bot on anything
1.1.0

[Englisch] | [中文]
Bot on Everything ist ein leistungsstarker KI -Chatbot -Builder, mit dem Sie schnell Chatbots erstellen und überall ausführen können.
Entwickler können einen intelligenten Dialogroboter erstellen und ausführen, indem sie eine Verbindung zwischen verschiedenen AI -Modellen und Anwendungskanälen mit leichtem Konfiguration auswählen. Es unterstützt das einfache Umschalten zwischen mehreren Pfaden innerhalb eines einzelnen Projekts. Diese Architektur hat eine starke Skalierbarkeit; Jede Anwendung kann vorhandene Modellfunktionen wiederverwenden und jedes neue Modell kann auf allen Anwendungskanälen ausgeführt werden.
Modelle:
Anwendungen:
Unterstützt Linux-, MacOS- und Windows -Systeme, und Python muss installiert werden. Es wird empfohlen, die Python -Version zwischen 3.7.1 und 3.10 zu verwenden.
Klonen Sie den Projektcode und installieren Sie Abhängigkeiten:
git clone https://github.com/zhayujie/bot-on-anything
cd bot-on-anything/
pip3 install -r requirements.txt Die Kernkonfigurationsdatei ist config.json , und im Projekt wird ein Vorlagendatei config-template.json bereitgestellt, der kopiert werden kann, um die endgültige effektive config.json Datei zu generieren:
cp config-template.json config.jsonJedes Modell und jeder Kanal verfügt über einen eigenen Konfigurationsblock, der zusammen eine vollständige Konfigurationsdatei bildet. Die Gesamtstruktur ist wie folgt:
{
" model " : {
" type " : " openai " , # Selected AI model
" openai " : {
# openAI configuration
}
},
" channel " : {
" type " : " slack " , # Channel to be integrated
" slack " : {
# slack configuration
},
" telegram " : {
# telegram configuration
}
}
} Die Konfigurationsdatei ist in model und channel auf der äußersten Ebene unterteilt. Der Modellabschnitt dient für die Modellkonfiguration, wobei der type angibt, welches Modell verwendet werden. Der Kanalabschnitt enthält die Konfiguration für Anwendungskanäle, und das Feld type gibt an, welche Anwendung integriert werden soll.
Bei der Verwendung müssen Sie das Feld type und Kanalkonfigurationsblöcke nur ändern, um zwischen Modell und Anwendung zu wechseln und verschiedene Pfade zu verbinden. Im Folgenden werden jede Modell- und Anwendungskonfiguration sowie der Auslaufprozess nacheinander eingeführt.
Führen Sie den folgenden Befehl im Projekt Root -Verzeichnis aus, wobei der Standardkanal das Terminal ist:
python3 app.py Das Standardmodell ist gpt-3.5-turbo . Weitere Informationen finden Sie in der offiziellen Dokumentation. Es unterstützt auch gpt-4.0 . Ändern Sie einfach den Modelltypparameter.
pip3 install --upgrade openaiHinweis: Die OpenAI -Version muss über
0.27.0liegen. Wenn die Installation fehlschlägt, können Sie PIP zuerst mitpip3 install --upgrade pipaufrüsten.
