Arquitetura limpa em Next.js
Este repo é um exemplo de como alcançar a arquitetura limpa em Next.JS. Há um tutorial em vídeo que passa por este projeto. Clique na imagem para conferir no YouTube:
Você pode executar o projeto apenas executando npm install e npm run dev .
Arquitetura limpa
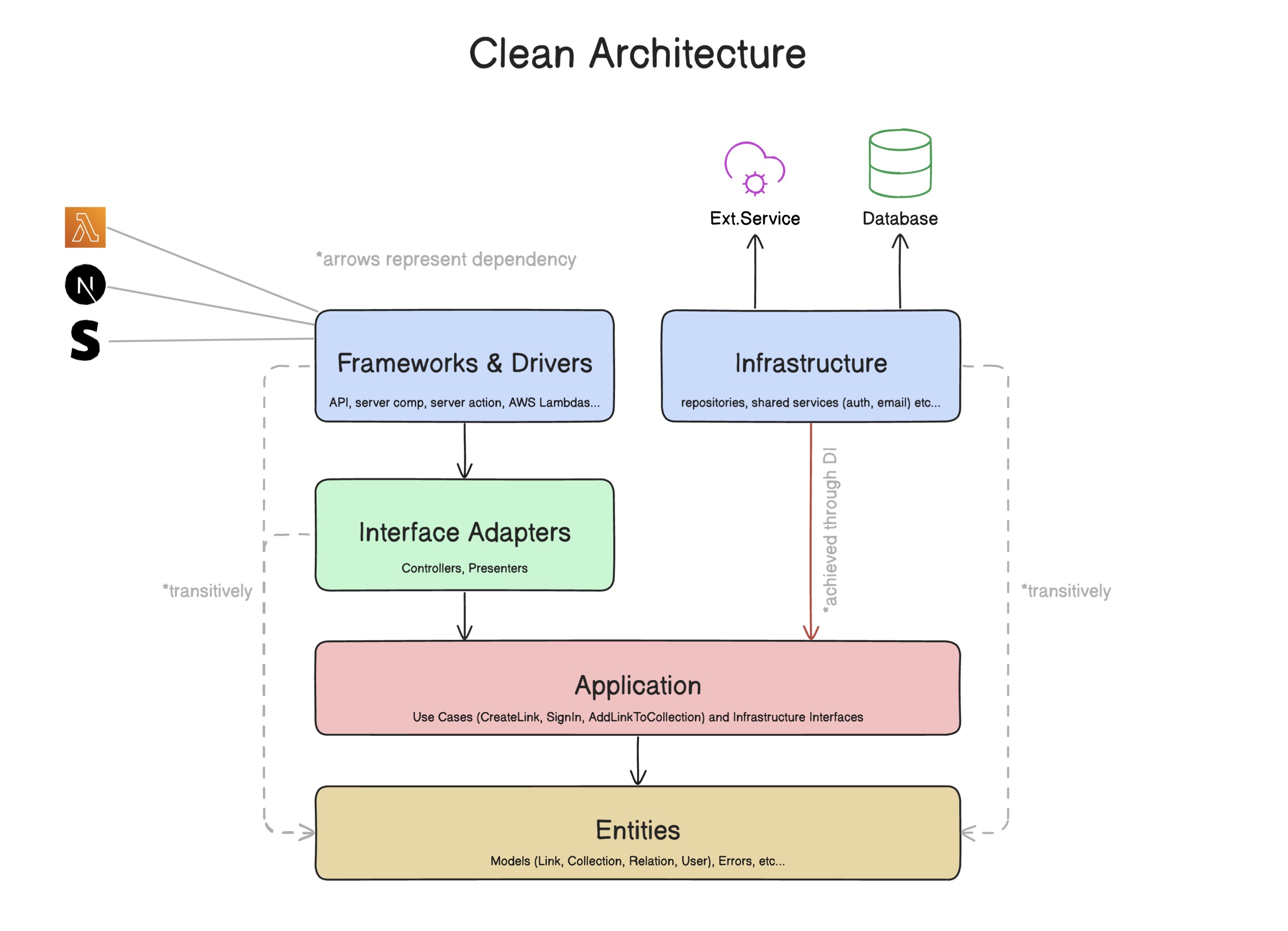
Observação
? Eu desenhei esta versão simplificada do diagrama de arquitetura limpo original. Eu simplifiquei de uma maneira que faça mais sentido para mim e é mais fácil de compreender. Espero que isso ajude você também.
