Smart Recruitment System
1.0.0
Smart Recruitment System
Der beste Kandidat für einen bestimmten Job aus einem Rekrutierungsprozess innerhalb der kürzesten Zeit ist heutzutage eine Herausforderung für ein Unternehmen. Heutzutage gibt es zu viele Bewerber, und es braucht zu viel Zeit und Mühe, um geeignete Kandidaten für den Job eines Unternehmens zu erhalten. Das Personalteam benötigt mehr Belegschaft, um die Lebensläufe oder Lebensläufe von Kandidaten zu prüfen.
Das Projekt zielt darauf ab, ein flexibleres, realistischeres und erfahrener Lebenslauf -Rankiersystem zu entwickeln, das die Lebensläufe effektiv und effizient einsetzt und den besten Kandidaten oder Kandidaten bietet. Dies ist eine einfache Django-basierte Lebenslauf-Ranker-Website, auf der Personalbenutzer Jobs veröffentlichen, Kandidatenbenutzer für den Job bewerben, die erforderlichen Daten ausfüllen und Lebensläufe hochladen. Das System bewertet die Lebensläufe basierend auf der Dokumentähnlichkeit der Stellenbeschreibung und der Lebensläufe mit dem KNN -Modell. Es spart menschliche Anstrengungen, Zeit und Kosten.
Erfordert die folgenden Pakete:
