bot on anything
1.1.0

[Inglês] | [中文]
O BOT em qualquer coisa é um poderoso construtor de chatbot da AI que permite criar rapidamente chatbots e executá -los em qualquer lugar.
Os desenvolvedores podem criar e executar um robô de diálogo inteligente selecionando uma conexão entre vários modelos grandes de IA e canais de aplicativos com configuração leve. Ele suporta fácil comutação entre vários caminhos em um único projeto. Essa arquitetura tem forte escalabilidade; Cada aplicativo pode reutilizar os recursos de modelo existentes e cada novo modelo pode ser executado em todos os canais de aplicativos.
Modelos:
Aplicações:
Suporta os sistemas Linux, MacOS e Windows e Python devem ser instalados. Recomenda -se usar a versão Python entre 3.7.1 e 3.10.
Clone o código do projeto e instale dependências:
git clone https://github.com/zhayujie/bot-on-anything
cd bot-on-anything/
pip3 install -r requirements.txt O arquivo de configuração do núcleo é config.json , e um arquivo de modelo config-template.json é fornecido no projeto, que pode ser copiado para gerar o arquivo final eficaz config.json :
cp config-template.json config.jsonCada modelo e canal possuem seu próprio bloco de configuração, que juntos formam um arquivo de configuração completo. A estrutura geral é a seguinte:
{
" model " : {
" type " : " openai " , # Selected AI model
" openai " : {
# openAI configuration
}
},
" channel " : {
" type " : " slack " , # Channel to be integrated
" slack " : {
# slack configuration
},
" telegram " : {
# telegram configuration
}
}
} O arquivo de configuração é dividido nas seções model e channel no nível mais externo. A seção do modelo é para configuração do modelo, onde o type especifica qual modelo usar; A seção de canal contém a configuração para canais de aplicativos, e o campo type especifica qual aplicativo integrar.
Ao usar, você só precisa alterar o campo type em blocos de configuração do modelo e do canal para alternar entre qualquer modelo e aplicativo, conectando caminhos diferentes. Abaixo, cada modelo e configuração de aplicativos e processo de execução serão introduzidos por sua vez.
Execute o seguinte comando no diretório raiz do projeto, com o canal padrão sendo o terminal:
python3 app.py O modelo padrão é gpt-3.5-turbo . Para detalhes, consulte a documentação oficial. Ele também suporta gpt-4.0 , basta modificar o parâmetro do tipo de modelo.
pip3 install --upgrade openaiNota: A versão do OpenAI precisa estar acima de
0.27.0. Se a instalação falhar, você poderá atualizar primeiro o PIP compip3 install --upgrade pip.
{
" model " : {
" type " : " chatgpt " ,
" openai " : {
" api_key " : " YOUR API KEY " ,
" model " : " gpt-3.5-turbo " , # Model name
" proxy " : " http://127.0.0.1:7890 " , # Proxy address
" character_desc " : " You are ChatGPT, a large language model trained by OpenAI, aimed at answering and solving any questions people have, and can communicate in multiple languages. When asked who you are, you should also tell the questioner that entering #clear_memory can start a new topic exploration. Entering draw xx can create a picture for you. " ,
" conversation_max_tokens " : 1000, # Maximum number of characters in the reply, total for input and output
" temperature " :0.75, # Entropy, between [0,1], the larger the value, the more random the selected candidate words, the more uncertain the reply, it is recommended to use either this or the top_p parameter, the greater the creativity task, the better, the smaller the precision task
" top_p " :0.7, # Candidate word list. 0.7 means only considering the top 70% of candidate words, it is recommended to use either this or the temperature parameter
" frequency_penalty " :0.0, # Between [-2,2], the larger this value, the more it reduces the repetition of words in the model's output, leaning towards producing different content
" presence_penalty " :1.0, # Between [-2,2], the larger this value, the less restricted by the input, encouraging the model to generate new words not present in the input, leaning towards producing different content
}
}api_key : Preencha a OpenAI API KEY criada ao registrar sua conta.model : o nome do modelo, atualmente suporta gpt-3.5-turbo , gpt-4 , gpt-4-32k (a API GPT-4 ainda não está aberta).proxy : o endereço do cliente proxy, consulte #56 para obter detalhes.character_desc : Esta configuração salva um texto que você diz para ChatGPT e se lembrará deste texto como sua configuração; Você pode personalizar qualquer personalidade para isso.max_history_num [opcional]: o comprimento máximo da memória da conversa, excedendo esse comprimento limpará a memória anterior.{
" model " : {
" type " : " linkai " ,
" linkai " : {
" api_key " : " " ,
" api_base " : " https://api.link-ai.tech " ,
" app_code " : " " ,
" model " : " " ,
" conversation_max_tokens " : 1000,
" temperature " :0.75,
" top_p " :0.7,
" frequency_penalty " :0.0,
" presence_penalty " :1.0,
" character_desc " : " You are an intelligent assistant. "
},
}api_key : A chave para chamar o serviço Linkai, que pode ser criado no console.app_code : O código para o aplicativo Linkai ou fluxo de trabalho, opcional, consulte a criação do aplicativo.model : suporta modelos comuns de fontes domésticas e internacionais, consulte a lista de modelos. Pode ser deixado em branco e o modelo padrão do aplicativo pode ser modificado na plataforma Linkai. O aplicativo que inicia por padrão no modelo de configuração é o terminal, o que não requer configuração adicional. Você pode iniciar o programa executando python3 app.py diretamente no diretório do projeto. Os usuários interagem com o modelo de diálogo através da entrada da linha de comando e suporta efeitos de resposta de streaming.
