MB iSTFT VITS with AutoVocoder
1.0.0
Mulai dari VITS, MB-ISTFT-VIT meningkatkan kecepatan sintesis menggunakan teknik di bawah ini:
Berdasarkan kerangka kerja yang dirancang dengan baik ini, repositori ini bertujuan untuk lebih meningkatkan kualitas suara dan kecepatan inferensi dengan autovocoder.
Repo ini didasarkan pada MB-istft-vits, dan modifikasi dan peningkatan yang diharapkan di bawah ini:
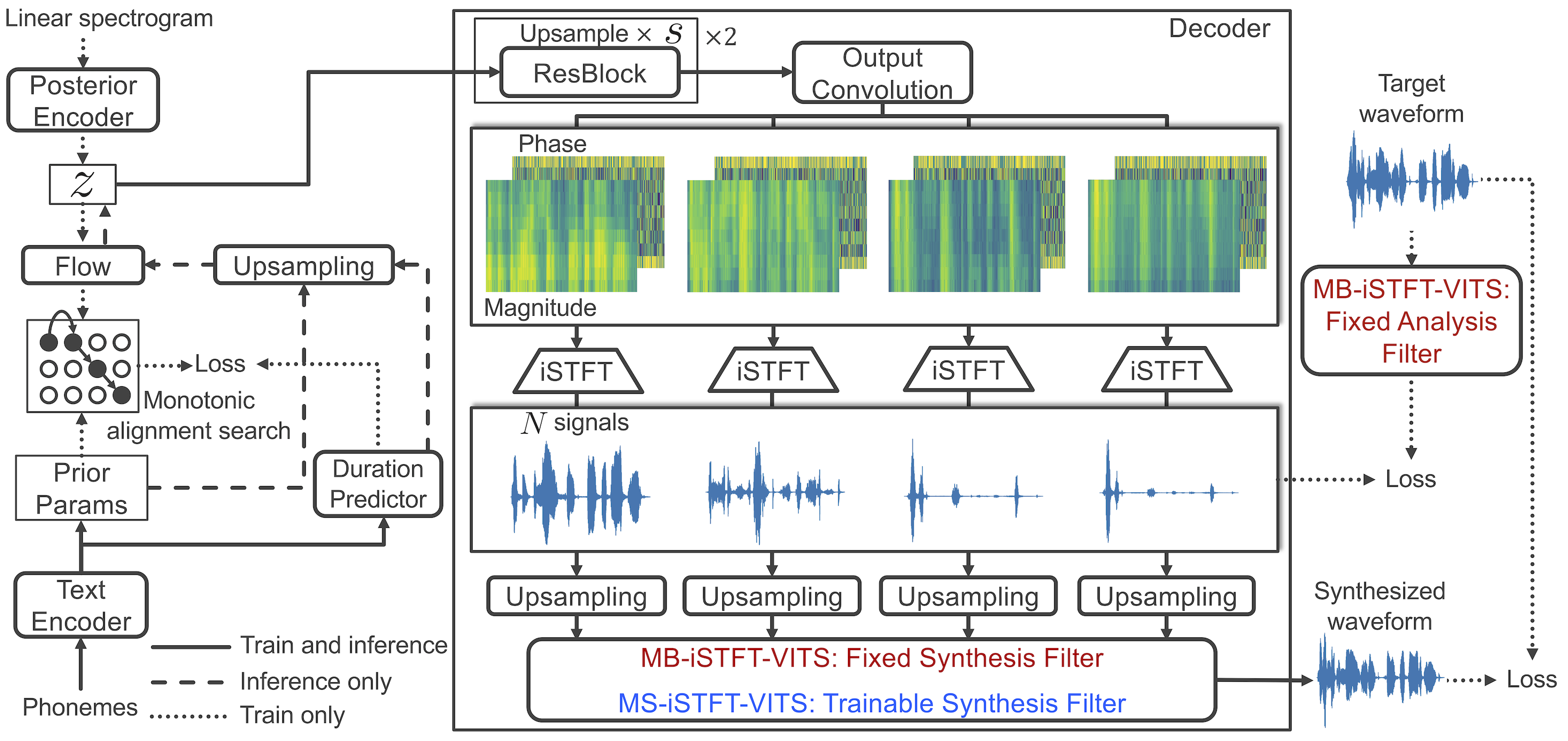
1. Ganti decoder berbasis ISTFTNET ke dekoder berbasis autovocoder.
2. Dalam operasi ISTFT, gunakan komponen fase/magnitudo yang nyata/imajiner untuk membangun spektrogram yang kompleks. Tambahkan kehilangan rekonstruksi waktu-domain.
3. Revisi enkoder posterior untuk menerima 4 komponen kompleks alih -alih spektrogram linier.
(1024, 256, 1024) ukuran FFT/hop/win tanpa modul Upsmpling. (Startegy multi-band akan dipertahankan)Mod 3. , Dengan memberikan informasi fase kepada laten, kami menguji apakah sebelumnya dapat dengan andal mendekati laten ini. Disclaimer : This repo is built for testing purpose. Performance is not guaranteed. Welcome your contributions.
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1 # Cython-version Monotonoic Alignment Search
cd monotonic_align
mkdir monotonic_align
python setup.py build_ext --inplaceDalam kasus pelatihan MB-istft-vits, jalankan skrip berikut
python train_latest.py -c configs/ljs_mb_istft_vits.json -m ljs_mb_istft_vits
Setelah pelatihan, Anda dapat memeriksa audio inferensi menggunakan inferensi.ipynb


