MEAL
1.0.0
Der Code und die Daten für unser EMNLP 2023 -Erkenntnispapier: Mahlzeit (Papier).
Unsere Schlüsselfindungen sind:
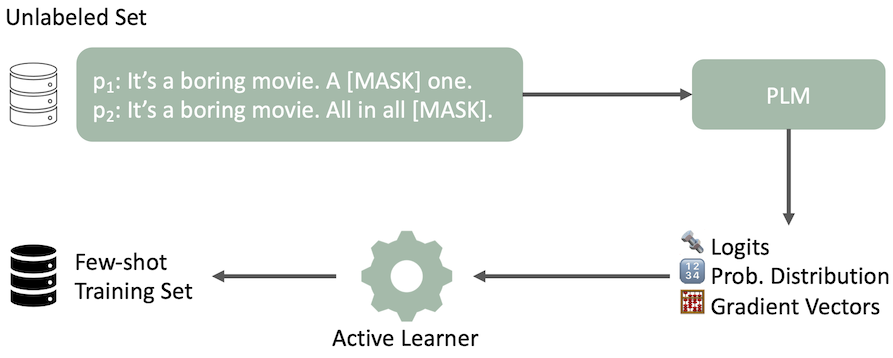 Unsere modifizierte aktive Lernpipeline für die Datenauswahl wird mit einem Beispielsatz und zwei Eingabeaufforderungen für die Stimmungsanalyse dargestellt. Der PLM gibt mehrere Merkmale auf null Schuss aus. AL wählt basierend auf diesen Ausgabemunktionen einige Schuss-Trainingseinsätze aus.
Unsere modifizierte aktive Lernpipeline für die Datenauswahl wird mit einem Beispielsatz und zwei Eingabeaufforderungen für die Stimmungsanalyse dargestellt. Der PLM gibt mehrere Merkmale auf null Schuss aus. AL wählt basierend auf diesen Ausgabemunktionen einige Schuss-Trainingseinsätze aus.
| ACC ↑ | Rang ↓ | Div. ↑ | Reprieren ↑ | Enthülle. ↓ | |
|---|---|---|---|---|---|
| Zufällig | 72,6 ± 2,8 | 4.0 | 13.6 | 17.6 | 2.0 |
| Entropie | 70,9 | 6.4 | 13.3 | 16.9 | 6.1 |
| LC | 70,9 | 5.6 | 13.5 | 17.2 | 5.3 |
| Bt | 72.1 | 4.0 | 13.4 | 17.1 | 5.6 |
| Pp-kl (unsere) | 69.1 | 5.6 | 13.4 | 16.9 | 9.0 |
| Cal | 70,4 | 4.4 | 13.1 | 17.1 | 23.5 |
| ABZEICHEN | 73,2 ± 3,3 | 3.0 | 13.6 | 17.6 | 2.2 |
| Ipusd (unsere) | 73,9 ± 2,3 | 3.0 | 13.5 | 17.6 | 2.0 |
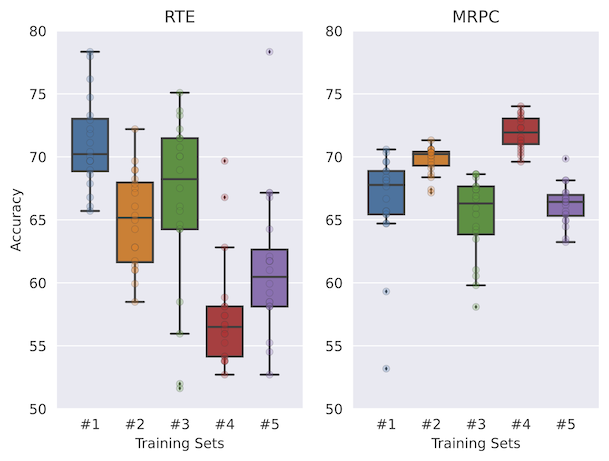
IPUSD, unsere vorgeschlagene Strategie zur Datenauswahl, erreicht für wenige Schienen eine höhere Genauigkeit und schlägt eine viel geringere Varianz bei RTE, SST-2, SST-5, TREC und MRPC vor. Wir zeigen, dass Heuristiken wie zufällige oder höchste Entropie zu einer viel geringeren Leistung führen würden.
Schauen Sie sich die Datenspaltungen für verschiedene aktive Lernstrategien (einschließlich unbeschriebener und Bewertungsdatenspaltungen) im Datasets -Ordner an.
@inproceedings{koksal-etal-2023-meal,
title = "{MEAL}: Stable and Active Learning for Few-Shot Prompting",
author = {K{"o}ksal, Abdullatif and
Schick, Timo and
Schuetze, Hinrich},
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2023",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-emnlp.36",
doi = "10.18653/v1/2023.findings-emnlp.36",
pages = "506--517"
}