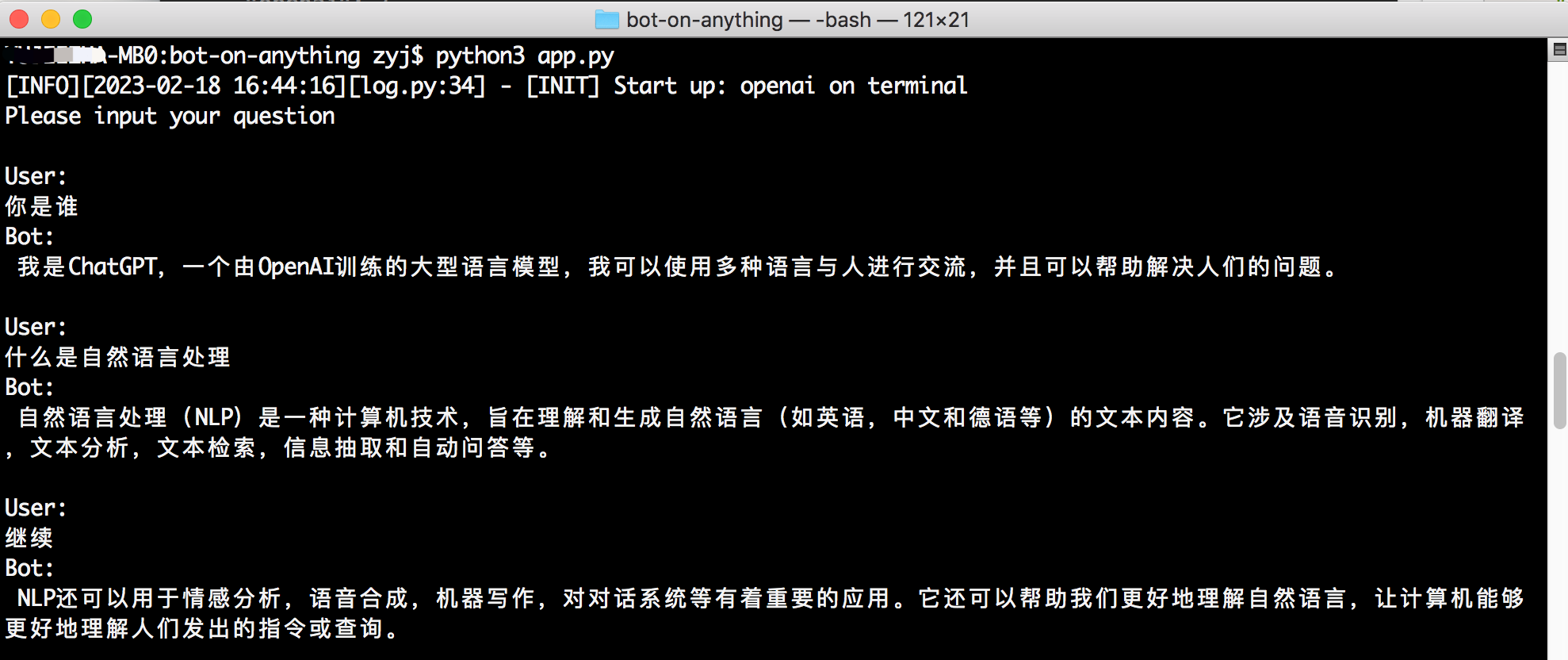
Colaborador: Regimenarsenic
Dependências
pip3 install PyJWT flask flask_socketioConfiguração
" channel " : {
" type " : " http " ,
" http " : {
" http_auth_secret_key " : " 6d25a684-9558-11e9-aa94-efccd7a0659b " , // JWT authentication secret key
" http_auth_password " : " 6.67428e-11 " , // Authentication password, just for personal use, a preliminary defense against others scanning ports and DDOS wasting tokens
" port " : " 80 " // Port
}
} Execute localmente: depois de executar python3 app.py , acesse http://127.0.0.1:80 .
