nextjs clean architecture
1.0.0
Dieses Repo ist ein Beispiel dafür, wie man eine saubere Architektur in Next.js. Es gibt ein Video -Tutorial, das dieses Projekt durchläuft. Klicken Sie auf das Bild, um es auf YouTube zu überprüfen:
Sie können das Projekt ausführen, indem Sie npm install und npm run dev ausführen.
Notiz
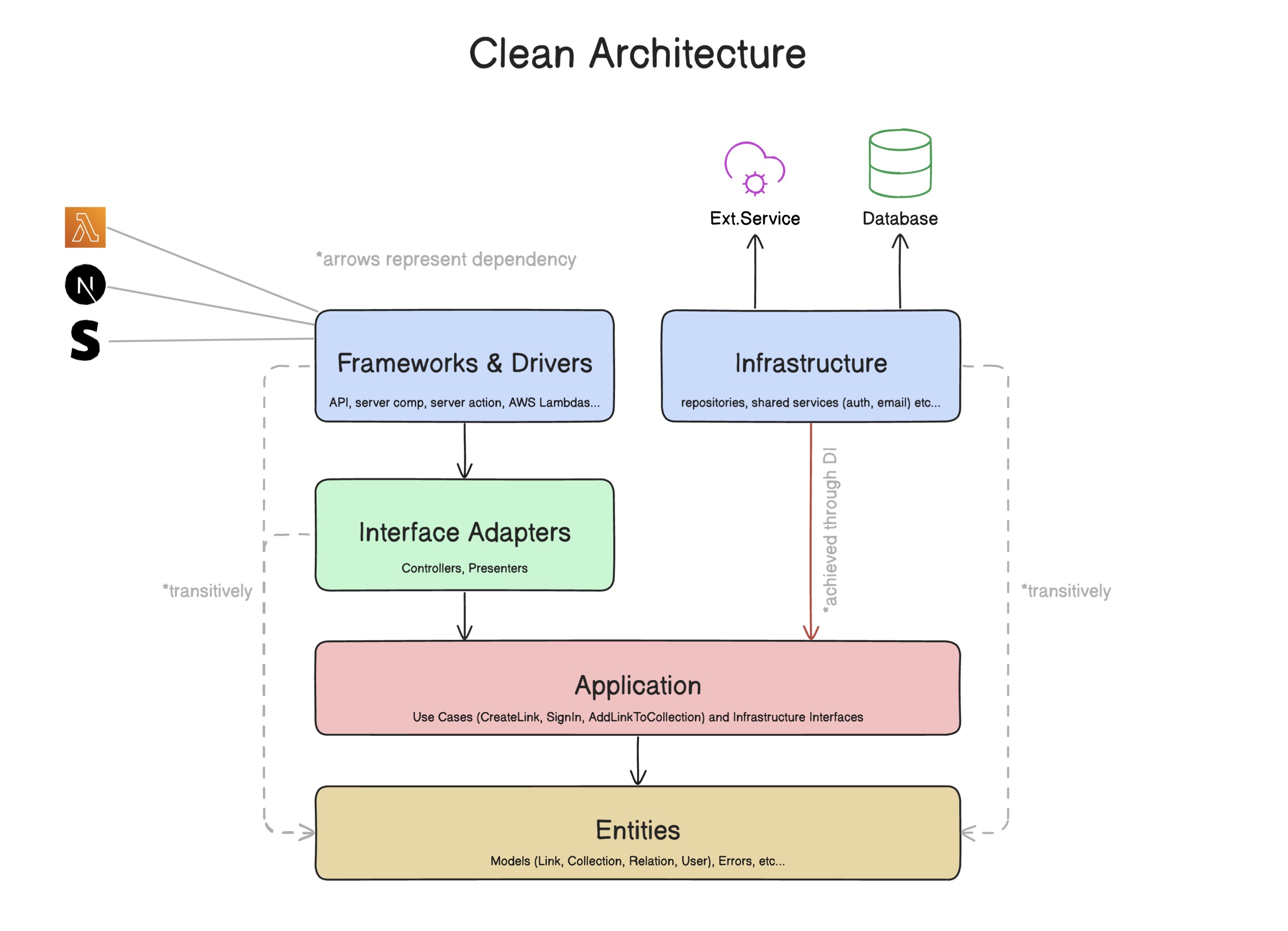
? Ich habe diese vereinfachte Version des ursprünglichen Clean Architecture Diagramms gezeichnet. Ich habe es auf eine Weise vereinfacht, die für mich sinnvoller ist, und es ist einfacher zu verstehen. Ich hoffe es hilft dir auch.
