MEAL
1.0.0
O código e os dados para o nosso artigo de descobertas do EMNLP 2023: refeição (papel).
Nossas descobertas-chave são:
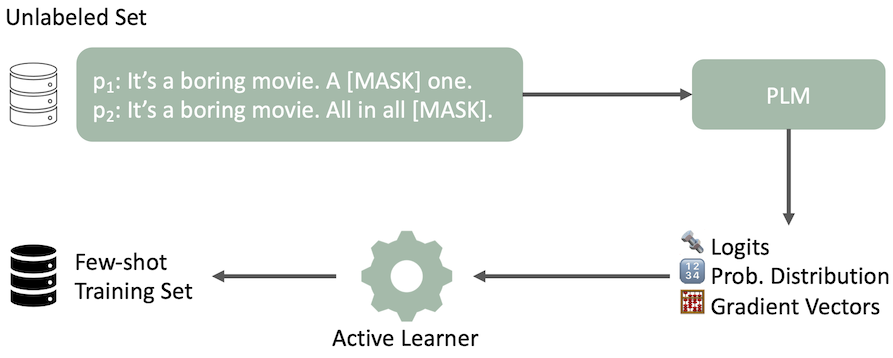 Nosso pipeline de aprendizado ativo modificado para a seleção de dados é ilustrado com uma frase de exemplo e duas solicitações para análise de sentimentos. O PLM produz vários recursos de maneira zero. O AL seleciona um conjunto de treinamento com poucos tiros com base nesses recursos de saída.
Nosso pipeline de aprendizado ativo modificado para a seleção de dados é ilustrado com uma frase de exemplo e duas solicitações para análise de sentimentos. O PLM produz vários recursos de maneira zero. O AL seleciona um conjunto de treinamento com poucos tiros com base nesses recursos de saída.
| ACC ↑ | Classificação ↓ | Div. ↑ | Repr. ↑ | Ent. ↓ | |
|---|---|---|---|---|---|
| Aleatório | 72,6 ± 2,8 | 4.0 | 13.6 | 17.6 | 2.0 |
| Entropia | 70.9 | 6.4 | 13.3 | 16.9 | 6.1 |
| LC | 70.9 | 5.6 | 13.5 | 17.2 | 5.3 |
| Bt | 72.1 | 4.0 | 13.4 | 17.1 | 5.6 |
| Pp-kl (nosso) | 69.1 | 5.6 | 13.4 | 16.9 | 9.0 |
| Cal | 70.4 | 4.4 | 13.1 | 17.1 | 23.5 |
| DISTINTIVO | 73,2 ± 3,3 | 3.0 | 13.6 | 17.6 | 2.2 |
| Ipusd (nosso) | 73,9 ± 2,3 | 3.0 | 13.5 | 17.6 | 2.0 |
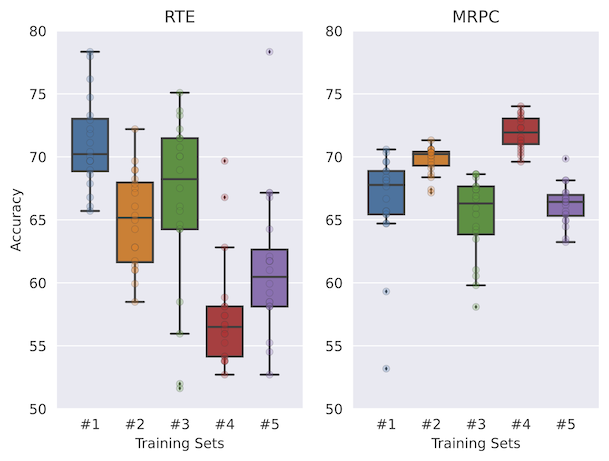
O IPUSD, nossa estratégia de seleção de dados proposta, para poucas fotos, atinge maior precisão, proporcionando uma variação muito mais baixa entre RTE, SST-2, SST-5, TREC e MRPC. Mostramos que as heurísticas como entropia aleatória ou mais alta levariam a um desempenho muito menor.
Confira as divisões de dados para diferentes estratégias de aprendizado ativo (incluindo divisões de dados não marcadas e de avaliação) na pasta DataSets.
@inproceedings{koksal-etal-2023-meal,
title = "{MEAL}: Stable and Active Learning for Few-Shot Prompting",
author = {K{"o}ksal, Abdullatif and
Schick, Timo and
Schuetze, Hinrich},
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2023",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-emnlp.36",
doi = "10.18653/v1/2023.findings-emnlp.36",
pages = "506--517"
}


