Arquitectura limpia en Next.js
Este repositorio es un ejemplo de cómo lograr la arquitectura limpia en Next.js. Hay un video tutorial que pasa por este proyecto. Haga clic en la imagen para verlo en YouTube:
Puede ejecutar el proyecto simplemente ejecutando npm install y npm run dev .
Arquitectura limpia
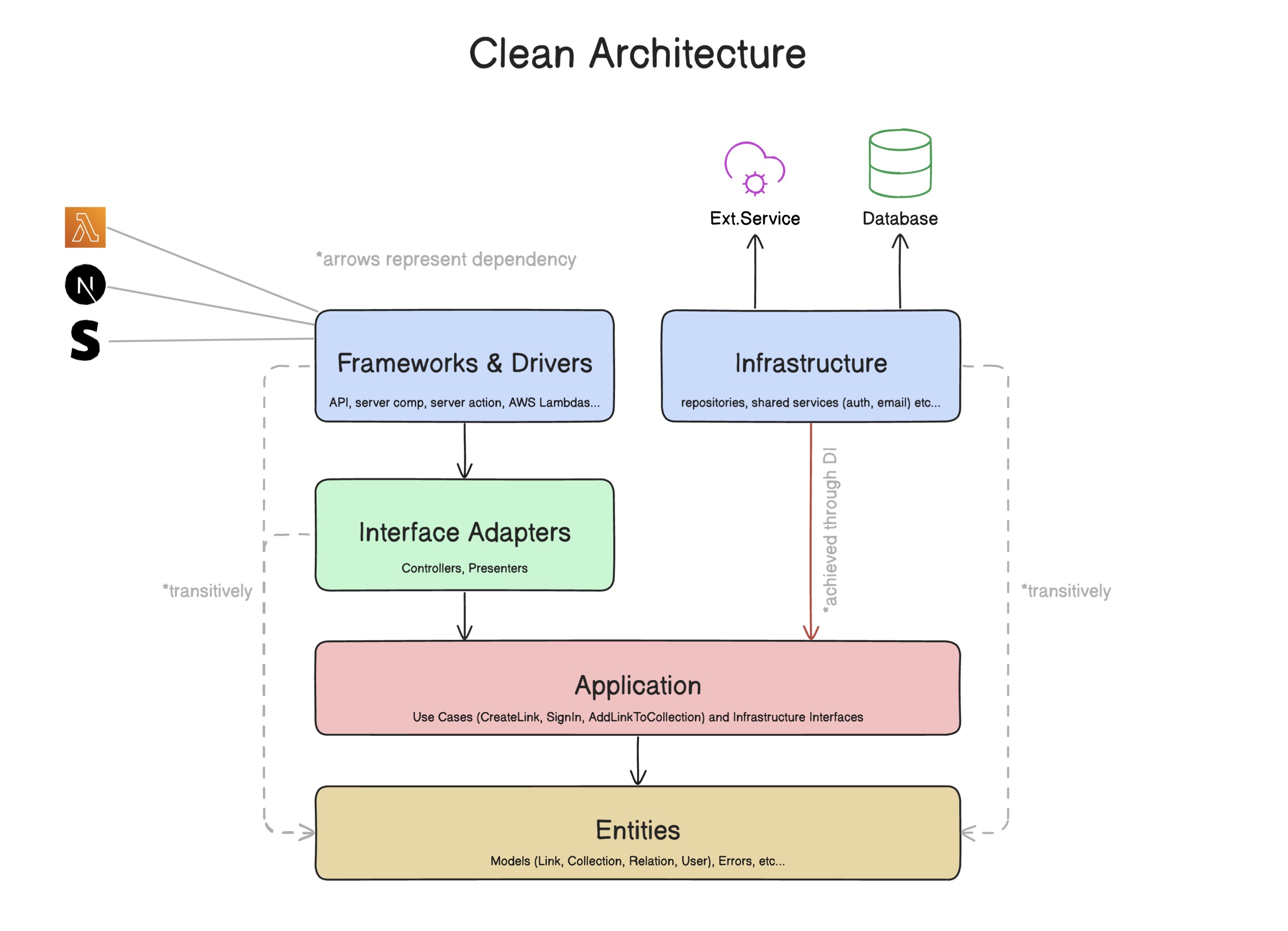
Nota
? Dibujé esta versión simplificada del diagrama original de arquitectura limpia. Lo simplifiqué de una manera que tenga más sentido para mí, y es más fácil de comprender. Espero que también te ayude.