Ich empfehle Ihnen dringend, den Originalartikel von Onkel Bob zu lesen, wenn dies Sie zum ersten Mal über saubere Architektur hören, aber ich werde versuchen, ihn unten für Sie zusammenzufassen.
Clean Architecture ist eine Reihe von Regeln , die uns helfen, unsere Anwendungen so zu strukturieren, dass sie leichter zu warten und zu testen sind, und ihre Codebasen sind vorhersehbar. Es ist wie eine gemeinsame Sprache, die Entwickler verstehen, unabhängig von ihren technischen Hintergründen und Programmiersprachenpräferenzen.
Saubere Architektur und ähnliche/abgeleitete Architekturen haben alle das gleiche Ziel - die Trennung von Bedenken . Sie führen Ebenen ein, die einen ähnlichen Code zusammenbündet. Das "Schichten" hilft uns, wichtige Aspekte in unserer Codebasis zu erreichen:
Clean Architecture erreicht dies durch die Definition einer Abhängigkeitshierarchie - Schichten hängen nur von Schichten unter ihnen ab, aber nicht oben.
app - Frameworks & Trivers Layer - Grundsätzlich alles als Next.js (Seiten, Serveraktionen, Komponenten, Stile usw.) oder was auch immer "konsumiert" die Logik der Appdi - Abhängigkeitsinjektion - Ein Ordner, in dem wir den DI -Behälter und die Module einrichtendrizzle - alles DB - Initialisierung des DB -Clients, Definieren von Schema, Migrationensrc - die "Wurzel" des Systemsapplication - Anwendungsschicht - Hält Anwendungsfälle und Schnittstellen für Repositorys und Diensteentities - Entitäten Ebene - enthält Modelle und benutzerdefinierte Fehlerinfrastructure - Infrastrukturschicht - enthält Implementierungen von Repositorys und Diensten und zieht die Schnittstellen aus application aninterface-adapters - Schnittstellenadapterschicht - Hält Controller, die als Einstiegspunkt für das System dienen (verwendet in Frameworks & Drivers Layer, um mit dem System zu interagieren)tests - Unit -Tests hier live - Die Struktur des unit entspricht src.eslintrc.json - wo das Plugin eslint-plugin-boundaries definiert ist - dies hält Sie daran, die Abhängigkeitsregel zu brechenvitest.config.ts - Beachten Sie, wie der @ alias definiert ist! User , das ein Benutzernamefeld definiert, das mindestens 6 Zeichen lang sein muss und keine Sonderzeichen enthalten .catch Fehler auf, die aus anderen Bibliotheken stammen (z. B. Nieselregen), und konvertieren diese Fehler in unsere eigenen Fehler.getTodo , createTodo oder updateTodo . Dies bedeutet, dass wir nur die Datenbankbibliothek / den Treiber in diesen Klassen verwenden. Sie führen keine Datenvalidierung durch, führen Sie einfach Abfragen und Mutationen gegen die Datenbank aus und werfen entweder unsere benutzerdefinierten definierten Fehler oder geben Sie die Ergebnisse zurück.di -Verzeichnis. Wir "binden" die Repositorys, Dienste, Controller und Anwendungsfälle an Symbole und "lösen" sie anhand dieser Symbole, wenn wir die tatsächliche Implementierung benötigen. So können wir die Implementierung verwenden, ohne sie explizit davon abhängen zu müssen (importieren). Tipp
Wenn Sie eine Frage haben, die nicht von den FAQs abgedeckt ist, können Sie entweder ein Problem in diesem Repo eröffnen oder meinem Discord -Server beigetreten und dort eine Konversation starten.
