bot on anything
1.1.0

[Anglais] | [中文]
Bot sur tout est un puissant constructeur de chatbot AI qui vous permet de construire rapidement des chatbots et de les exécuter n'importe où.
Les développeurs peuvent créer et exécuter un robot de dialogue intelligent en sélectionnant une connexion entre divers modèles AI et canaux d'application avec une configuration légère. Il prend en charge une commutation facile entre plusieurs chemins dans un seul projet. Cette architecture a une forte évolutivité; Chaque application peut réutiliser les capacités du modèle existant et chaque nouveau modèle peut s'exécuter sur tous les canaux d'application.
Modèles:
Applications:
Prend en charge les systèmes Linux, MacOS et Windows, et Python doit être installé. Il est recommandé d'utiliser la version Python entre 3.7.1 et 3.10.
Clone le code de projet et les dépendances d'installation:
git clone https://github.com/zhayujie/bot-on-anything
cd bot-on-anything/
pip3 install -r requirements.txt Le fichier de configuration de base est config.json , et un fichier de modèle config-template.json est fourni dans le projet, qui peut être copié pour générer le fichier config.json efficace final:
cp config-template.json config.jsonChaque modèle et canal a son propre bloc de configuration, qui forment ensemble un fichier de configuration complet. La structure globale est la suivante:
{
" model " : {
" type " : " openai " , # Selected AI model
" openai " : {
# openAI configuration
}
},
" channel " : {
" type " : " slack " , # Channel to be integrated
" slack " : {
# slack configuration
},
" telegram " : {
# telegram configuration
}
}
} Le fichier de configuration est divisé en sections model et channel au niveau le plus extérieur. La section du modèle est destinée à la configuration du modèle, où le type spécifie le modèle à utiliser; La section de canal contient la configuration des canaux d'application et le champ type spécifie quelle application intégrer.
Lorsque vous utilisez, il vous suffit de modifier le champ type sous le modèle et les blocs de configuration des canaux pour basculer entre n'importe quel modèle et application, en connectant différents chemins. Ci-dessous, chaque modèle et configuration d'application et processus d'exécution seront introduits à leur tour.
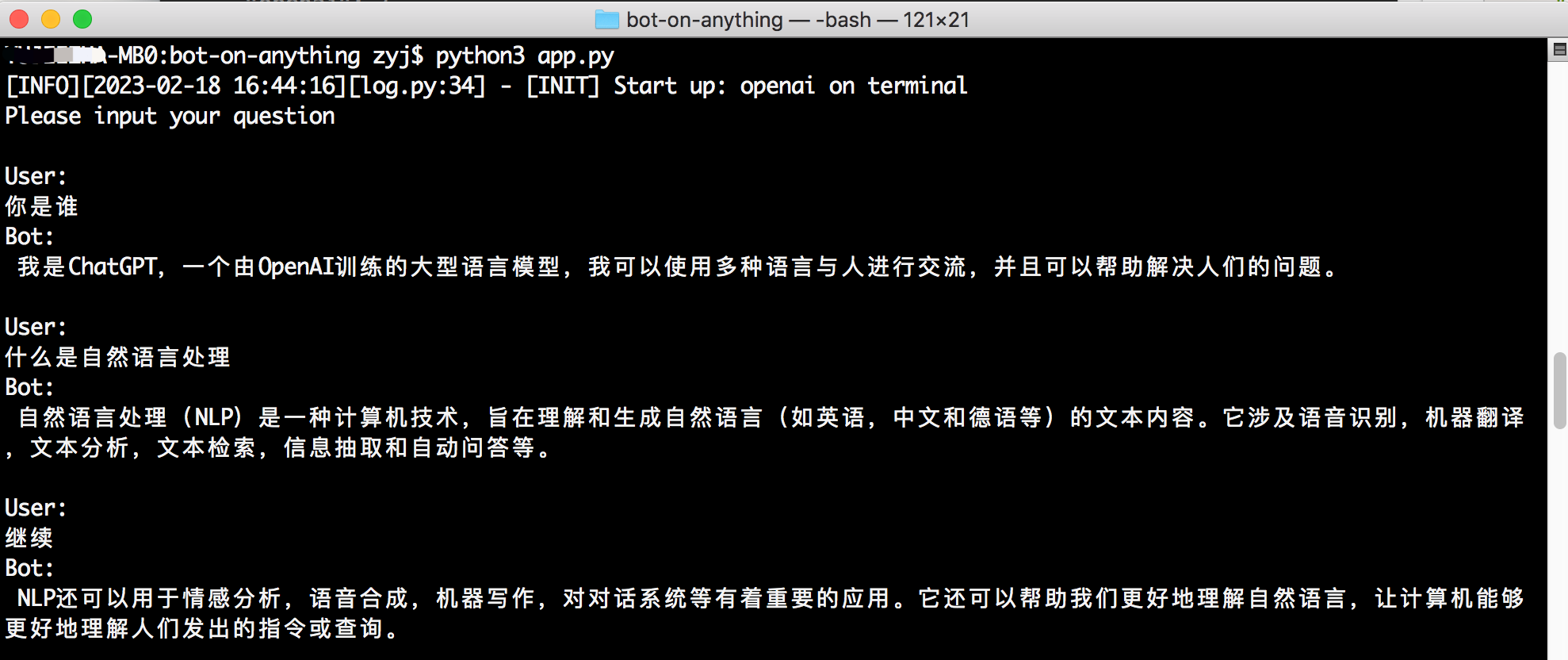
Exécutez la commande suivante dans le répertoire racine du projet, le canal par défaut étant le terminal:
python3 app.py Le modèle par défaut est gpt-3.5-turbo . Pour plus de détails, reportez-vous à la documentation officielle. Il prend également en charge gpt-4.0 , il suffit de modifier le paramètre de type de modèle.