Es wird empfohlen, virtuelle Umgebungspakete wie Virtualenv zu verwenden. Befolgen Sie die folgenden Schritte, um das Projekt einzurichten:
git clone https://github.com/parvez86/Smart-Recruitment-Systempip install -r requirements.txt zu installieren.txtsettings.py gemäß Ihrer Datenbank. Installieren Sie bei Bedarf den entsprechenden Datenbankanschluss. DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'DB_NAME',
'USER': 'DB_USER',
'PASSWORD': 'DB_PASSWORD',
'HOST': 'localhost', # Or an IP Address that your DB is hosted on
'PORT': '3306',
}
}
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': 'mydatabase', # This is where you put the name of the db file.
# If one doesn't exist, it will be created at migration time.
}
}
python manage.py makemigrationspython manage.py migratepython manage.py createsuperuser . Und geben Sie den Benutzernamen, die E -Mail und das Passwort ein.python manage.py runserver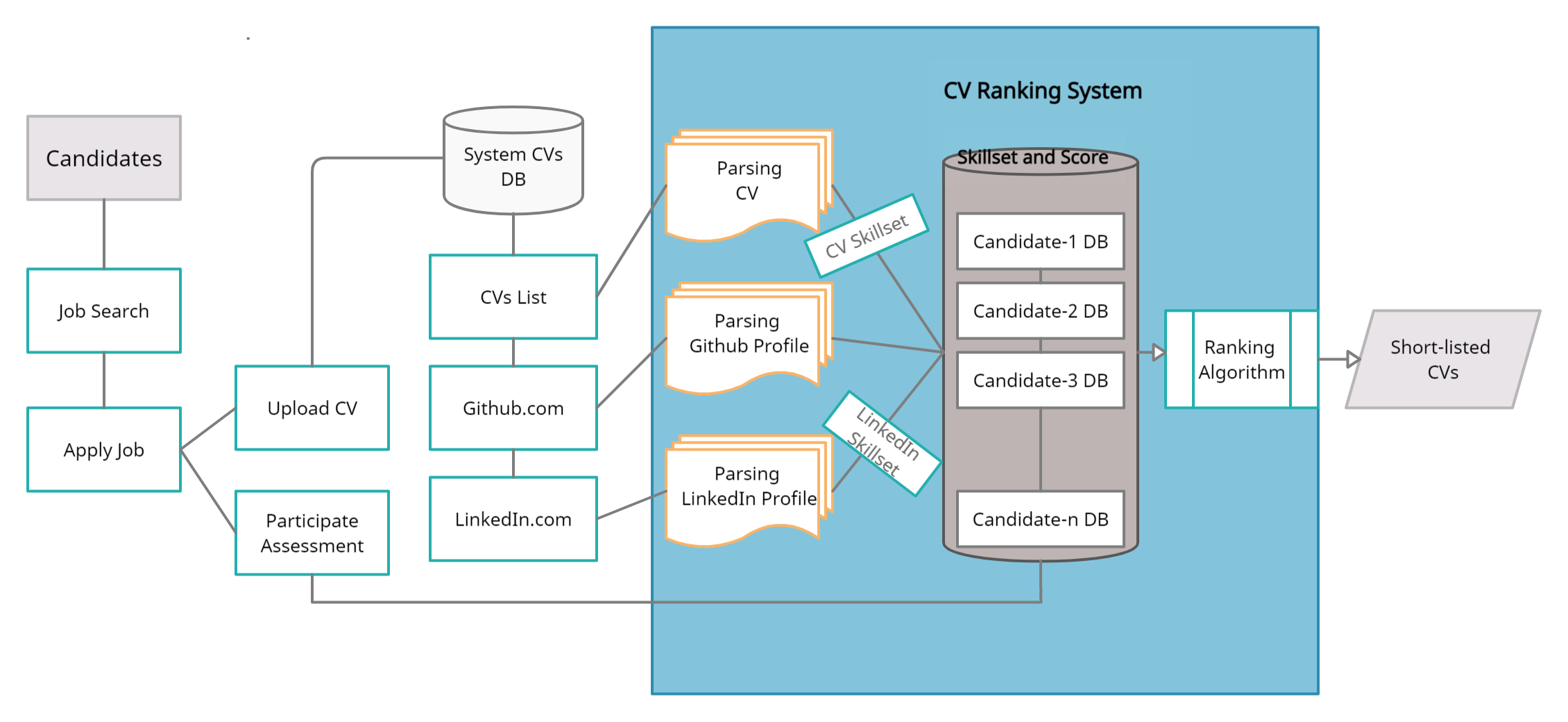
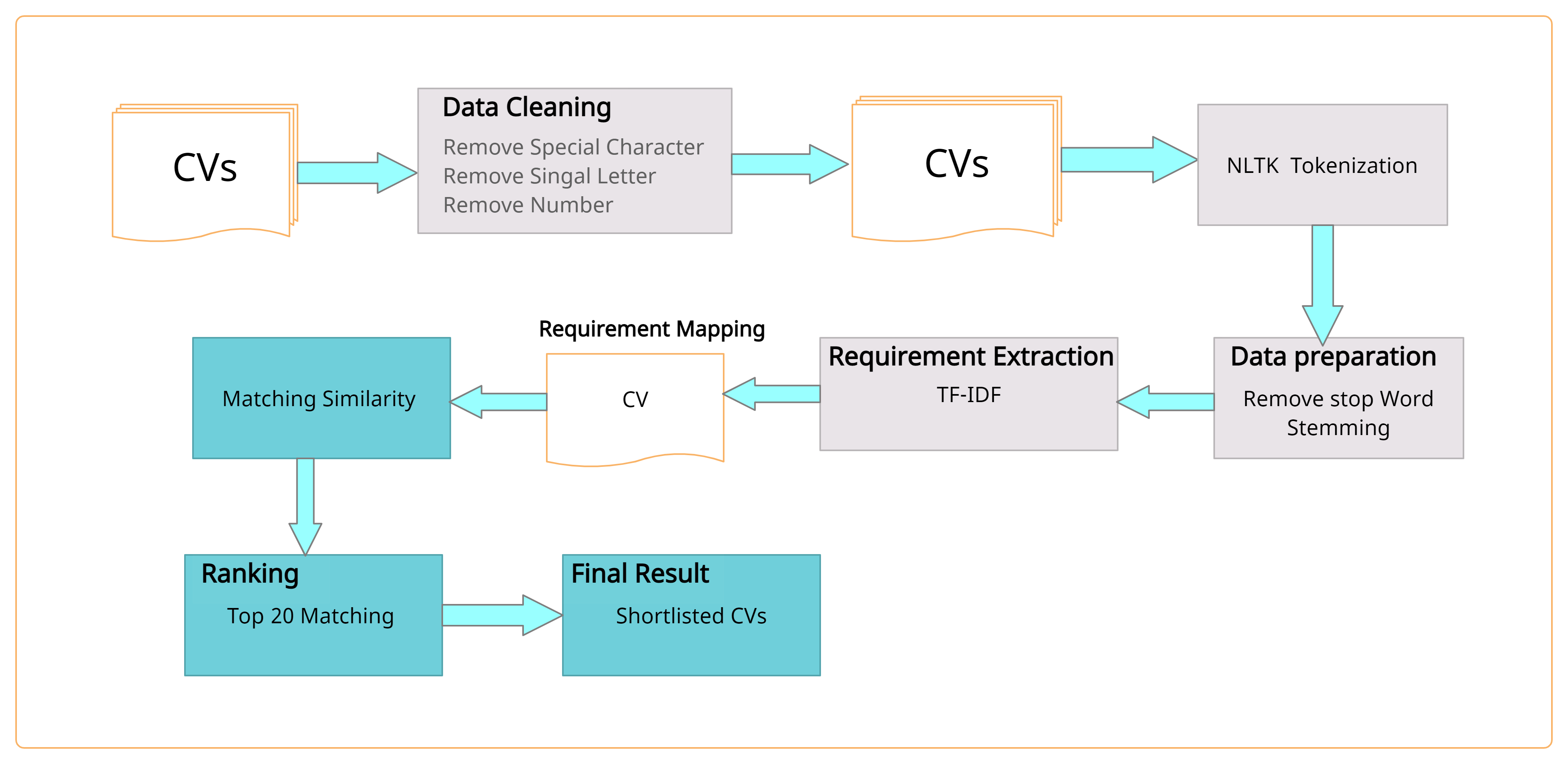
TF(‘keyword’) = number of appeared (‘keyword’)/Total number of (‘keyword’)
IDF(‘keyword’) = log(total number of resumes / total number of the resume with term ‘keywords’)
It sets IDF log value = 1 for the required resume and 0 for the unwanted.


