Architecture propre dans Next.js
Ce repo est un exemple de la façon de réaliser une architecture propre dans Next.js. Il y a un tutoriel vidéo qui passe par ce projet. Cliquez sur l'image pour le vérifier sur YouTube:
Vous pouvez exécuter le projet simplement en exécutant npm install et npm run dev .
Architecture propre
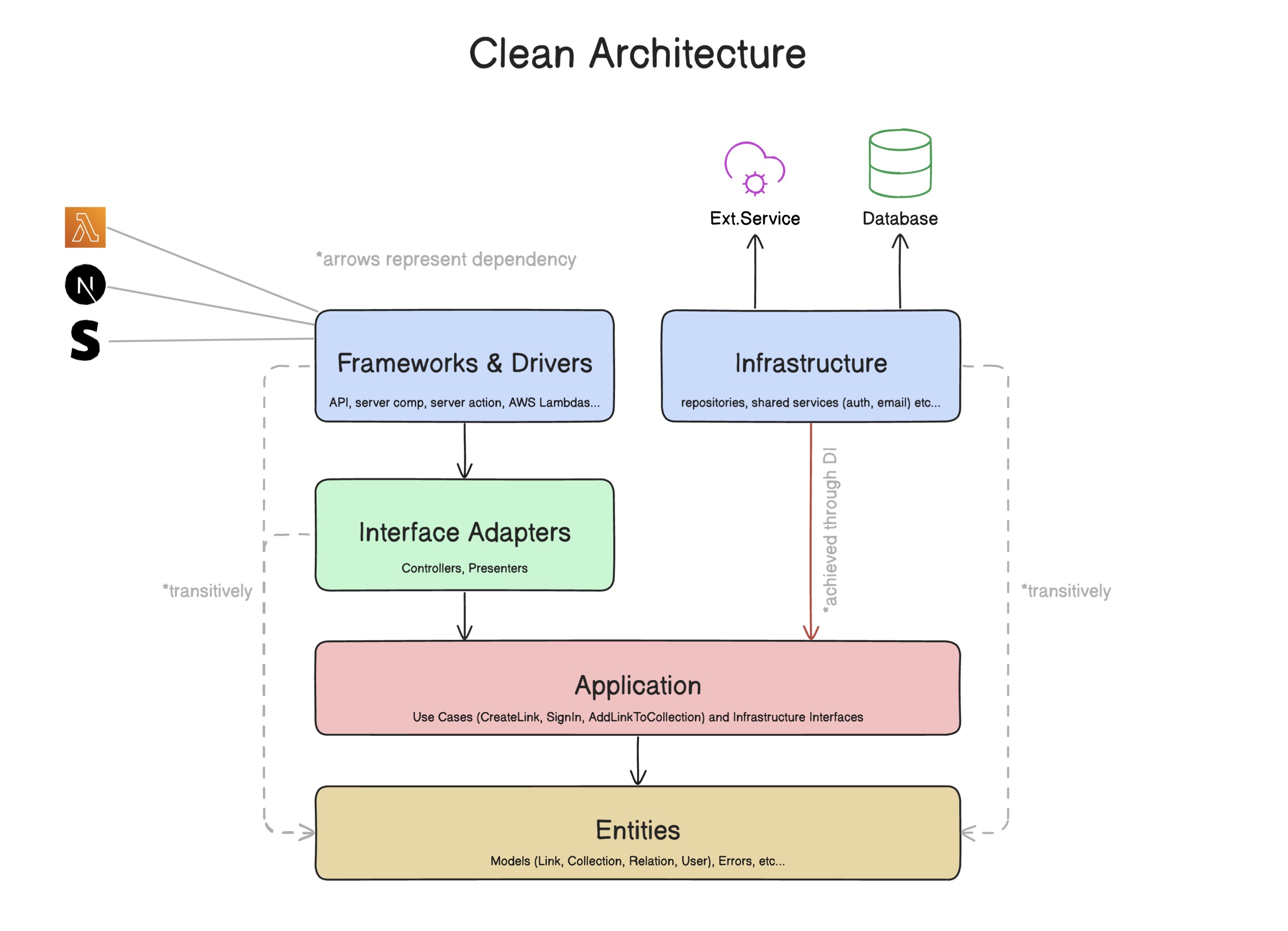
Note
? J'ai dessiné cette version simplifiée du diagramme d'architecture propre d'origine. Je l'ai simplifié d'une manière qui a plus de sens pour moi, et c'est plus facile à comprendre. J'espère que cela vous aide aussi.
