MEAL
1.0.0
El código y los datos para nuestro documento de hallazgos EMNLP 2023: comida (papel).
Nuestros findiciones de llave son:
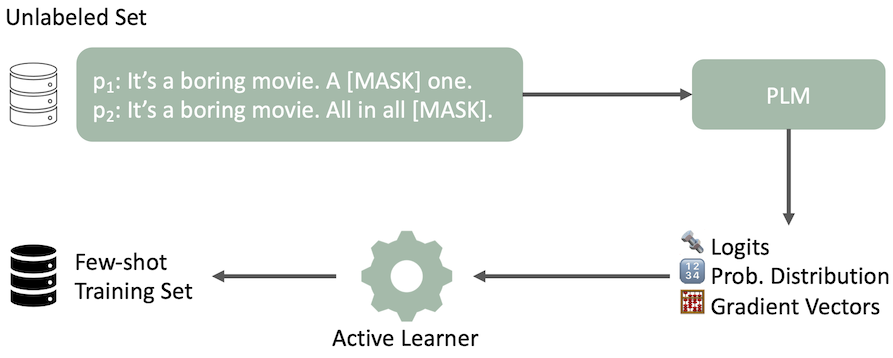 Nuestra tubería de aprendizaje activo modificado para la selección de datos se ilustra con una oración de ejemplo y dos indicaciones para el análisis de sentimientos. El PLM genera varias características de manera cero. Al selecciona un conjunto de entrenamiento de pocos disparos en función de estas características de salida.
Nuestra tubería de aprendizaje activo modificado para la selección de datos se ilustra con una oración de ejemplo y dos indicaciones para el análisis de sentimientos. El PLM genera varias características de manera cero. Al selecciona un conjunto de entrenamiento de pocos disparos en función de estas características de salida.
| ACC ↑ | Rango ↓ | Div. ↑ | Rep. ↑ | Ent. ↓ | |
|---|---|---|---|---|---|
| Aleatorio | 72.6 ± 2.8 | 4.0 | 13.6 | 17.6 | 2.0 |
| Entropía | 70.9 | 6.4 | 13.3 | 16.9 | 6.1 |
| LC | 70.9 | 5.6 | 13.5 | 17.2 | 5.3 |
| Bt | 72.1 | 4.0 | 13.4 | 17.1 | 5.6 |
| PP-KL (nuestro) | 69.1 | 5.6 | 13.4 | 16.9 | 9.0 |
| CALIFORNIA | 70.4 | 4.4 | 13.1 | 17.1 | 23.5 |
| INSIGNIA | 73.2 ± 3.3 | 3.0 | 13.6 | 17.6 | 2.2 |
| Ipusd (nuestro) | 73.9 ± 2.3 | 3.0 | 13.5 | 17.6 | 2.0 |
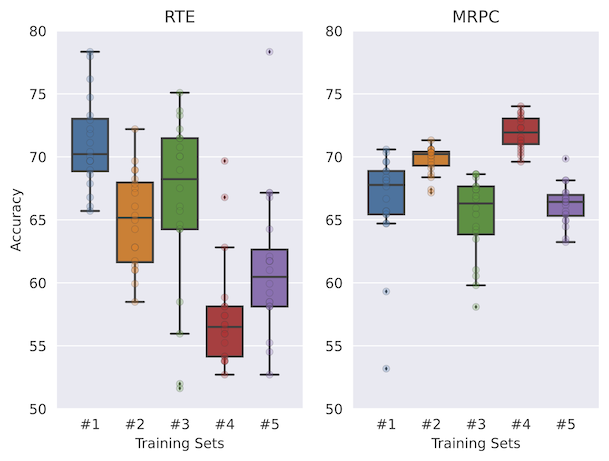
IPUSD, nuestra estrategia de selección de datos propuesta, para pocos disparos, logra una mayor precisión, al tiempo que propone una varianza mucho menor entre RTE, SST-2, SST-5, TREC y MRPC. Mostramos que las heurísticas como la entropía aleatoria o más alta conducirían a un rendimiento mucho más bajo.
Consulte las divisiones de datos para diferentes estrategias de aprendizaje activo (incluidas las divisiones de datos no etiquetadas y de evaluación) en la carpeta DataSets.
@inproceedings{koksal-etal-2023-meal,
title = "{MEAL}: Stable and Active Learning for Few-Shot Prompting",
author = {K{"o}ksal, Abdullatif and
Schick, Timo and
Schuetze, Hinrich},
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2023",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-emnlp.36",
doi = "10.18653/v1/2023.findings-emnlp.36",
pages = "506--517"
}