{
" model " : {
" type " : " chatgpt " ,
" openai " : {
" api_key " : " YOUR API KEY " ,
" model " : " gpt-3.5-turbo " , # Model name
" proxy " : " http://127.0.0.1:7890 " , # Proxy address
" character_desc " : " You are ChatGPT, a large language model trained by OpenAI, aimed at answering and solving any questions people have, and can communicate in multiple languages. When asked who you are, you should also tell the questioner that entering #clear_memory can start a new topic exploration. Entering draw xx can create a picture for you. " ,
" conversation_max_tokens " : 1000, # Maximum number of characters in the reply, total for input and output
" temperature " :0.75, # Entropy, between [0,1], the larger the value, the more random the selected candidate words, the more uncertain the reply, it is recommended to use either this or the top_p parameter, the greater the creativity task, the better, the smaller the precision task
" top_p " :0.7, # Candidate word list. 0.7 means only considering the top 70% of candidate words, it is recommended to use either this or the temperature parameter
" frequency_penalty " :0.0, # Between [-2,2], the larger this value, the more it reduces the repetition of words in the model's output, leaning towards producing different content
" presence_penalty " :1.0, # Between [-2,2], the larger this value, the less restricted by the input, encouraging the model to generate new words not present in the input, leaning towards producing different content
}
}api_key : Füllen Sie die OpenAI API KEY aus, die bei der Registrierung Ihres Kontos erstellt wurde.model : Modellname, derzeit unterstützt gpt-3.5-turbo , gpt-4 , gpt-4-32k (die GPT-4-API ist noch nicht geöffnet).proxy : Die Adresse des Proxy -Clients finden Sie in #56 für Einzelheiten.character_desc : Diese Konfiguration spart einen Text, den Sie Chatgpt sagen, und erinnert sich an diesen Text als seine Einstellung. Sie können jede Persönlichkeit dafür anpassen.max_history_num [Optional]: Die maximale Speicherlänge der Konversation, die diese Länge überschreitet, löscht den vorherigen Speicher.{
" model " : {
" type " : " linkai " ,
" linkai " : {
" api_key " : " " ,
" api_base " : " https://api.link-ai.tech " ,
" app_code " : " " ,
" model " : " " ,
" conversation_max_tokens " : 1000,
" temperature " :0.75,
" top_p " :0.7,
" frequency_penalty " :0.0,
" presence_penalty " :1.0,
" character_desc " : " You are an intelligent assistant. "
},
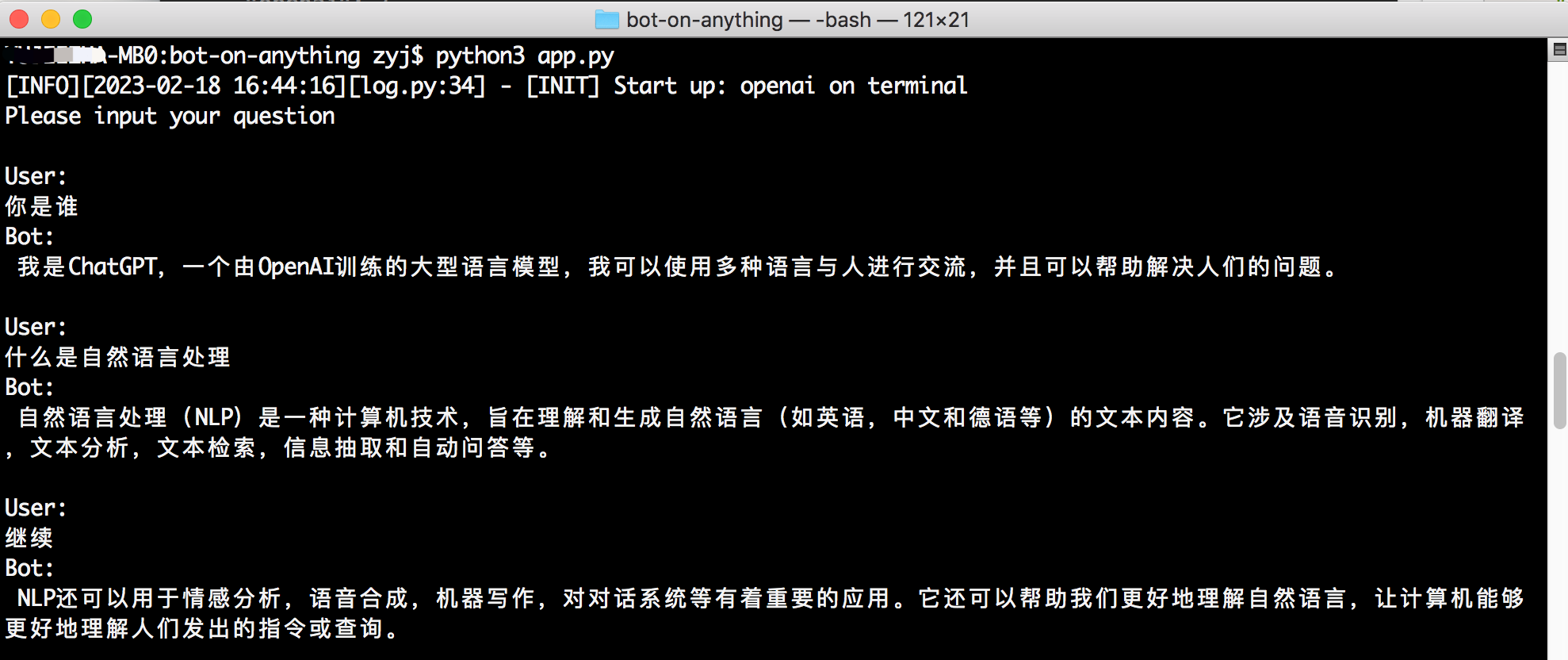