Je vous recommande fortement de lire l'article original de l'oncle Bob si c'est la première fois que vous entendez parler de l'architecture propre, mais je vais essayer de le résumer pour vous ci-dessous.
L'architecture propre est un ensemble de règles qui nous aident à structurer nos applications de telle manière qu'ils sont plus faciles à entretenir et à tester, et leurs bases de code sont prévisibles. C'est comme un langage commun que les développeurs comprennent, quels que soient leurs antécédents techniques et leurs préférences de langage de programmation.
L'architecture propre et les architectures similaires / dérivées, toutes ont le même objectif - la séparation des préoccupations . Ils introduisent des couches qui regroupent le code similaire. La «superposition» nous aide à réaliser des aspects importants dans notre base de code:
- Indépendamment de l'interface utilisateur - La logique métier n'est pas associée au cadre d'interface utilisateur utilisé (dans ce cas, Next.js). Le même système peut être utilisé dans une application CLI, sans avoir à modifier la logique ou les règles commerciales.
- Indépendamment de la base de données - La mise en œuvre / opérations de la base de données est isolée dans leur propre couche, de sorte que le reste de l'application ne se soucie pas de la base de données utilisée, mais communique à l'aide de modèles .
- Indépendamment des cadres - les règles commerciales et la logique ne savent tout simplement rien du monde extérieur. Ils reçoivent des données définies avec un JavaScript simple, utilisent JavaScript simple, des services et des référentiels pour définir leur propre logique et fonctionnalité. Cela nous permet d'utiliser des cadres comme outils, au lieu d'avoir à «mouler» notre système dans leurs implémentations et limitations. Si nous utilisons des gestionnaires de routes dans notre application et que nous souhaitons refacter certaines d'entre eux dans les actions du serveur, tout ce que nous devons faire est simplement d'invoquer les contrôleurs spécifiques d'une action de serveur au lieu d'un gestionnaire de routes, mais la logique métier principale reste inchangée.
- Testable - La logique commerciale et les règles peuvent facilement être testées car elles ne dépendent pas du framework d'interface utilisateur, de la base de données ou du serveur Web, ou de tout autre élément externe qui construit notre système.
L'architecture propre y parvient en définissant une hiérarchie de dépendance - les couches ne dépendent que des couches en dessous d'eux , mais pas ci-dessus.
Structure du projet (seulement les bits importants)
-
app - Frameworks & Drivers Couche - Fondamentalement tout ce qui est suivant. -
di - injection de dépendance - un dossier où nous configurons le conteneur DI et les modules -
drizzle - Tout DB - Initialisation du client DB, définissant le schéma, migrations -
src - la "racine" du système-
application - Couche d'application - contient des cas d'utilisation et des interfaces pour les référentiels et les services -
entities - entités Couche - Contient des modèles et des erreurs personnalisées -
infrastructure - Couche d'infrastructure - détient des implémentations de référentiels et de services et tire les interfaces de application -
interface-adapters - Couche des adaptateurs d'interface - Continuant les contrôleurs qui servent de point d'entrée au système (utilisé dans les frameworks et les pilotes pour interagir avec le système)
-
tests - Tests unitaires en direct ici - La structure du sous-dossier d' unit correspond src -
.eslintrc.json - où le plugin eslint-plugin-boundaries est défini - cela vous empêche de enfreindre la règle de dépendance -
vitest.config.ts - Prenez note de la définition du @ alias!
Explication des couches
- Frameworks et pilotes : conserve toutes les fonctionnalités du framework d'interface utilisateur et tout ce qui interagit avec le système (Ex. AWS Lambdas, Stripe Webhooks etc ...). Dans ce scénario, c'est ensuite.
- Cette couche ne doit utiliser que des contrôleurs , des modèles et des erreurs et ne doit pas utiliser de cas d'utilisation , de référentiels et de services .
- Adaptateurs d'interface : définit les contrôleurs :
- Les contrôleurs effectuent des vérifications d'authentification et une validation d'entrée avant de passer l'entrée aux cas d'utilisation spécifiques.
- Les contrôleurs orchestrent les cas d'utilisation. Ils n'implémentent aucune logique, mais définissent toutes les opérations à l'aide de cas d'utilisation.
- Les erreurs de couches plus profondes sont bouillonnantes et gérées où les contrôleurs sont utilisés.
- Les contrôleurs utilisent des présentateurs pour convertir les données en format convivial pour l'interface utilisateur juste avant de le retourner au "consommateur". Cela nous aide à expédier moins JavaScript au client (logique et bibliothèques pour convertir les données), aide à empêcher la fuite de propriétés sensibles, comme les e-mails ou les mots de passe hachés, et nous aide également à refuser la quantité de données que nous renvoyons au client.
