Smart Recruitment System
1.0.0
Умная система набора персонала
Поиск лучшего кандидата на конкретную работу из процесса найма в кратчайшие сроки является проблемой для компании в настоящее время. В настоящее время претендентов слишком много, и требуется слишком много времени и усилий, чтобы получить подходящих кандидатов для работы компании. Команду по персоналу нуждаются в большем количестве рабочей силы, чтобы изучить резюме или резюме кандидатов.
Проект направлен на разработку более гибкой, реалистичной и экспертной системы Resumer Ranker, которая эффективно и эффективно оценивает резюме и дает лучшего кандидата или кандидатов. Это простой веб-сайт Resume Ranker на основе Django, на котором пользователи рекрутера публикуют задания, кандидатские пользователи подают заявку на работу, заполняют необходимые данные и загрузку резюме. Система оценивает резюме на основе сходства документов описания задания и резюме с использованием модели KNN. Это экономит человеческие усилия, время и стоимость.
Требуются следующие пакеты:
Рекомендуется использовать пакеты виртуальной среды, такие как VirtualEnv. Следуйте приведенным ниже шагам, чтобы настроить проект:
git clone https://github.com/parvez86/Smart-Recruitment-Systempip install -r requirements.txtsettings.py в соответствии с вашей базой данных. Установите соответствующий разъем базы данных, если это необходимо. DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'DB_NAME',
'USER': 'DB_USER',
'PASSWORD': 'DB_PASSWORD',
'HOST': 'localhost', # Or an IP Address that your DB is hosted on
'PORT': '3306',
}
}
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': 'mydatabase', # This is where you put the name of the db file.
# If one doesn't exist, it will be created at migration time.
}
}
python manage.py makemigrationspython manage.py migratepython manage.py createsuperuser . И введите имя пользователя, электронную почту и пароль.python manage.py runserver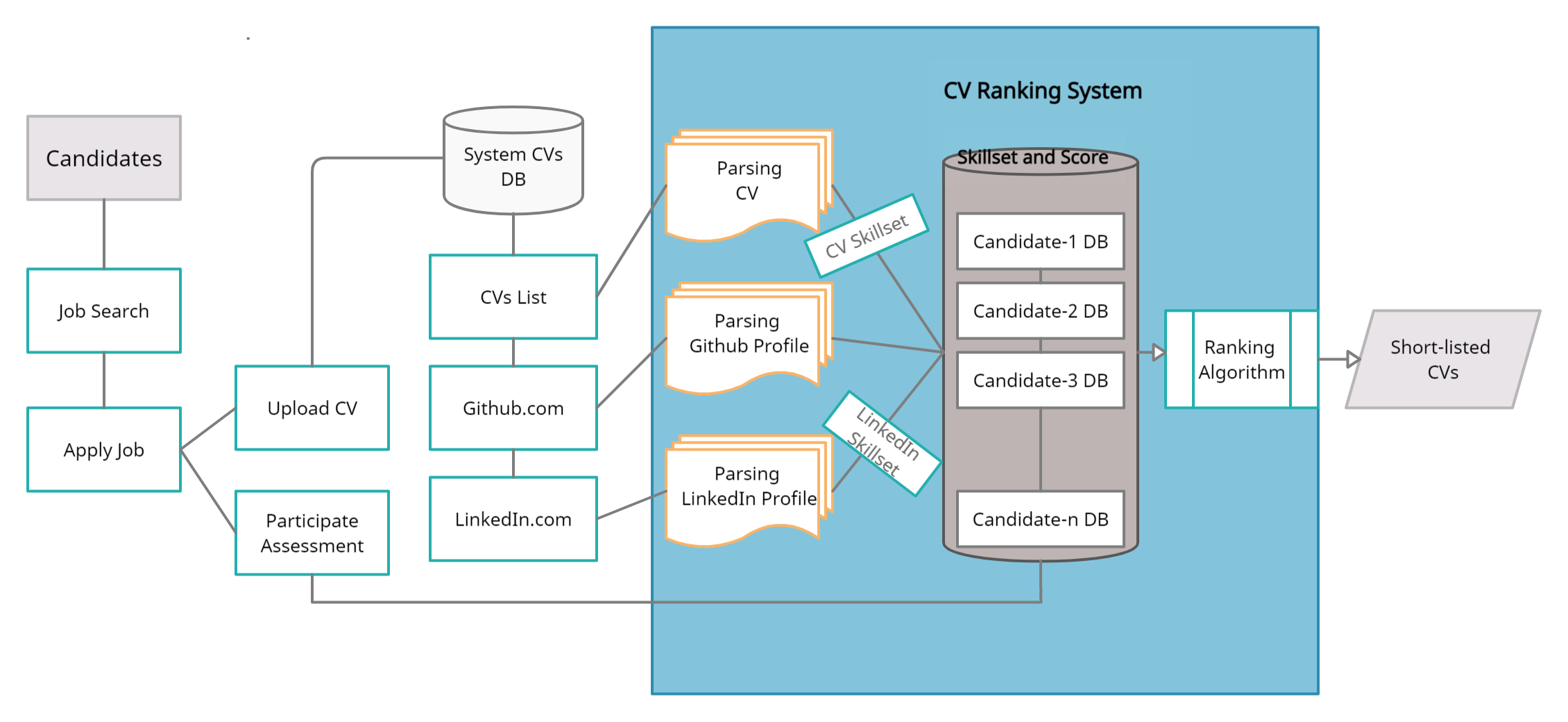
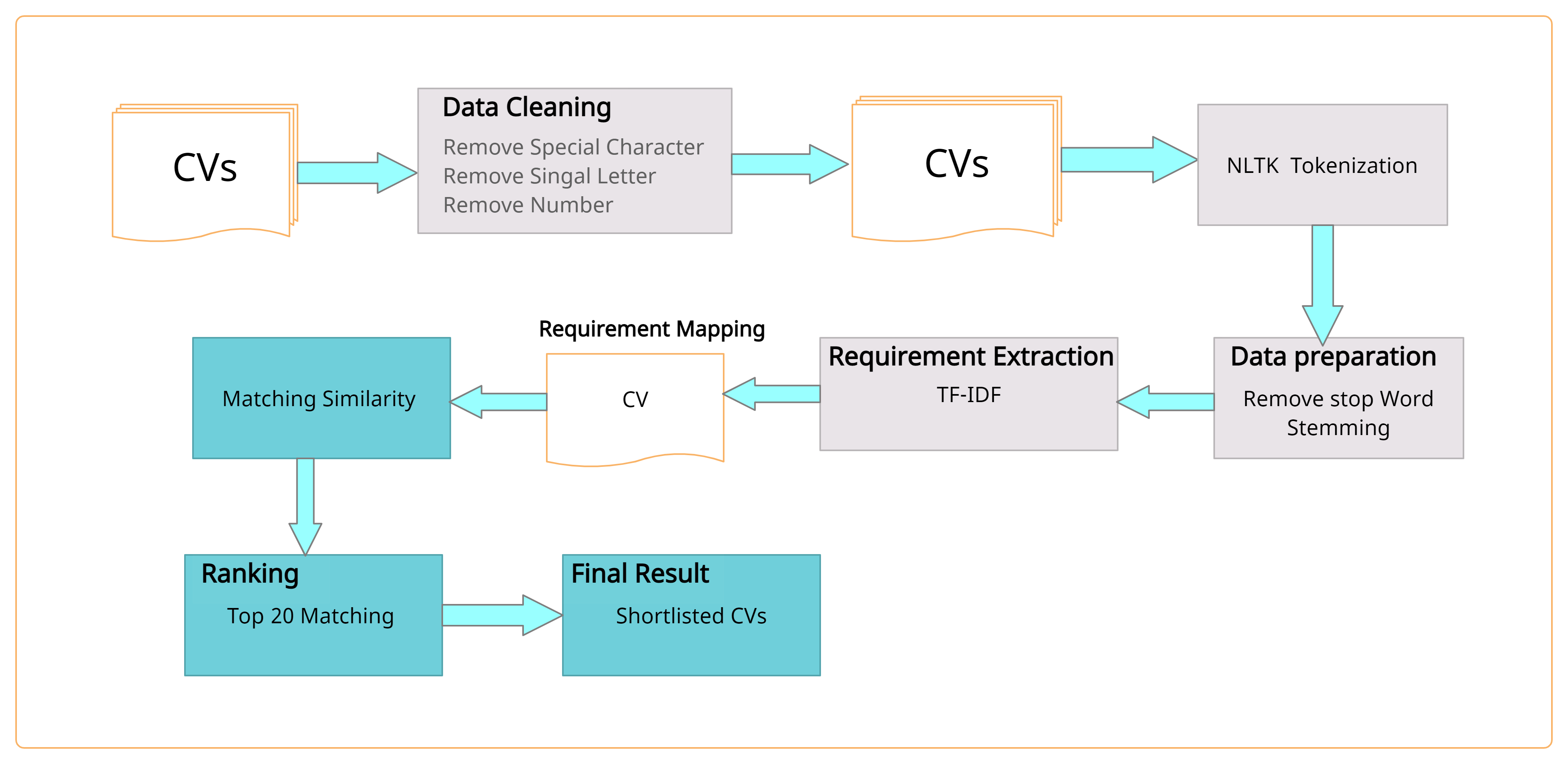
TF(‘keyword’) = number of appeared (‘keyword’)/Total number of (‘keyword’)
IDF(‘keyword’) = log(total number of resumes / total number of the resume with term ‘keywords’)
It sets IDF log value = 1 for the required resume and 0 for the unwanted.