Eu recomendo fortemente que você leia o artigo original do tio Bob, se esta é a primeira vez que você ouve sobre a arquitetura limpa, mas tentarei resumir para você abaixo.
A arquitetura limpa é um conjunto de regras que nos ajudam a estruturar nossos aplicativos de tal maneira que são mais fáceis de manter e testar, e suas bases de código são previsíveis. É como uma linguagem comum que os desenvolvedores entendem, independentemente de seus antecedentes técnicos e preferências de linguagem de programação.
Arquitetura limpa e arquiteturas similares/derivadas, todas têm o mesmo objetivo - separação de preocupações . Eles apresentam camadas que agrupam código semelhante. A "camada" nos ajuda a alcançar aspectos importantes em nossa base de código:
- Independente da interface do usuário - A lógica de negócios não é acoplada à estrutura da interface do usuário que está sendo usada (neste caso a seguir). O mesmo sistema pode ser usado em um aplicativo da CLI, sem precisar alterar a lógica ou regras de negócios.
- Independente do banco de dados - a implementação/operações do banco de dados é isolada em sua própria camada; portanto, o restante do aplicativo não se importa com qual banco de dados está sendo usado, mas se comunica usando modelos .
- Independente das estruturas - as regras de negócios e a lógica simplesmente não sabem nada sobre o mundo exterior. Eles recebem dados definidos com JavaScript simples, usam javascript, serviços e repositórios simples para definir sua própria lógica e funcionalidade. Isso nos permite usar estruturas como ferramentas, em vez de ter que "moldar" nosso sistema em suas implementações e limitações. Se usarmos manipuladores de rotas em nosso aplicativo e desejar refatorar alguns deles às ações do servidor, tudo o que precisamos fazer é apenas invocar os controladores específicos em uma ação do servidor em vez de um manipulador de rota, mas a lógica principal de negócios permanece inalterada.
- Testável - A lógica e as regras de negócios podem ser facilmente testadas, pois não depende da estrutura da interface do usuário, do banco de dados, ou do servidor da Web ou de qualquer outro elemento externo que construa nosso sistema.
A arquitetura limpa alcança isso através da definição de uma hierarquia de dependência - as camadas dependem apenas de camadas abaixo delas , mas não acima.
Estrutura do projeto (apenas os bits importantes)
-
app - Frameworks & Drivers Cayer - Basicamente tudo a seguir. -
di - Injeção de dependência - uma pasta onde configuramos o contêiner DI e os módulos -
drizzle - tudo db - inicializando o cliente do banco -
src - a "raiz" do sistema-
application - Camada de aplicativos - mantém casos de uso e interfaces para repositórios e serviços -
entities - Camada de entidades - mantém modelos e erros personalizados -
infrastructure - camada de infraestrutura - mantém implementações de repositórios e serviços e puxa as interfaces do application -
interface-adapters - Adaptadores de interface Camada - mantém controladores que servem como ponto de entrada para o sistema (usado na camada de estruturas e drivers para interagir com o sistema)
-
tests - Testes de unidade vivem aqui - a estrutura da subpasta da unit corresponde src -
.eslintrc.json - onde o plug -in eslint-plugin-boundaries é definido - isso impede que você quebre a regra de dependência -
vitest.config.ts - Tome nota de como o alias @ é definido!
Explicação de camadas
- Frameworks & Drivers : mantém toda a funcionalidade da estrutura da interface do usuário e tudo o mais que interage com o sistema (por exemplo, lambdas, listras, etc.). Nesse cenário, esse é o próximo.js roteiros de rota, ações do servidor, componentes (servidor e cliente), páginas, sistema de design, etc ...
- Essa camada deve usar apenas controladores , modelos e erros e não deve usar casos de uso , repositórios e serviços .
- Adaptadores de interface : define controladores :
- Os controladores executam verificações de autenticação e validação de entrada antes de passar a entrada para os casos de uso específicos.
- Controladores orquestram casos de uso. Eles não implementam nenhuma lógica, mas definem todas as operações usando casos de uso.