pip3 install --upgrade openaiRemarque: La version OpenAI doit être supérieure à
0.27.0. En cas d'échec de l'installation, vous pouvez d'abord mettre à niveau PIP avecpip3 install --upgrade pip.
{
" model " : {
" type " : " chatgpt " ,
" openai " : {
" api_key " : " YOUR API KEY " ,
" model " : " gpt-3.5-turbo " , # Model name
" proxy " : " http://127.0.0.1:7890 " , # Proxy address
" character_desc " : " You are ChatGPT, a large language model trained by OpenAI, aimed at answering and solving any questions people have, and can communicate in multiple languages. When asked who you are, you should also tell the questioner that entering #clear_memory can start a new topic exploration. Entering draw xx can create a picture for you. " ,
" conversation_max_tokens " : 1000, # Maximum number of characters in the reply, total for input and output
" temperature " :0.75, # Entropy, between [0,1], the larger the value, the more random the selected candidate words, the more uncertain the reply, it is recommended to use either this or the top_p parameter, the greater the creativity task, the better, the smaller the precision task
" top_p " :0.7, # Candidate word list. 0.7 means only considering the top 70% of candidate words, it is recommended to use either this or the temperature parameter
" frequency_penalty " :0.0, # Between [-2,2], the larger this value, the more it reduces the repetition of words in the model's output, leaning towards producing different content
" presence_penalty " :1.0, # Between [-2,2], the larger this value, the less restricted by the input, encouraging the model to generate new words not present in the input, leaning towards producing different content
}
}api_key : Remplissez la OpenAI API KEY créée lors de l'enregistrement de votre compte.model : Nom du modèle, prend actuellement en charge gpt-3.5-turbo , gpt-4 , gpt-4-32k (l'API GPT-4 n'est pas encore ouverte).proxy : l'adresse du client proxy, reportez-vous à # 56 pour plus de détails.character_desc : cette configuration enregistre un texte que vous dites à chatgpt, et il se souviendra de ce texte comme son paramètre; Vous pouvez personnaliser n'importe quelle personnalité pour cela.max_history_num [facultatif]: longueur de mémoire maximale de la conversation, dépassant cette longueur effacera la mémoire précédente.{
" model " : {
" type " : " linkai " ,
" linkai " : {
" api_key " : " " ,
" api_base " : " https://api.link-ai.tech " ,
" app_code " : " " ,
" model " : " " ,
" conversation_max_tokens " : 1000,
" temperature " :0.75,
" top_p " :0.7,
" frequency_penalty " :0.0,
" presence_penalty " :1.0,
" character_desc " : " You are an intelligent assistant. "
},
}api_key : la clé pour appeler le service Linkai, qui peut être créé dans la console.app_code : le code de l'application ou du workflow Linkai, facultatif, reportez-vous à la création d'application.model : prend en charge les modèles communs provenant de sources nationales et internationales, reportez-vous à la liste des modèles. Il peut être laissé vide et le modèle par défaut de l'application peut être modifié dans la plate-forme Linkai. L'application qui démarre par défaut dans le modèle de configuration est le terminal, qui ne nécessite aucune configuration supplémentaire. Vous pouvez démarrer le programme en exécutant python3 app.py directement dans le répertoire du projet. Les utilisateurs interagissent avec le modèle de dialogue via l'entrée de la ligne de commande, et il prend en charge les effets de réponse en streaming.
Contributeur: régimersenic
Dépendances
pip3 install PyJWT flask flask_socketioConfiguration
" channel " : {
" type " : " http " ,
" http " : {
" http_auth_secret_key " : " 6d25a684-9558-11e9-aa94-efccd7a0659b " , // JWT authentication secret key
" http_auth_password " : " 6.67428e-11 " , // Authentication password, just for personal use, a preliminary defense against others scanning ports and DDOS wasting tokens
" port " : " 80 " // Port
}
} Exécutez localement: après l'exécution python3 app.py , accédez http://127.0.0.1:80 .
