Smart Recruitment System
1.0.0
Sistema de recrutamento inteligente
Encontrar o melhor candidato para um emprego específico de um processo de recrutamento no menor tempo é um desafio para uma empresa hoje em dia. Atualmente, existem muitos candidatos e leva muito tempo e esforço para obter candidatos adequados para o trabalho de uma empresa. A equipe de Recursos Humanos precisa de mais força de trabalho para examinar os currículos ou currículos de candidatos.
O projeto tem como objetivo desenvolver um sistema Ranker mais flexível, realista e especialista, que classifique os currículos de maneira eficaz e eficiente e oferece o melhor candidato ou candidatos. Este é um site simples de currículo com base no Django, onde os usuários do recrutador publicam empregos, os usuários de candidatos se aplicam ao trabalho, preenchem os dados necessários e o upload de currículos. O sistema classifica os currículos com base na similaridade do documento da descrição do trabalho e nos currículos usando o modelo KNN. Economiza esforços humanos, tempo e custo.
Requer os seguintes pacotes:
Recomenda -se usar pacotes de ambiente virtual, como o VirtualEnv. Siga as etapas abaixo para configurar o projeto:
git clone https://github.com/parvez86/Smart-Recruitment-Systempip install -r requirements.txtsettings.py De acordo com o seu banco de dados. Instale o conector de banco de dados apropriado, se necessário. DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'DB_NAME',
'USER': 'DB_USER',
'PASSWORD': 'DB_PASSWORD',
'HOST': 'localhost', # Or an IP Address that your DB is hosted on
'PORT': '3306',
}
}
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': 'mydatabase', # This is where you put the name of the db file.
# If one doesn't exist, it will be created at migration time.
}
}
python manage.py makemigrationspython manage.py migratepython manage.py createsuperuser . E digite o nome de usuário, email e senha.python manage.py runserver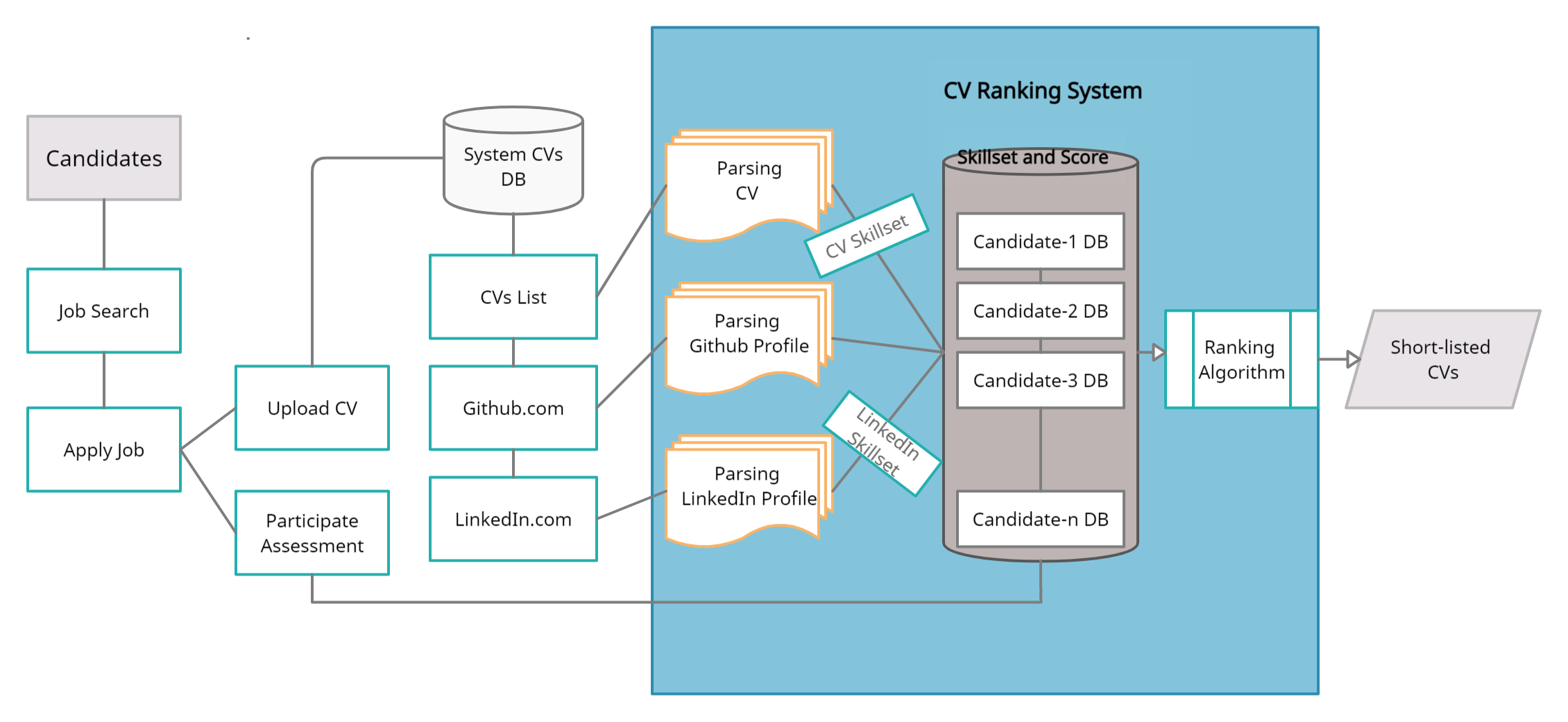
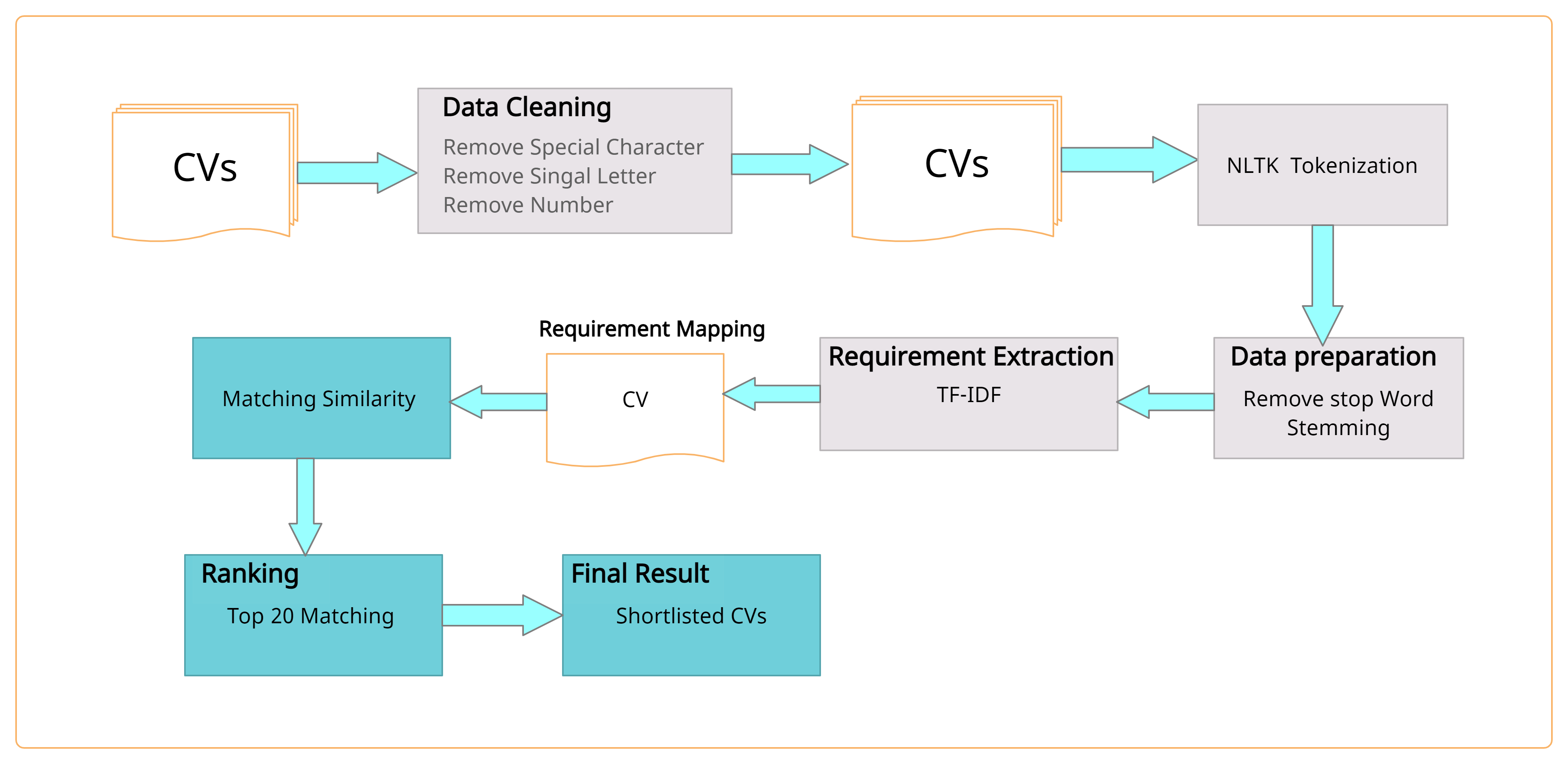
TF(‘keyword’) = number of appeared (‘keyword’)/Total number of (‘keyword’)
IDF(‘keyword’) = log(total number of resumes / total number of the resume with term ‘keywords’)
It sets IDF log value = 1 for the required resume and 0 for the unwanted.