Le recomiendo que lea el artículo original del tío Bob si esta es la primera vez que escucha sobre la arquitectura limpia, pero intentaré resumirlo a continuación.
La arquitectura limpia es un conjunto de reglas que nos ayudan a estructurar nuestras aplicaciones de tal manera que sean más fáciles de mantener y probar, y sus bases de código son predecibles. Es como un lenguaje común que los desarrolladores entienden, independientemente de sus antecedentes técnicos y sus preferencias de lenguaje de programación.
Arquitectura limpia y arquitecturas similares/derivadas, todas tienen el mismo objetivo: separación de preocupaciones . Introducen capas que agrupan un código similar. La "capas" nos ayuda a lograr aspectos importantes en nuestra base de código:
- Independiente de la interfaz de usuario : la lógica comercial no se combina con el marco de la interfaz de usuario que se está utilizando (en este caso a continuación. JS). El mismo sistema se puede utilizar en una aplicación CLI, sin tener que cambiar la lógica o reglas de negocios.
- Independientemente de la base de datos : la implementación/operaciones de la base de datos se aislan en su propia capa, por lo que al resto de la aplicación no le importa qué base de datos se utilice, pero se comunica con los modelos .
- Independiente de los marcos : las reglas y la lógica de negocios simplemente no saben nada sobre el mundo exterior. Reciben datos definidos con JavaScript simple, usan JavaScript simple, servicios y repositorios para definir su propia lógica y funcionalidad. Esto nos permite usar marcos como herramientas, en lugar de tener que "moldear" nuestro sistema en sus implementaciones y limitaciones. Si usamos manejadores de ruta en nuestra aplicación y queremos refactorizar algunos de ellos a las acciones del servidor, todo lo que necesitamos hacer es invocar los controladores específicos en una acción del servidor en lugar de un manejador de ruta, pero la lógica comercial central sigue sin cambios.
- Probable : la lógica y las reglas de negocios se pueden probar fácilmente porque no depende del marco de la interfaz de usuario, o de la base de datos, o el servidor web, o cualquier otro elemento externo que acumule nuestro sistema.
La arquitectura limpia logra esto mediante la definición de una jerarquía de dependencia : las capas dependen solo de las capas debajo de ellas , pero no arriba.
Estructura del proyecto (solo los bits importantes)
-
app - Capa de marcos y controladores : básicamente todo lo siguiente. JS (páginas, acciones del servidor, componentes, estilos, etc.) o lo que sea "consume" la lógica de la aplicación - inyección de dependencia
di : una carpeta donde configuramos el contenedor DI y los módulos -
drizzle - Everything DB - Inicialización del cliente DB, definiendo esquema, migraciones -
src - La "raíz" del sistema-
application - Capa de aplicación - contiene casos de uso e interfaces para repositorios y servicios -
entities - Capa de entidades - posee modelos y errores personalizados -
infrastructure - Capa de infraestructura - Sostiene implementaciones de repositorios y servicios, y extrae las interfaces de application -
interface-adapters : capa de adaptadores de interfaz : contiene controladores que sirven como punto de entrada al sistema (utilizado en la capa de marcos y controladores para interactuar con el sistema)
-
tests - Las pruebas unitarias viven aquí - La estructura de la subcarpeta de unit coincide con src -
.eslintrc.json - Donde se define el complemento eslint-plugin-boundaries , esto le impide romper la regla de dependencia -
vitest.config.ts : ¡tome nota de cómo se define el alias @ !
Explicación de capas
- Frameworks y controladores : mantiene toda la funcionalidad del marco de la interfaz de usuario y todo lo demás que interactúa con el sistema (por ejemplo, AWS Lambdas, Stripe Webhooks, etc.). En este escenario, son los manejadores de ruta Next.js, acciones del servidor, componentes (servidor y cliente), páginas, sistema de diseño, etc.
- Esta capa solo debe usar controladores , modelos y errores , y no debe usar casos de uso , repositorios y servicios .
- Adaptadores de interfaz : Define los controladores :
- Los controladores realizan verificaciones de autenticación y validación de entrada antes de pasar la entrada a los casos de uso específicos.
- Los controladores orquestan los casos de uso. No implementan ninguna lógica, pero definen todas las operaciones utilizando casos de uso.
- Los errores de capas más profundas se burbujean y se manejan donde se utilizan controladores.
- Los controladores usan presentadores para convertir los datos en un formato amigable para la interfaz de usuario justo antes de devolverlos al "consumidor". Esto nos ayuda a enviar menos JavaScript al cliente (lógica y bibliotecas para convertir los datos), ayuda a evitar la fuga de propiedades confidenciales, como correos electrónicos o contraseñas de hash, y también nos ayuda a adelgazar la cantidad de datos que enviamos al cliente.
- Aplicación : Donde vive la lógica de negocios. A veces llamado núcleo . Esta capa define los casos de uso e interfaces para los servicios y repositorios.
- Casos de uso :
- Representar operaciones individuales, como "Crear TODO" o "Iniciar sesión" o "TODO".
- Acepte la entrada pre-validada (de los controladores) y maneje las verificaciones de autorización .
- Utilice repositorios y servicios para acceder a fuentes de datos y comunicarse con sistemas externos.
- Los casos de uso no deben usar otros casos de uso . Ese es un olor en código. Significa que el caso de uso hace varias cosas y debe descomponerse en múltiples casos de uso.
- Interfaces para repositorios y servicios:
- Estos se definen en esta capa porque queremos romper la dependencia de sus herramientas y marcos (controladores de bases de datos, servicios de correo electrónico, etc.), por lo que los implementaremos en la capa de infraestructura .
- Dado que las interfaces viven en esta capa, los casos de uso (y transitivamente las capas superiores) pueden acceder a ellas a través de la inyección de dependencia .
- La inyección de dependencia nos permite dividir las definiciones (interfaces) de las implementaciones (clases) y mantenerlas en una capa separada (infraestructura), pero aún así permite su uso.
- Entidades : donde se definen los modelos y errores .
- Modelos :
- Definir formas de datos de "dominio" con JavaScript simple, sin usar tecnologías de "base de datos".
- Los modelos no siempre están vinculados a la base de datos: enviar correos electrónicos requiere un servicio de correo electrónico externo, no una base de datos, pero aún necesitamos tener una forma de datos que ayude a otras capas a comunicarse "enviar un correo electrónico".
- Los modelos también definen sus propias reglas de validación, que se denominan "reglas comerciales empresariales". Las reglas que generalmente no cambian o tienen menos probabilidades de cambiar cuando algo externo cambia (navegación de la página, seguridad, etc.). Un ejemplo es un modelo
User que define un campo de nombre de usuario que debe tener al menos 6 caracteres y no incluir caracteres especiales .
- Errores :
- Queremos nuestros propios errores porque no queremos burbujear errores específicos de la base de datos, o cualquier tipo de errores que sean específicos para una biblioteca o marco.
-
catch errores que provienen de otras bibliotecas (por ejemplo, llovizna) y convertimos esos errores a nuestros propios errores. - Así es como podemos mantener nuestro núcleo independiente de cualquier marcos, bibliotecas y tecnologías, uno de los aspectos más importantes de la arquitectura limpia.
- Infraestructura : donde se definen repositorios y servicios .
- Esta capa extrae las interfaces de repositorios y servicios de la capa de aplicación y los implementa en sus propias clases.
- Los repositorios son cómo implementamos las operaciones de la base de datos. Son clases que exponen métodos que realizan una operación de base de datos única, como
getTodo , createTodo , o updateTodo . Esto significa que usamos la biblioteca / controlador de la base de datos solo en estas clases. No realizan ninguna validación de datos, solo ejecutan consultas y mutaciones contra la base de datos y lanzan nuestros errores definidos personalizados o resultados de retorno. - Los servicios son servicios compartidos que se están utilizando en toda la aplicación, como un servicio de autenticación, o un servicio de correo electrónico, o implementan sistemas externos como Stripe (cree pagos, valida los recibos, etc.). Estos servicios también usan y dependen de otros marcos y bibliotecas. Es por eso que su implementación se mantiene aquí junto con los repositorios.
- Dado que no queremos que ninguna capa dependa de esta (y dependa transitivamente de la base de datos y de todos los servicios), utilizamos el principio de inversión de dependencia . Esto nos permite depender solo de las interfaces definidas en la capa de aplicación , en lugar de las implementaciones en la capa de infraestructura . Utilizamos una inversión de la biblioteca de control como Ioctopus para abstraer la implementación detrás de las interfaces y "inyectarla" cada vez que la necesitamos. Creamos la abstracción en el directorio
di . "Vinculamos" los repositorios, servicios, controladores y casos de uso a símbolos, y los "resuelvemos" utilizando esos símbolos cuando necesitamos la implementación real. Así es como podemos usar la implementación, sin necesidad de depender explícitamente de ella (importarlo).