Exécutez sur un serveur: après déploiement, accédez http://public domain or IP:port .
Exigences: un serveur et un compte d'abonnement.
Installez la dépendance Werobot:
pip3 install werobot " channel " : {
" type " : " wechat_mp " ,
" wechat_mp " : {
" token " : " YOUR TOKEN " , # Token value
" port " : " 8088 " # Port the program listens on
}
} Exécutez python3 app.py dans le répertoire du projet. Si le terminal affiche ce qui suit, il indique un fonctionnement réussi:
[INFO][2023-02-16 01:39:53][app.py:12] - [INIT] load config: ...
[INFO][2023-02-16 01:39:53][wechat_mp_channel.py:25] - [WX_Public] Wechat Public account service start!
Bottle v0.12.23 server starting up (using AutoServer())...
Listening on http://127.0.0.1:8088/
Hit Ctrl-C to quit.
Accédez au compte d'abonnement personnel dans la plate-forme officielle de WeChat et activez la configuration du serveur:

Configuration de l'adresse du serveur (URL) : Si vous pouvez accéder au programme Python sur le serveur via l'URL configuré dans le navigateur (écoute par défaut sur le port 8088), il indique que la configuration est valide. Étant donné que le compte d'abonnement ne peut configurer que les ports 80/443, vous pouvez modifier la configuration pour écouter directement sur le port 80 (nécessite des autorisations sudo) ou utiliser le transfert proxy inversé (comme Nginx). Selon la documentation officielle, vous pouvez remplir ici le nom public IP ou le nom de domaine.
Configuration du jeton : doit être cohérent avec le jeton dans la configuration config.json .
Pour les processus d'exploitation détaillés, reportez-vous à la documentation officielle.
Une fois que les utilisateurs ont suivi le compte d'abonnement, ils peuvent envoyer des messages.
Remarque: Une fois que les utilisateurs ont envoyé des messages, le backend WeCHAT poussera à l'adresse URL configurée, mais s'il n'y a pas de réponse dans les 5 secondes, la connexion sera déconnectée et elle réessayera 3 fois. Cependant, la demande à l'interface OpenAI prend souvent plus de 5 secondes. Dans ce projet, les méthodes asynchrones et de mise en cache ont optimisé la limite de délai d'expiration des 5 secondes à 15 secondes, mais dépasser cette fois ne permettra toujours pas les réponses normales. Dans le même temps, chaque fois que la connexion est déconnectée après 5 secondes, le framework Web rapportera une erreur, qui sera optimisée plus tard.
Exigences: un serveur et un compte de service certifié.
Dans le compte de service Enterprise, le problème de délai d'expiration des 15 secondes du compte d'abonnement personnel est résolu en accédant d'abord de manière asynchrone à l'interface OpenAI, puis en poussant de manière proactive à l'utilisateur via l'interface du service client. La configuration en mode développeur du compte de service est similaire à celle du compte d'abonnement. Pour plus de détails, reportez-vous à la documentation officielle.
La configuration config.json pour le compte de service Enterprise n'a besoin que de modifier le type vers wechat_mp_service , mais le bloc de configuration réutilise toujours wechat_mp , et en plus, vous devez ajouter deux éléments de configuration: app_id et app_secret .
" channel " : {
" type " : " wechat_mp_service " ,
" wechat_mp " : {
" token " : " YOUR TOKEN " , # Token value
" port " : " 8088 " , # Port the program listens on
" app_id " : " YOUR APP ID " , # App ID
" app_secret " : " YOUR APP SECRET " # App secret
}
}Remarque: L'adresse IP du serveur doit être configurée dans la "liste blanche IP"; Sinon, les utilisateurs ne recevront pas de messages poussés de manière proactive.
Exigences: un PC ou un serveur (réseau domestique) et un compte QQ.
L'exécution du bot QQ nécessite en plus d'exécuter un programme go-cqhttp , qui est responsable de la réception et de l'envoi de messages QQ, tandis que notre programme bot-on-anything est responsable de l'accès à OpenAI pour générer du contenu de dialogue.
Téléchargez le programme Machine correspondant à partir de la version Go-CQHTTP, dézip-le et placez le fichier binaire go-cqhttp dans notre répertoire bot-on-anything/channel/qq . Un fichier de configuration config.yml est déjà préparé ici; Il vous suffit de remplir la configuration du compte QQ (compte-Uin).
