MB iSTFT VITS with AutoVocoder
1.0.0
Starting from VITS, MB-iSTFT-VITS improves the synthesis speed using below techniques:
Based on this well-designed framework, this repository aims to further improve sound quality and inference speed with Autovocoder.
This repo is based on MB-iSTFT-VITS, and the expected modifications and enhancements are below:
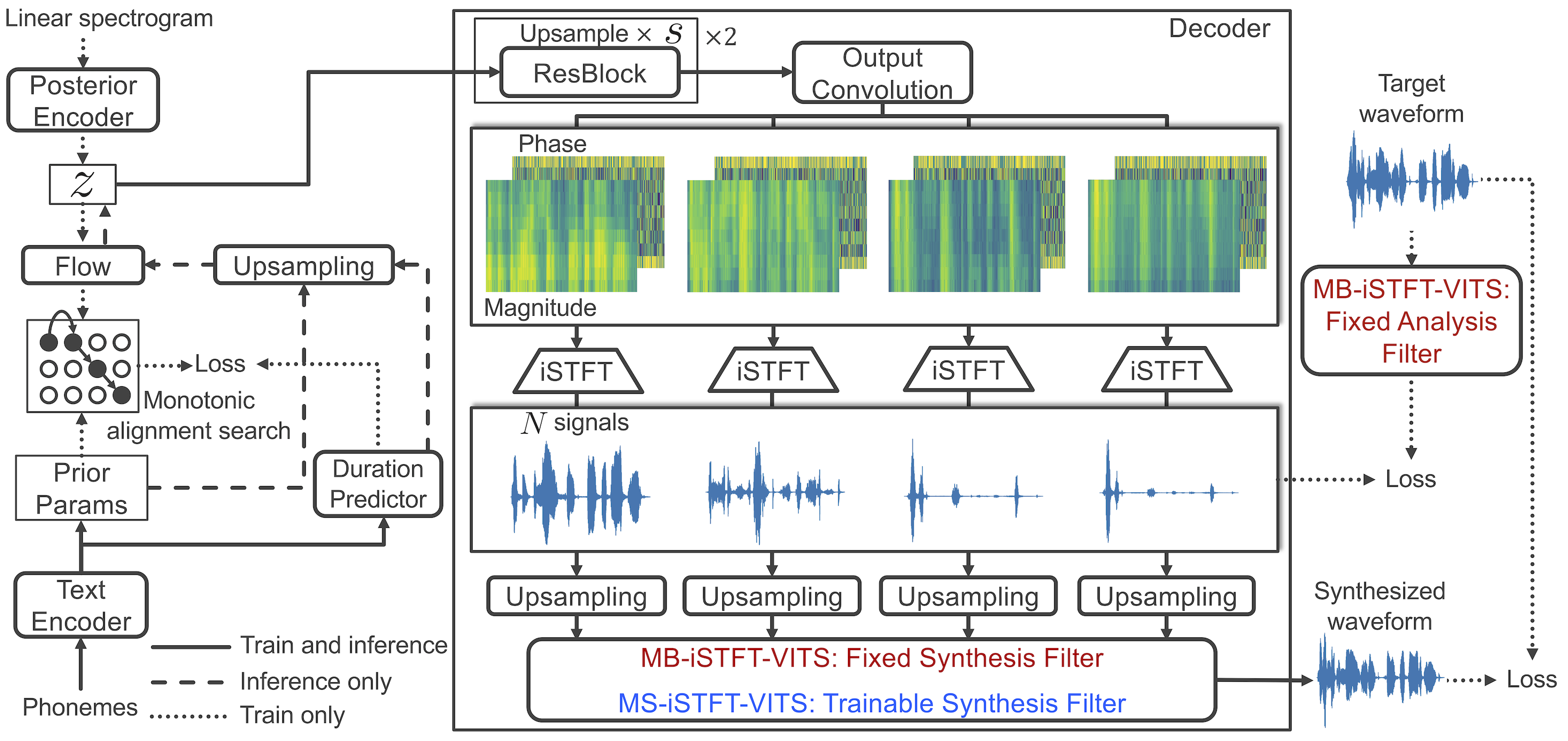
1. Replace the iSTFTNet-based decoder to AutoVocoder-based decoder.
2. In iSTFT operation, use Real/Imaginary instead of Phase/Magnitude components to construct complex spectrogram. Add time-domain reconstruction loss.
3. Revise the posterior encoder to accept 4 complex components instead of linear spectrogram.
(1024, 256, 1024) fft/hop/win size without upsmpling modules. (Multi-band startegy will be maintained)Mod 3., by providing phase information to latents, we test whether prior can reliably approx these latents.Disclaimer : This repo is built for testing purpose. Performance is not guaranteed. Welcome your contributions.
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1# Cython-version Monotonoic Alignment Search
cd monotonic_align
mkdir monotonic_align
python setup.py build_ext --inplaceIn the case of MB-iSTFT-VITS training, run the following script
python train_latest.py -c configs/ljs_mb_istft_vits.json -m ljs_mb_istft_vits
After the training, you can check inference audio using inference.ipynb