}api_key : Der Schlüssel zum Aufrufen des Linkai -Dienstes, der in der Konsole erstellt werden kann.app_code : Der Code für die linkai -Anwendung oder den optionalen Linkai -Anwendung oder die Erstellung von Anwendungen.model : Unterstützt gemeinsame Modelle sowohl aus nationalen als auch aus internationalen Quellen, siehe Modellliste. Es kann leer bleiben und das Standardmodell der Anwendung kann in der Linkai -Plattform geändert werden. Die Anwendung, die standardmäßig in der Konfigurationsvorlage startet, ist das Terminal, für das keine zusätzliche Konfiguration erforderlich ist. Sie können das Programm starten, indem Sie python3 app.py direkt im Projektverzeichnis ausführen. Benutzer interagieren mit dem Dialogmodell über die Befehlszeileneingabe und unterstützt Streaming -Antworteffekte.
Mitwirkender: Regimearsen
Abhängigkeiten
pip3 install PyJWT flask flask_socketioKonfiguration
" channel " : {
" type " : " http " ,
" http " : {
" http_auth_secret_key " : " 6d25a684-9558-11e9-aa94-efccd7a0659b " , // JWT authentication secret key
" http_auth_password " : " 6.67428e-11 " , // Authentication password, just for personal use, a preliminary defense against others scanning ports and DDOS wasting tokens
" port " : " 80 " // Port
}
} Laufen Sie lokal aus: Nachdem Sie python3 app.py ausgeführt haben, greifen Sie auf http://127.0.0.1:80 .
Ausführen auf einem Server: Greifen Sie nach der Bereitstellung http://public domain or IP:port zu.
Anforderungen: Ein Server und ein Abonnementkonto.
Installieren Sie die Werobot -Abhängigkeit:
pip3 install werobot " channel " : {
" type " : " wechat_mp " ,
" wechat_mp " : {
" token " : " YOUR TOKEN " , # Token value
" port " : " 8088 " # Port the program listens on
}
} Führen Sie python3 app.py im Projektverzeichnis aus. Wenn das Terminal Folgendes anzeigt, zeigt es einen erfolgreichen Betrieb an:
[INFO][2023-02-16 01:39:53][app.py:12] - [INIT] load config: ...
[INFO][2023-02-16 01:39:53][wechat_mp_channel.py:25] - [WX_Public] Wechat Public account service start!
Bottle v0.12.23 server starting up (using AutoServer())...
Listening on http://127.0.0.1:8088/
Hit Ctrl-C to quit.
Gehen Sie zum persönlichen Abonnementkonto in der offiziellen WeChat -Plattform und aktivieren Sie die Serverkonfiguration:

Konfiguration des Serveradresses (URL) : Wenn Sie über die konfigurierte URL im Browser auf das Python -Programm auf dem Server zugreifen können (Standardhörer auf Port 8088), wird angezeigt, dass die Konfiguration gültig ist. Da das Abonnementkonto nur die Ports 80/443 konfigurieren kann, können Sie die Konfiguration so ändern, dass sie direkt auf Port 80 anhören (sudo -Berechtigungen erfordert) oder die Reverse -Proxy -Weiterleitung (wie nginx) verwenden. Nach der offiziellen Dokumentation können Sie hier entweder den öffentlichen IP- oder den Domainnamen ausfüllen.