Preguntas frecuentes
Consejo
Si tiene una pregunta que no está cubierta por las preguntas frecuentes, no dude en abrir un problema en este repositorio o unirse a mi servidor de discordias e iniciar una conversación allí.
¿Es la arquitectura limpia / este servidor de implementación sin servidor? ¿Puedo implementar esto en VERCEL?
¡Sí! Puede usarlo con el enrutador de la página, el enrutador de aplicaciones, el middleware, los manejadores de API, las acciones del servidor, ¡cualquier cosa realmente! Por lo general, el logro de la inyección de dependencia en los proyectos de JavaScript se está realizando con la biblioteca Inversify.js, que es incompatible con otros tiempos de ejecución, excepto el nodo. Este proyecto implementa Ioctopus, un contenedor de COI simple que no depende de reflect-metadata y funciona en todos los tiempos de ejecución.
¿Debo comenzar a implementar la arquitectura limpia de inmediato cuando cree mi proyecto Next.js?
Yo diría que no . Si está comenzando un proyecto nuevo, le aconsejaría que se concentre en lograr un estado de MVP lo más rápido posible (para que pueda validar su idea / ver si hay un futuro para su proyecto). Cuando las cosas comienzan a ser serias (más características comienzan a implementarse, su base de usuarios experimenta un crecimiento significativo, o está incorporando a otros desarrolladores en su proyecto), es cuando desea invertir algo de tiempo para adaptar esta arquitectura (o cualquier arquitectura).
Si ya está en las malas hierbas en un proyecto, usted (y su equipo) puede planificar la refactorización gradual a partir del siguiente sprint. En este caso, ya tiene el código escrito, solo necesita reorganizarlo un poco, y puede hacer esa parte por parte, Handler de ruta por Handler, Acción del servidor por acción del servidor. Por cierto, lo digo a la ligera "solo necesitas reorganizarlo un poco" , pero puede estar lejos de ser tan simple como eso. Siempre tenga en cuenta "las cosas que van mal" cuando planifique la refactorización. ¡Y dedique algo de tiempo a escribir pruebas!
Esto parece una generación excesiva y complica el desarrollo de características.
Si no pasa más de 3 minutos pensando en esto, entonces sí, parece una exceso de ingeniería. Pero si lo haces, te darás cuenta de que arquitectura = disciplina . La arquitectura es un contrato entre los desarrolladores que define qué va a dónde. En realidad, simplifica el desarrollo de características porque hace que la base de código sea predecible, y toma esas decisiones por usted.
No puede hacer crecer un proyecto de manera sostenible si cada desarrollador que trabaja en él escribe código donde es el más conveniente. La base de código se convertirá en una pesadilla para trabajar, y es cuando sentirá un proceso de desarrollo de características realmente complicado. Para luchar contra esto, eventualmente dejarás algunas reglas. Esas reglas crecerán a medida que su equipo se enfrente y resuelva nuevos problemas. Ponga todas esas reglas en un documento, y existe su propia definición de arquitectura. Todavía implementa algún tipo de arquitectura, solo llegó a ese punto muy lenta y dolorosamente.
La arquitectura limpia le brinda un atajo y una arquitectura predefinida que se ha probado. Y sí, claro, debe aprender todo esto, pero lo hace una vez en su vida, y luego aplica los principios en cualquier idioma o marco que usará en el futuro.
¿Debo aplicar arquitectura limpia en todos mis proyectos?
No . No si no espera que el proyecto crezca, tanto en número de características, como número de usuarios, o número de desarrolladores que trabajan en él.
¿Cuáles son otras arquitecturas similares para limpiar la arquitectura?
Como se mencionó en la publicación de blog original que mencioné en la parte superior del readme, obtuviste:
- Arquitectura hexagonal (también conocida como puertos y adaptadores) de Alistair Cockburn
- Arquitectura de cebolla de Jeffrey Palermo
- Arquitectura de gritos del tío Bob (el mismo tipo detrás de la arquitectura limpia)
- Y un par más (mira la publicación de blog original)