- Application : où vit la logique métier. Parfois appelé noyau . Cette couche définit les cas d'utilisation et les interfaces pour les services et les référentiels.
- Cas d'utilisation :
- Représenter les opérations individuelles, comme "Créer Todo" ou "Connexion" ou "Toggle Todo".
- Acceptez les entrées pré-validées (des contrôleurs) et gérez les contrôles d'autorisation .
- Utilisez des référentiels et des services pour accéder aux sources de données et communiquer avec des systèmes externes.
- Les cas d'utilisation ne doivent pas utiliser d'autres cas d'utilisation . C'est une odeur de code. Cela signifie que le cas d'utilisation fait plusieurs choses et doit être décomposé en plusieurs cas d'utilisation.
- Interfaces pour les référentiels et les services:
- Ceux-ci sont définis dans cette couche car nous voulons éclater la dépendance de leurs outils et de leurs cadres (pilotes de base de données, services de messagerie, etc.), nous les implémenterons donc dans la couche d'infrastructure .
- Étant donné que les interfaces vivent dans cette couche, les cas d'utilisation (et transitoirement les couches supérieures) peuvent y accéder par injection de dépendance .
- L'injection de dépendance nous permet de diviser les définitions (interfaces) des implémentations (classes) et de les maintenir dans une couche séparée (infrastructure), mais permettent toujours leur utilisation.
- Entités : où les modèles et les erreurs sont définis.
- Modèles :
- Définissez les formes de données "domaine" avec JavaScript simple, sans utiliser les technologies "base de données".
- Les modèles ne sont pas toujours liés à la base de données - l'envoi d'e-mails nécessite un service de messagerie externe, pas une base de données, mais nous devons toujours avoir une forme de données qui aidera d'autres couches à communiquer "Envoi d'un e-mail".
- Les modèles définissent également leurs propres règles de validation, qui sont appelées «règles commerciales d'entreprise». Les règles qui ne changent généralement pas ou sont les moins susceptibles de changer lorsque quelque chose de modifications externes (navigation de page, sécurité, etc ...). Un exemple est un modèle
User qui définit un champ de nom d'utilisateur qui doit comporter au moins 6 caractères et ne pas inclure des caractères spéciaux .
- Erreurs :
- Nous voulons nos propres erreurs car nous ne voulons pas bouillonner les erreurs spécifiques à la base de données ou tout type d'erreurs spécifiques à une bibliothèque ou un cadre.
- Nous
catch des erreurs qui proviennent d'autres bibliothèques (par exemple la bruine) et convertissent ces erreurs en nos propres erreurs. - C'est ainsi que nous pouvons garder notre noyau indépendant de tous les frameworks, bibliothèques et technologies - l'un des aspects les plus importants de l'architecture propre.
- Infrastructure : lorsque des référentiels et des services sont définis.
- Cette couche extrait les interfaces des référentiels et des services de la couche d'application et les implémente dans leurs propres classes.
- Les référentiels sont la façon dont nous implémentons les opérations de base de données. Ce sont des classes qui exposent des méthodes qui effectuent une seule opération de base de données - comme
getTodo , createTodo , ou updateTodo . Cela signifie que nous utilisons uniquement la bibliothèque / pilote de base de données dans ces classes. Ils n'effectuent aucune validation de données, ne font que d'exécuter des requêtes et des mutations contre la base de données et lancer nos erreurs définies personnalisées ou des résultats de retour. - Les services sont des services partagés qui sont utilisés dans l'application - comme un service d'authentification ou un service de messagerie, ou implémenter des systèmes externes comme Stripe (créer des paiements, valider les reçus, etc.). Ces services utilisent et dépendent également d'autres cadres et bibliothèques. C'est pourquoi leur mise en œuvre est maintenue ici aux côtés des référentiels.
- Étant donné que nous ne voulons pas que la couche dépend de celle-ci (et dépend de la base de données et de tous les services), nous utilisons le principe de l'inversion de dépendance . Cela nous permet de dépendre uniquement des interfaces définies dans la couche d'application , au lieu des implémentations de la couche d'infrastructure . Nous utilisons une bibliothèque d'inversion de contrôle comme ioctopus pour abstraction de l'implémentation derrière les interfaces et "l'injecter" chaque fois que nous en avons besoin. Nous créons l'abstraction dans le répertoire
di . Nous «lions» les référentiels, les services, les contrôleurs et les cas d'utilisation aux symboles, et nous les «résolvons» en utilisant ces symboles lorsque nous avons besoin de l'implémentation réelle. C'est ainsi que nous pouvons utiliser l'implémentation, sans avoir besoin de dépendre explicitement de celui-ci (importez-le).