Execute em um servidor: após a implantação, acesse http://public domain or IP:port .
Requisitos: um servidor e uma conta de assinatura.
Instale a dependência WeroBot:
pip3 install werobot " channel " : {
" type " : " wechat_mp " ,
" wechat_mp " : {
" token " : " YOUR TOKEN " , # Token value
" port " : " 8088 " # Port the program listens on
}
} Execute python3 app.py no diretório do projeto. Se o terminal exibir o seguinte, indica uma operação bem -sucedida:
[INFO][2023-02-16 01:39:53][app.py:12] - [INIT] load config: ...
[INFO][2023-02-16 01:39:53][wechat_mp_channel.py:25] - [WX_Public] Wechat Public account service start!
Bottle v0.12.23 server starting up (using AutoServer())...
Listening on http://127.0.0.1:8088/
Hit Ctrl-C to quit.
Vá para a conta de assinatura pessoal na plataforma oficial do WeChat e habilite a configuração do servidor:

Configuração do endereço do servidor (URL) : Se você puder acessar o programa Python no servidor através do URL configurado no navegador (escuta padrão na porta 8088), indica que a configuração é válida. Como a conta de assinatura pode configurar apenas as portas 80/443, você pode modificar a configuração para ouvir diretamente na porta 80 (requer permissões de sudo) ou usar o encaminhamento de proxy reverso (como o nginx). De acordo com a documentação oficial, você pode preencher o IP público ou o nome de domínio aqui.
Configuração do token : Deve ser consistente com o token na configuração config.json .
Para processos de operação detalhados, consulte a documentação oficial.
Depois que os usuários seguem a conta de assinatura, eles podem enviar mensagens.
NOTA: Depois que os usuários enviam mensagens, o back -end do WeChat pressionará para o endereço URL configurado, mas se não houver resposta dentro de 5 segundos, a conexão será desconectada e voltará a tentar novamente. No entanto, a solicitação para a interface OpenAI geralmente leva mais de 5 segundos. Neste projeto, os métodos assíncronos e de cache otimizaram o limite de tempo limite de 5 segundos para 15 segundos, mas excedendo esse tempo ainda não permitirá respostas normais. Ao mesmo tempo, cada vez que a conexão é desconectada após 5 segundos, a estrutura da web reportará um erro, que será otimizado posteriormente.
Requisitos: um servidor e uma conta de serviço certificado.
Na conta do serviço corporativo, a questão do tempo limite de 15 segundos da conta de assinatura pessoal é resolvida pela primeira vez acessando a interface do OpenAI e depois pressionando proativamente o usuário através da interface de atendimento ao cliente. A configuração do modo de desenvolvedor da conta de serviço é semelhante à da conta de assinatura. Para detalhes, consulte a documentação oficial.
A configuração config.json para a conta do serviço Enterprise precisa alterar apenas o tipo para wechat_mp_service , mas o bloco de configuração ainda reutiliza wechat_mp e, além disso, você precisa adicionar dois itens de configuração: app_id e app_secret .
" channel " : {
" type " : " wechat_mp_service " ,
" wechat_mp " : {
" token " : " YOUR TOKEN " , # Token value
" port " : " 8088 " , # Port the program listens on
" app_id " : " YOUR APP ID " , # App ID
" app_secret " : " YOUR APP SECRET " # App secret
}
}Nota: o endereço IP do servidor deve ser configurado na "lista de permissões IP"; Caso contrário, os usuários não receberão mensagens proativamente empurradas.
Requisitos: um PC ou servidor (rede doméstica) e uma conta QQ.
A execução do BOT QQ requer adicionalmente executar um programa go-cqhttp , responsável pelo recebimento e envio de mensagens QQ, enquanto nosso programa bot-on-anything é responsável por acessar o OpenAI para gerar conteúdo de diálogo.
Faça o download do programa de máquinas correspondentes da versão Go-CQHTTP, descompacte-o e coloque o arquivo binário go-cqhttp em nosso diretório bot-on-anything/channel/qq . Um arquivo de configuração config.yml já está preparado aqui; Você só precisa preencher a configuração da conta QQ (conta-uin).