- Erros de camadas mais profundos são borbulhados e tratados onde os controladores estão sendo usados.
- Os controladores usam os apresentadores para converter os dados em um formato amigável à UI antes de retorná-los ao "consumidor". Isso nos ajuda a enviar menos JavaScript para o cliente (lógica e bibliotecas para converter os dados), ajuda a evitar vazar propriedades sensíveis, como e -mails ou senhas de hash e também nos ajuda a diminuir a quantidade de dados que estamos enviando de volta ao cliente.
- Aplicação : onde a lógica de negócios mora. Às vezes chamado núcleo . Essa camada define os casos de uso e interfaces para os serviços e repositórios.
- Casos de uso :
- Represente operações individuais, como "Criar TODO" ou "Entrar" ou "alternar TODO".
- Aceite entrada pré-validada (de controladores) e lidera verificações de autorização .
- Use repositórios e serviços para acessar fontes de dados e se comunicar com sistemas externos.
- Os casos de uso não devem usar outros casos de uso . Isso é um cheiro de código. Isso significa que o caso de uso faz várias coisas e deve ser dividido em vários casos de uso.
- Interfaces para repositórios e serviços:
- Eles são definidos nessa camada, porque queremos quebrar a dependência de suas ferramentas e estruturas (drivers de banco de dados, serviços de email etc.), então os implementamos na camada de infraestrutura .
- Como as interfaces vivem nessa camada, os casos de uso (e as camadas superiores transitivas) podem acessá -las através da injeção de dependência .
- A injeção de dependência nos permite dividir as definições (interfaces) das implementações (classes) e mantê -las em uma camada separada (infraestrutura), mas ainda permitem seu uso.
- Entidades : onde os modelos e erros são definidos.
- Modelos :
- Defina as formas de dados de "domínio" com JavaScript simples, sem usar tecnologias de "banco de dados".
- Os modelos nem sempre estão vinculados ao banco de dados - o envio de e -mails exige um serviço de email externo, não um banco de dados, mas ainda precisamos ter uma forma de dados que ajude outras camadas a comunicar "enviando um email".
- Os modelos também definem suas próprias regras de validação, que são chamadas de "regras de negócios corporativas". Regras que geralmente não mudam, ou são menos propensas a mudar quando algo muda externa (navegação por página, segurança, etc ...). Um exemplo é um modelo
User que define um campo de nome de usuário que deve ter pelo menos 6 caracteres e não incluir caracteres especiais .
- Erros :
- Queremos nossos próprios erros, porque não queremos borbulhar erros específicos do banco de dados ou qualquer tipo de erro específico para uma biblioteca ou estrutura.
-
catch erros provenientes de outras bibliotecas (por exemplo, garoa) e convertemos esses erros em nossos próprios erros. - É assim que podemos manter nosso núcleo independente de qualquer estrutura, bibliotecas e tecnologias - um dos aspectos mais importantes da arquitetura limpa.
- Infraestrutura : onde repositórios e serviços estão sendo definidos.
- Essa camada puxa as interfaces de repositórios e serviços da camada de aplicativos e os implementa em suas próprias classes.
- Os repositórios são como implementamos as operações do banco de dados. São classes que expõem métodos que executam uma única operação de banco de dados - como
getTodo , ou createTodo ou updateTodo . Isso significa que usamos apenas a biblioteca / driver do banco de dados nessas classes. Eles não executam nenhuma validação de dados, apenas executam consultas e mutações no banco de dados e lançam nossos erros definidos personalizados ou retornam resultados. - Os serviços são serviços compartilhados que estão sendo usados em todo o aplicativo - como um serviço de autenticação ou serviço de email ou implementar sistemas externos como Stripe (crie pagamentos, validar recibos etc ...). Esses serviços também usam e dependem de outras estruturas e bibliotecas. É por isso que a implementação deles é mantida aqui ao lado dos repositórios.
- Como não queremos que nenhuma camada dependa desta (e dependa transitivamente do banco de dados e de todos os serviços), usamos o princípio da inversão de dependência . Isso nos permite depender apenas das interfaces definidas na camada de aplicativos , em vez das implementações na camada de infraestrutura . Utilizamos uma inversão da biblioteca de controle como o ioctopus para abstrair a implementação por trás das interfaces e "injetar" sempre que precisamos. Criamos a abstração no diretório
di . "Ligamos" os repositórios, serviços, controladores e casos de uso para símbolos, e "resolvemos" eles usando esses símbolos quando precisamos da implementação real. É assim que podemos usar a implementação, sem precisar depender explicitamente dele (importá -lo).