FAQ
Conseil
Si vous avez une question non couverte par la FAQ, n'hésitez pas à ouvrir un problème dans ce dépôt ou à rejoindre mon serveur Discord et à démarrer une conversation là-bas.
Clean Architecture / Cette implémentation est-elle conviviale sans serveur? Puis-je déployer cela sur Vercel?
Oui! Vous pouvez l'utiliser avec le routeur de page, le routeur d'application, le middleware, les gestionnaires d'API, les actions de serveur, tout! Habituellement, la réalisation d'injection de dépendances dans les projets JavaScript se fait avec la bibliothèque inversify.js, qui est incompatible avec d'autres temps d'exécution sauf le nœud. Ce projet implémente IOCTOPUS, un simple conteneur IOC qui ne s'appuie pas sur reflect-metadata et fonctionne sur tous les temps.
Dois-je commencer à mettre en œuvre une architecture propre immédiatement lorsque je crée mon projet Next.js?
Je dirais non . Si vous créez un tout nouveau projet, je vous conseille de vous concentrer sur la réalisation d'un statut MVP le plus rapidement possible (afin que vous puissiez valider votre idée / voir s'il y a un avenir pour votre projet). Lorsque les choses commencent à devenir sérieuses (plus de fonctionnalités commencent à être implémentées, votre base d'utilisateurs connaît une croissance importante, ou que vous intégrez d'autres développeurs dans votre projet), c'est à ce moment que vous souhaitez investir un peu de temps pour adapter cette architecture (ou toute architecture d'ailleurs).
Si vous êtes déjà profondément dans les mauvaises herbes sur un projet, vous (et votre équipe) pouvez planifier une refactorisation progressive à partir du prochain sprint. Dans ce cas, vous avez déjà écrit le code, il vous suffit de le réorganiser un peu, et vous pouvez faire cette partie par partie, gestionnaire d'itinéraire par gestionnaire d'itinéraire, action du serveur par action du serveur. Soit dit en passant, je le dis à la légère "vous avez juste besoin de le réorganiser un peu" , mais cela peut être loin d'être aussi simple que cela. Tenez toujours compte des «choses qui ne va pas» lorsque vous planifiez le refactorisation. Et consacrez du temps à des tests d'écriture!
Cela ressemble à une surgénération et complique le développement des fonctionnalités.
Si vous ne passez pas plus de 3 minutes à y penser, alors oui, cela ressemble à une surgénération. Mais si vous le faites, vous vous rendrez compte que l'architecture = discipline . L'architecture est un contrat entre les développeurs qui définit ce qui va où. Il simplifie en fait le développement des fonctionnalités car il rend la base de code prévisible, et il prend ces décisions pour vous.
Vous ne pouvez pas développer un projet de manière durable si chaque développeur qui y travaille écrit du code où il est le plus pratique. La base de code se transformera en cauchemar pour travailler, et c'est à ce moment-là que vous ressentirez un processus de développement de fonctionnalités compliqué. Pour vous battre, vous finirez par élaborer quelques règles. Ces règles augmenteront à mesure que votre équipe sera confrontée et résout de nouveaux problèmes. Mettez toutes ces règles dans un document, et il y a votre propre définition d'architecture. Vous implémentez toujours une sorte d'architecture, vous venez d'atteindre ce point très lentement et douloureusement.
L'architecture propre vous donne un raccourci et une architecture prédéfinie qui a été testée. Et oui, bien sûr, vous devez apprendre tout cela, mais vous le faites une fois dans votre vie, puis appliquez simplement les principes dans n'importe quelle langue ou cadre que vous utiliserez à l'avenir.
Dois-je appliquer une architecture propre dans tous mes projets?
Non . Pas si vous ne vous attendez pas à ce que le projet augmente, à la fois en nombre de fonctionnalités, en nombre d'utilisateurs, ou en nombre de développeurs qui y travaillent.
Quelles sont les autres architectures similaires à l'architecture propre?
Comme mentionné dans le blog original que j'ai mentionné en haut de la lecture, vous avez:
- Architecture hexagonale (aka ports et adaptateurs) par Alistair Cockburn
- Architecture d'oignon par Jeffrey Palermo
- Architecture hurlante de l'oncle Bob (le même gars derrière une architecture propre)
- Et quelques autres (consultez le billet de blog original)


