MEAL
1.0.0
The code and data for our EMNLP 2023 Findings paper: MEAL (paper).
Our key-findings are:
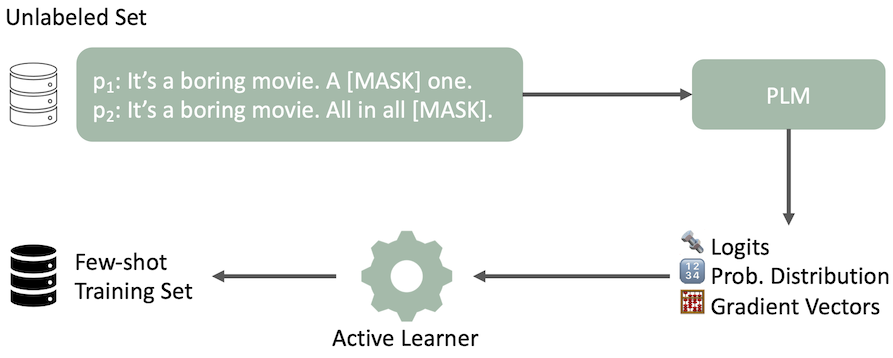 Our modified active learning pipeline for data selection is illustrated with an example sentence and two prompts for sentiment analysis. The PLM outputs several features in a zero-shot manner. AL selects a few-shot training set based on these output features.
Our modified active learning pipeline for data selection is illustrated with an example sentence and two prompts for sentiment analysis. The PLM outputs several features in a zero-shot manner. AL selects a few-shot training set based on these output features.
| Acc ↑ | Rank ↓ | Div. ↑ | Repr. ↑ | Ent. ↓ | |
|---|---|---|---|---|---|
| Random | 72.6±2.8 | 4.0 | 13.6 | 17.6 | 2.0 |
| Entropy | 70.9 | 6.4 | 13.3 | 16.9 | 6.1 |
| LC | 70.9 | 5.6 | 13.5 | 17.2 | 5.3 |
| BT | 72.1 | 4.0 | 13.4 | 17.1 | 5.6 |
| PP-KL (Ours) | 69.1 | 5.6 | 13.4 | 16.9 | 9.0 |
| CAL | 70.4 | 4.4 | 13.1 | 17.1 | 23.5 |
| BADGE | 73.2±3.3 | 3.0 | 13.6 | 17.6 | 2.2 |
| IPUSD (Ours) | 73.9±2.3 | 3.0 | 13.5 | 17.6 | 2.0 |
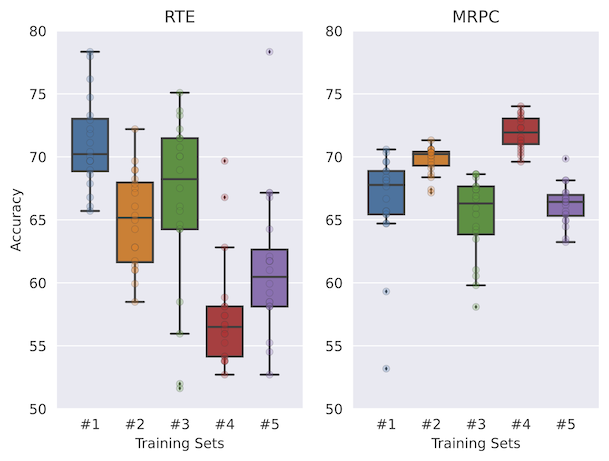
IPUSD, our proposed data selection strategy, for few-shot prompting achieves higher accuracy while proposing much lower variance across RTE, SST-2, SST-5, TREC, and MRPC. We show that heuristics like random or highest entropy would lead to much lower performance.
Check out the data splits for different active learning strategies (including unlabeled and evaluation data splits) in the Datasets folder.
@inproceedings{koksal-etal-2023-meal,
title = "{MEAL}: Stable and Active Learning for Few-Shot Prompting",
author = {K{"o}ksal, Abdullatif and
Schick, Timo and
Schuetze, Hinrich},
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2023",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-emnlp.36",
doi = "10.18653/v1/2023.findings-emnlp.36",
pages = "506--517"
}