Utilisez AIOCQHTTP pour interagir avec GO-CQHTTP, exécutez la commande suivante pour installer la dépendance:
pip3 install aiocqhttp Modifiez simplement le type dans le bloc de canal du fichier de configuration config.json en qq :
" channel " : {
" type " : " qq "
} Tout d'abord, accédez au répertoire racine du projet bot-on-anything et exécutez dans la borne 1:
python3 app.py # This will listen on port 8080 Dans la deuxième étape, Open Terminal 2, accédez au répertoire où se trouve cqhttp et exécutez:
cd channel/qq
./go-cqhttpNote:
protocol dans le fichier device.json dans le même répertoire que Go-CQHTTP de 5 à 2, reportez-vous à ce problème.Contributeur: Brucelt1993
6.1 Get Token
La demande de bot télégramme peut être facilement trouvée sur Google; L'important est d'obtenir le jeton du bot.
6.2 Installation de dépendance
pip install pyTelegramBotAPI6.3 Configuration
" channel " : {
" type " : " telegram " ,
" telegram " :{
" bot_token " : " YOUR BOT TOKEN ID "
}
}Exigences: un serveur et un compte Gmail.
Contributeur: Simon
Suivez la documentation officielle pour créer un mot de passe d'application pour votre compte Google, configurez-vous comme ci-dessous, puis applaudis !!!
" channel " : {
" type " : " gmail " ,
" gmail " : {
" subject_keyword " : [ " bot " , " @bot " ],
" host_email " : " [email protected] " ,
" host_password " : " GMAIL ACCESS KEY "
}
}❉ Ne nécessite plus un serveur ou une propriété intellectuelle publique
Contributeur: AMAOO
Dépendances
pip3 install slack_boltConfiguration
" channel " : {
" type " : " slack " ,
" slack " : {
" slack_bot_token " : " xoxb-xxxx " ,
" slack_app_token " : " xapp-xxxx "
}
}Définir la portée du jeton de bot - OAuth et autorisation
Écrivez le token Bot User Oauth dans le fichier de configuration slack_bot_token .
app_mentions:read
chat:write
Activer le mode Socket - Mode Socket
Si vous n'avez pas créé de jeton au niveau de l'application, vous serez invité à en créer un. Écrivez le jeton créé dans le fichier de configuration slack_app_token .
Abonnement à l'événement (abonnements à l'événement) - Abonnez-vous aux événements BOT
app_mention
Documentation de référence
https://slack.dev/bolt-python/tutorial/getting-started
Exigences:
Dépendances
pip3 install requests flaskConfiguration
" channel " : {
" type " : " dingtalk " ,
" dingtalk " : {
" image_create_prefix " : [ " draw " , " draw " , " Draw " ],
" port " : " 8081 " , # External port
" dingtalk_token " : " xx " , # Access token of the webhook address
" dingtalk_post_token " : " xx " , # Verification token carried in the header when DingTalk posts back messages
" dingtalk_secret " : " xx " # Security encryption signature string in the group robot
}
}Documentation de référence :
Générer un robot
Adresse: https://open-dev.dingtalk.com/fe/app#/corp/robot Ajoutez un robot, définissez l'IP sortant du serveur dans la gestion du développement et l'adresse de réception du message (l'adresse externe dans la configuration, telles que https://xx.xx.com:8081).
Dépendances
pip3 install requests flaskConfiguration
" channel " : {
" type " : " feishu " ,
" feishu " : {
" image_create_prefix " : [
" draw " ,
" draw " ,
" Draw "
],
" port " : " 8082 " , # External port
" app_id " : " xxx " , # Application app_id
" app_secret " : " xxx " , # Application Secret
" verification_token " : " xxx " # Event subscription Verification Token
}
}Générer un robot
Adresse: https://open.feishu.cn/app/
Exigences: un serveur et une entreprise certifiée WeChat.
La configuration config.json pour Enterprise WeChat n'a besoin que de modifier le type vers wechat_com , avec l'URL du serveur de réception par défaut: http: // ip: 8888 / wechat.
" channel " : {
" type " : " wechat_com " ,
" wechat_com " : {
" wechat_token " : " YOUR TOKEN " , # Token value
" port " : " 8888 " , # Port the program listens on
" app_id " : " YOUR APP ID " , # App ID
" app_secret " : " YOUR APP SECRET " , # App secret
" wechat_corp_id " : " YOUR CORP ID " ,
" wechat_encoding_aes_key " : " YOUR AES KEY "
}
}Remarque: L'adresse IP du serveur doit être configurée dans la liste "IP de confiance en entreprise"; Sinon, les utilisateurs ne recevront pas de messages poussés de manière proactive.
Documentation de référence :
clear_memory_commands : Dialogue Commandes internes Pour effacer activement la mémoire précédente, le tableau de chaîne peut personnaliser les alias de commande.