Use aiocqhttp para interagir com o go-cqhttp, execute o seguinte comando para instalar a dependência:
pip3 install aiocqhttp Basta alterar o type no bloco de canais do config.json Configuration File para qq :
" channel " : {
" type " : " qq "
} Primeiro, vá para o diretório raiz do projeto bot-on-anything e corra no Terminal 1:
python3 app.py # This will listen on port 8080 Na segunda etapa, aberto Terminal 2, navegue até o diretório em que cqhttp está localizado e execute:
cd channel/qq
./go-cqhttpObservação:
protocol no arquivo device.json no mesmo diretório que o Go-Cqhttp de 5 para 2, consulte este problema.Colaborador: Brucelt1993
6.1 Obtenha token
A solicitação de um bot de telegrama pode ser facilmente encontrada no Google; O importante é obter o ID do token do bot.
6.2 Instalação de dependência
pip install pyTelegramBotAPI6.3 Configuração
" channel " : {
" type " : " telegram " ,
" telegram " :{
" bot_token " : " YOUR BOT TOKEN ID "
}
}Requisitos: um servidor e uma conta do Gmail.
Colaborador: Simon
Siga a documentação oficial para criar uma senha de aplicativo para sua conta do Google, configure como abaixo e depois aplaude !!!
" channel " : {
" type " : " gmail " ,
" gmail " : {
" subject_keyword " : [ " bot " , " @bot " ],
" host_email " : " [email protected] " ,
" host_password " : " GMAIL ACCESS KEY "
}
}❉ Não requer mais um servidor ou IP público
Colaborador: Amaoo
Dependências
pip3 install slack_boltConfiguração
" channel " : {
" type " : " slack " ,
" slack " : {
" slack_bot_token " : " xoxb-xxxx " ,
" slack_app_token " : " xapp-xxxx "
}
}Defina o escopo do token de bot - oauth e permissão
Escreva o token OAuth do usuário do BOT no arquivo de configuração slack_bot_token .
app_mentions:read
chat:write
Ativar modo de soquete - modo de soquete
Se você não criou um token no nível do aplicativo, será solicitado a criar um. Escreva o token criado no arquivo de configuração slack_app_token .
Assinatura do evento (assinaturas de eventos) - Inscreva -se em eventos de bot
app_mention
Documentação de referência
https://slack.dev/bolt-python/tutorial/getting-started
Requisitos:
Dependências
pip3 install requests flaskConfiguração
" channel " : {
" type " : " dingtalk " ,
" dingtalk " : {
" image_create_prefix " : [ " draw " , " draw " , " Draw " ],
" port " : " 8081 " , # External port
" dingtalk_token " : " xx " , # Access token of the webhook address
" dingtalk_post_token " : " xx " , # Verification token carried in the header when DingTalk posts back messages
" dingtalk_secret " : " xx " # Security encryption signature string in the group robot
}
}Documentação de referência :
Gerar robô
Endereço: https://open-dev.dingtalk.com/fe/app#/corp/robot Adicione um robô, defina o IP de saída do servidor no gerenciamento de desenvolvimento e o endereço de recebimento da mensagem (o endereço externo na configuração, como https://xx.xx.com.8081).
Dependências
pip3 install requests flaskConfiguração
" channel " : {
" type " : " feishu " ,
" feishu " : {
" image_create_prefix " : [
" draw " ,
" draw " ,
" Draw "
],
" port " : " 8082 " , # External port
" app_id " : " xxx " , # Application app_id
" app_secret " : " xxx " , # Application Secret
" verification_token " : " xxx " # Event subscription Verification Token
}
}Gerar robô
Endereço: https://open.feishu.cn/app/
Requisitos: um servidor e uma empresa certificada WeChat.
A configuração config.json para o WeChat do Enterprise só precisa alterar o tipo para wechat_com , com a mensagem padrão de recebimento URL do servidor: http: // ip: 8888/weChat.
" channel " : {
" type " : " wechat_com " ,
" wechat_com " : {
" wechat_token " : " YOUR TOKEN " , # Token value
" port " : " 8888 " , # Port the program listens on
" app_id " : " YOUR APP ID " , # App ID
" app_secret " : " YOUR APP SECRET " , # App secret
" wechat_corp_id " : " YOUR CORP ID " ,
" wechat_encoding_aes_key " : " YOUR AES KEY "
}
}Nota: o endereço IP do servidor deve ser configurado na lista "Enterprise Trusted IP"; Caso contrário, os usuários não receberão mensagens proativamente empurradas.
Documentação de referência :
clear_memory_commands : Diálogo Comandos internos Para limpar ativamente a memória anterior, a matriz da string pode personalizar aliases de comando.

