MB iSTFT VITS with AutoVocoder
1.0.0
À partir de VITS, MB-Istft-Vits améliore la vitesse de synthèse en utilisant des techniques ci-dessous:
Sur la base de ce cadre bien conçu, ce référentiel vise à améliorer encore la qualité sonore et la vitesse d'inférence avec AutoVoCoder.
Ce repo est basé sur MB-Istft-Vits, et les modifications et améliorations attendues sont ci-dessous:
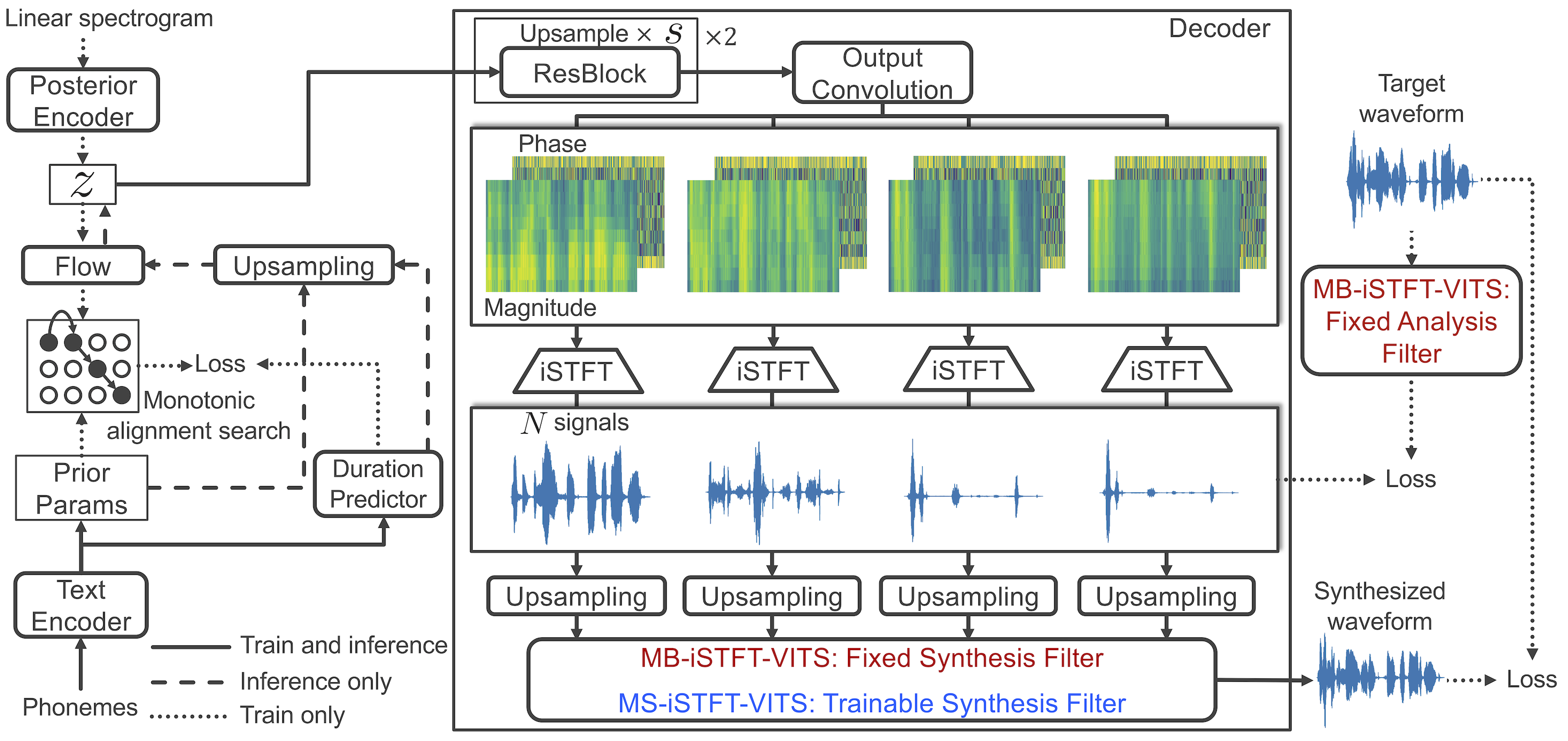
1. Remplacez le décodeur basé sur ISTFTNET au décodeur basé sur AutoVoDer.
2. Dans l'opération ISTFT, utilisez des composants réels / imaginaires au lieu de phase / magnitude pour construire un spectrogramme complexe. Ajoutez une perte de reconstruction du domaine temporel.
3. Révisez le codeur postérieur pour accepter 4 composants complexes au lieu du spectrogramme linéaire.
(1024, 256, 1024) FFT / HOP / WIN SIZE sans modules UPSmpling. (La startegy multi-bandes sera maintenue)Mod 3. , En fournissant des informations de phase à destentes, nous testons si Prior peut se rapprocher de ces derniers. Disclaimer : This repo is built for testing purpose. Performance is not guaranteed. Welcome your contributions.
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1 # Cython-version Monotonoic Alignment Search
cd monotonic_align
mkdir monotonic_align
python setup.py build_ext --inplaceDans le cas de la formation MB-Istft-Vits, exécutez le script suivant
python train_latest.py -c configs/ljs_mb_istft_vits.json -m ljs_mb_istft_vits
Après la formation, vous pouvez vérifier l'audio Inference en utilisant Inference.Ipynb