Perguntas frequentes
Dica
Se você tiver uma pergunta não coberta pelas perguntas frequentes, fique à vontade para abrir um problema neste repositório ou participar do meu servidor Discord e iniciar uma conversa lá.
A arquitetura limpa / esta implementação é fácil de servidor? Posso implantar isso no vercel?
Sim! Você pode usá -lo com roteador de página, roteador de aplicativos, middleware, manipuladores de API, ações do servidor, qualquer coisa realmente! Geralmente, a obtenção de injeção de dependência em projetos JavaScript está sendo feita com a biblioteca inversify.js, que é incompatível com outros tempos de execução, exceto o nó. Este projeto implementa a IOCtopus, um recipiente simples do COI que não depende do reflect-metadata e trabalha em todos os horários de execução.
Devo começar a implementar a arquitetura limpa imediatamente quando criar meu projeto Next.js?
Eu diria não . Se você estiver iniciando um projeto novo, recomendaria que você se concentre em alcançar um status de MVP o mais rápido possível (para que você possa validar sua ideia / ver se há um futuro para o seu projeto). Quando as coisas começam a ficar sérias (mais recursos começam a ser implementados, sua base de usuários experimenta um crescimento significativo ou você está integrando outros desenvolvedores em seu projeto), é quando você deseja investir algum tempo para adaptar essa arquitetura (ou qualquer arquitetura para esse assunto).
Se você já está no fundo das ervas daninhas de um projeto, você (e sua equipe) podem planejar a refatoração gradual a partir do próximo sprint. Nesse caso, você já tem o código escrito, você só precisa reorganizá -lo um pouco e pode fazer essa parte por parte, manipulador de rota por manipulador de rota, ação do servidor por ação do servidor. A propósito, eu digo isso levemente "você só precisa reorganizá -lo um pouco" , mas pode estar longe de ser tão simples assim. Sempre leve em consideração "as coisas que dão errado" quando planejar a refatoração. E dedique algum tempo para escrever testes!
Parece demais e complica o desenvolvimento de recursos.
Se você não gasta mais de 3 minutos pensando nisso, então sim, parece excessivo. Mas se o fizer, você perceberá essa arquitetura = disciplina . A arquitetura é um contrato entre os desenvolvedores que define o que vai aonde. Na verdade, simplifica o desenvolvimento de recursos porque torna a base de código previsível e torna essas decisões para você.
Você não pode cultivar um projeto de forma sustentável se todo desenvolvedor que trabalha nele grava código onde é o mais conveniente. A base de código se transformará em um pesadelo para trabalhar, e é aí que você sentirá um processo de desenvolvimento de recursos complicado. Para combater isso, eventualmente você colocará algumas regras. Essas regras crescerão à medida que sua equipe enfrenta e resolve novos problemas. Coloque todas essas regras em um documento e existe sua própria definição de arquitetura. Você ainda implementa algum tipo de arquitetura, chegou a esse ponto de lenta e dolorosamente.
A arquitetura limpa oferece um atalho e uma arquitetura predefinida que foi testada. E sim, claro, você precisa aprender tudo isso, mas faz isso uma vez na sua vida e, em seguida, aplique os princípios em qualquer idioma ou estrutura que você usará no futuro.
Devo aplicar uma arquitetura limpa em todos os meus projetos?
Não . Não se você não espera que o projeto cresça, tanto no número de recursos quanto no número de usuários ou no número de desenvolvedores que trabalham nele.
O que são outras arquiteturas semelhantes à arquitetura limpa?
Como mencionado no post original do blog que mencionei no topo do ReadMe, você tem:
- Arquitetura hexagonal (também conhecida como portas e adaptadores) de Alistair Cockburn
- Arquitetura de cebola de Jeffrey Palermo
- Arquitetura gritando do tio Bob (o mesmo cara por trás da arquitetura limpa)
- E mais um par (confira a postagem original do blog)