Ja! Sie können es mit Page -Router, App -Router, Middleware, API -Handlern, Serveraktionen und allem verwenden! In der Regel wird die Erlangung der Abhängigkeitsinjektion in JavaScript -Projekten mit der Inversify.js -Bibliothek durchgeführt, die mit anderen Laufzeiten mit Ausnahme des Knotens nicht kompatibel ist. Dieses Projekt implementiert Ioctopus, einen einfachen IOC-Container, der nicht auf reflect-metadata beruht und auf allen Laufzeiten funktioniert.
Ich würde nein sagen. Wenn Sie ein brandneues Projekt starten, würde ich Ihnen raten, sich darauf zu konzentrieren, einen MVP -Status so schnell wie möglich zu erreichen (damit Sie Ihre Idee validieren / sehen können, ob es eine Zukunft für Ihr Projekt gibt). Wenn die Dinge ernst werden (weitere Funktionen werden implementiert, Ihre Benutzerbasis erlebt ein erhebliches Wachstum oder Sie haben andere Entwickler in Ihrem Projekt an Bord), dann möchten Sie einige Zeit in die Anpassung dieser Architektur (oder einer Architektur) investieren.
Wenn Sie bereits tief im Unkraut eines Projekts sind, können Sie (und Ihr Team) ab dem nächsten Sprint schrittweise refactoring planen. In diesem Fall haben Sie bereits den Code geschrieben, Sie müssen ihn nur ein wenig umstrukturieren, und Sie können diesen Teil per Teil, Routenhandler mit Routenhandler, Server -Aktion nach Serveraktionen durchführen. Übrigens sage ich es leicht: "Sie müssen es nur ein wenig neu organisieren" , aber es kann weit davon entfernt sein, so einfach so einfach zu sein. Berücksichtigen Sie immer "Dinge, die schief gehen", wenn Sie das Refactoring planen. Und etwas Zeit für das Schreiben von Tests!
Wenn Sie nicht länger als 3 Minuten darüber nachdenken, dann sieht es nach übergineerahen aus. Aber wenn Sie dies tun, werden Sie diese Architektur = Disziplin erkennen. Die Architektur ist ein Vertrag zwischen den Entwicklern, der definiert, was wohin geht. Es vereinfacht tatsächlich die Funktionsentwicklung, da die Codebasis vorhersehbar ist und diese Entscheidungen für Sie trifft.
Sie können ein Projekt nicht nachhaltig anbauen, wenn jeder Entwickler, der daran arbeitet, Code schreibt, wo es am bequemsten ist. Die Codebasis wird zu einem Albtraum, mit dem Sie arbeiten können, und dann fühlen Sie sich einen wirklich komplizierten Feature -Entwicklungsprozess. Um dies zu bekämpfen, werden Sie irgendwann einige Regeln festlegen. Diese Regeln werden wachsen, wenn Ihr Team konfrontiert ist und neue Probleme löst. Legen Sie all diese Regeln in ein Dokument ein, und es gibt Ihre eigene Architekturdefinition. Sie implementieren immer noch eine Art Architektur, Sie haben diesen Punkt nur sehr langsam und schmerzhaft erreicht.
Clean Architecture bietet Ihnen eine Abkürzung und eine vordefinierte Architektur, die getestet wurde. Und ja, sicher, Sie müssen all dies lernen, aber Sie tun es einmal in Ihrem Leben und wenden dann nur die Prinzipien in jeder Sprache oder in jeder Framework an, die Sie in Zukunft verwenden.
NEIN . Nicht, wenn Sie nicht erwarten, dass das Projekt sowohl in Bezug auf die Anzahl der Funktionen als auch die Anzahl der Benutzer oder die Anzahl der daran arbeiten.
Wie im ursprünglichen Blog -Beitrag erwähnt, den ich oben in der Readme erwähnt habe, haben Sie:


