Smart Recruitment System
1.0.0
Sistema de reclutamiento inteligente
Encontrar el mejor candidato para un trabajo específico de un proceso de reclutamiento en el menor tiempo es un desafío para una empresa hoy en día. Hoy en día, hay demasiados solicitantes, y se necesita demasiado tiempo y esfuerzo para obtener candidatos adecuados para el trabajo de una empresa. El equipo de recursos humanos necesita más fuerza laboral para analizar los currículums o CVS de los candidatos.
El proyecto tiene como objetivo desarrollar un sistema de clasificadores de currículum más flexible, realista y experto que clasifique los currículums de manera efectiva y eficiente y brinde a los mejores candidatos o candidatos. Este es un simple sitio web de Ranker de currículum basado en Django donde los usuarios de reclutadores publican trabajos, los usuarios de candidatos solicitan el trabajo, completan los datos requeridos y cargan currículums. El sistema clasifica los currículums basados en la similitud del documento de la descripción del trabajo y los currículums utilizando el modelo KNN. Ahorra esfuerzos humanos, tiempo y costo.
Requiere los siguientes paquetes:
Se recomienda utilizar paquetes de entorno virtual como VirtualEnv. Siga los pasos a continuación para configurar el proyecto:
git clone https://github.com/parvez86/Smart-Recruitment-Systempip install -r requirements.txtsettings.py de acuerdo con su base de datos. Instale el conector de base de datos apropiado si es necesario. DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'DB_NAME',
'USER': 'DB_USER',
'PASSWORD': 'DB_PASSWORD',
'HOST': 'localhost', # Or an IP Address that your DB is hosted on
'PORT': '3306',
}
}
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': 'mydatabase', # This is where you put the name of the db file.
# If one doesn't exist, it will be created at migration time.
}
}
python manage.py makemigrationspython manage.py migratepython manage.py createsuperuser . E ingrese el nombre de usuario, el correo electrónico y la contraseña.python manage.py runserver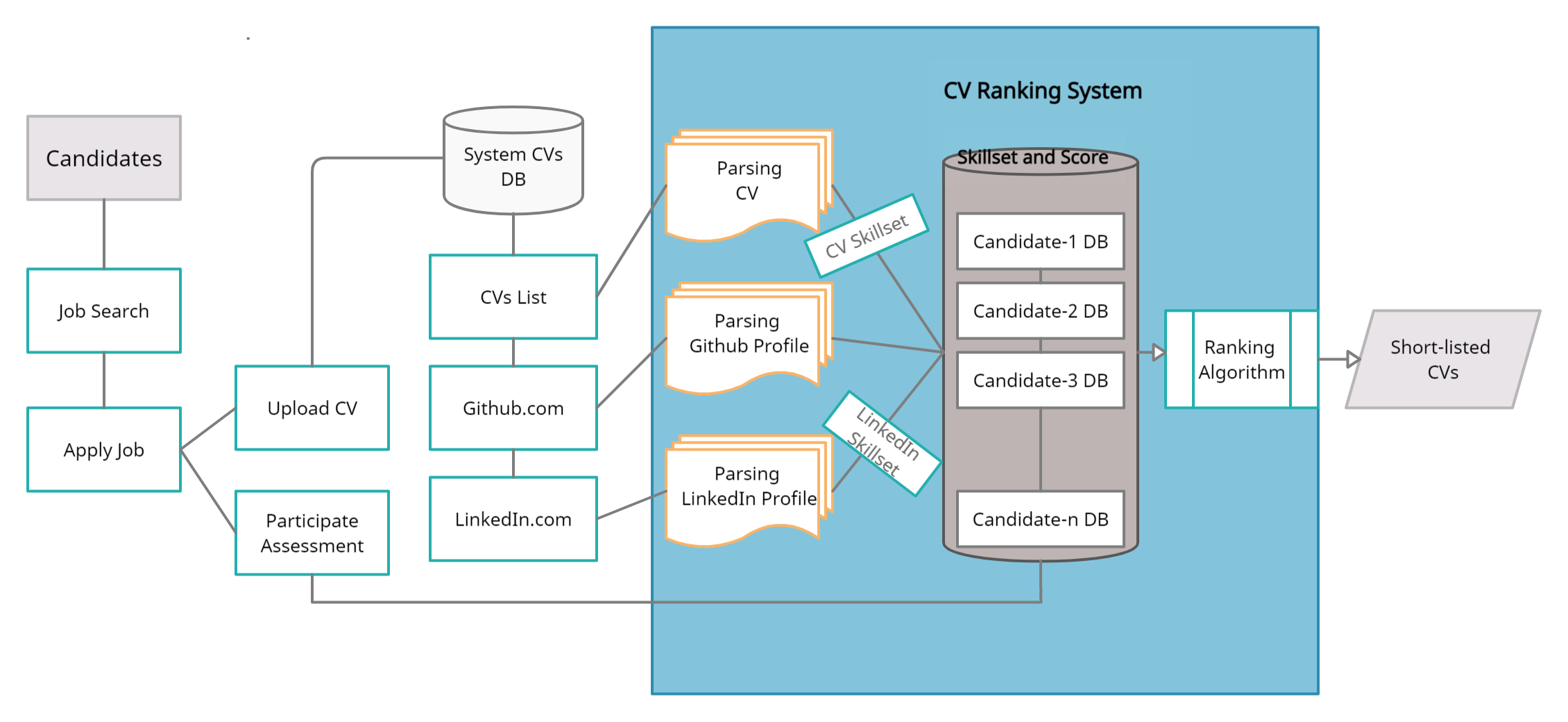
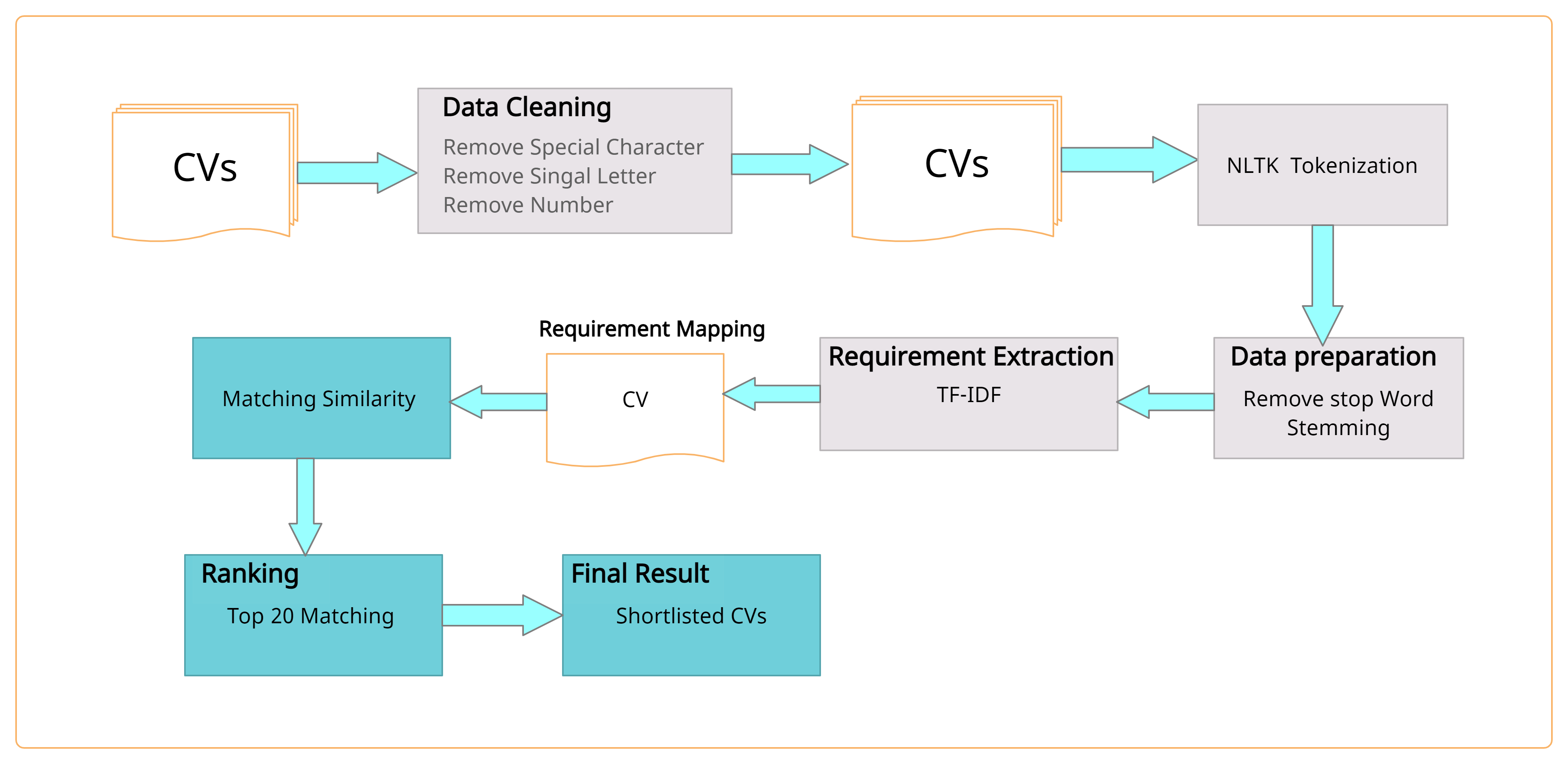
TF(‘keyword’) = number of appeared (‘keyword’)/Total number of (‘keyword’)
IDF(‘keyword’) = log(total number of resumes / total number of the resume with term ‘keywords’)
It sets IDF log value = 1 for the required resume and 0 for the unwanted.


