekonstruktionsverlust hinzu.
1. Überarbeiten Sie den hinteren Encoder, um 4 komplexe Komponenten anstelle des linearen Spektrogramms zu akzeptieren.
(1024, 256, 1024) FFT/Hop/Win -Größe (1024, 256, 1024) erzeugt wird, ohne dass upsmpling -Module. (Multi-Band-Startegy wird beibehalten)Mod 3. Durch die Bereitstellung von Phaseninformationen für Latents testen wir, ob zuvor vorhanden diese Latenten zuverlässig sind. Disclaimer : This repo is built for testing purpose. Performance is not guaranteed. Welcome your contributions.
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1 # Cython-version Monotonoic Alignment Search
cd monotonic_align
mkdir monotonic_align
python setup.py build_ext --inplaceFühren Sie im Fall von MB-ISTFT-Vits-Training das folgende Skript aus
python train_latest.py -c configs/ljs_mb_istft_vits.json -m ljs_mb_istft_vits
Nach dem Training können Sie Inferenz -Audio mit Inference.ipynb überprüfen