Token -Konfiguration : Muss mit dem Token in der config.json übereinstimmen.
Detaillierte Betriebsprozesse finden Sie in der offiziellen Dokumentation.
Nachdem Benutzer dem Abonnementkonto folgt, können sie Nachrichten senden.
HINWEIS: Nachdem Benutzer Nachrichten gesendet haben, wird das WeChat -Backend in die konfigurierte URL -Adresse weitergegeben. Wenn jedoch keine Antwort innerhalb von 5 Sekunden vorliegt, wird die Verbindung getrennt und dreimal wiederholt. Die Anfrage an die OpenAI -Schnittstelle dauert jedoch häufig mehr als 5 Sekunden. In diesem Projekt haben asynchrone und Caching-Methoden die 5-Sekunden-Zeitüberschreitungsgrenze auf 15 Sekunden optimiert, aber über diesen Zeitpunkt wird jedoch immer noch keine normalen Antworten zulässig. Gleichzeitig wird das Web -Framework jedes Mal, wenn die Verbindung nach 5 Sekunden getrennt wird, einen Fehler meldet, der später optimiert wird.
Anforderungen: Ein Server und ein zertifiziertes Servicekonto.
Im Enterprise Service-Konto wird das 15-Sekunden-Zeitübergangsproblem des persönlichen Abonnementkontos durch den zuerst asynchronen Zugriff auf die OpenAI-Schnittstelle behoben und dann proaktiv über die Kundendienstschnittstelle an den Benutzer weitergegeben. Die Konfiguration des Entwicklermodus des Dienstkontos ähnelt dem des Abonnementkontos. Weitere Informationen finden Sie in der offiziellen Dokumentation.
Die config.json für das Enterprise Service -Konto muss den Typ nur in wechat_mp_service ändern. Der Konfigurationsblock wiederverwendet weiterhin wechat_mp und zusätzlich müssen Sie zwei Konfigurationselemente hinzufügen: app_id und app_secret .
" channel " : {
" type " : " wechat_mp_service " ,
" wechat_mp " : {
" token " : " YOUR TOKEN " , # Token value
" port " : " 8088 " , # Port the program listens on
" app_id " : " YOUR APP ID " , # App ID
" app_secret " : " YOUR APP SECRET " # App secret
}
}Hinweis: Die Server -IP -Adresse muss in der "IP -Whitelist" konfiguriert werden. Andernfalls erhalten Benutzer keine proaktiv gedrückten Nachrichten.
Anforderungen: Ein PC oder Server (inländisches Netzwerk) und ein QQ -Konto.
Das Ausführen des QQ Bot erfordert zusätzlich ein go-cqhttp -Programm, das für das Empfangen und Senden von QQ-Nachrichten verantwortlich ist, während unser bot-on-anything -Programm für den Zugriff auf OpenAI verantwortlich ist, um Dialoginhalte zu generieren.
Laden Sie das entsprechende Maschinenprogramm von der Go-CQHTTP-Version herunter, entpacken Sie es und platzieren Sie die go-cqhttp Binärdatei in unserem Verzeichnis bot-on-anything/channel/qq . Eine config.yml ist bereits hier erstellt. Sie müssen nur die QQ-Kontokonfiguration (Account-Uin) ausfüllen.
Verwenden Sie AIOCQHTTP, um mit GO-CQHTTP zu interagieren, und führen Sie den folgenden Befehl aus, um die Abhängigkeit zu installieren:
pip3 install aiocqhttp Ändern Sie einfach den type in den Kanalblock der config.json -Konfigurationsdatei in qq :
" channel " : {
" type " : " qq "
} Gehen Sie zunächst zum Root-Verzeichnis des bot-on-anything Projekts und führen Sie in Terminal 1 aus:
python3 app.py # This will listen on port 8080 Navigieren Sie im zweiten Schritt offener Terminal 2 zu dem Verzeichnis, in dem sich cqhttp befindet, und laufen Sie:
cd channel/qq
./go-cqhttpNotiz:
protocol in der Datei " device.json in demselben Verzeichnis wie GO-CQHTTP von 5 bis 2 ändern, siehe dieses Problem.Mitwirkender: Brucelt1993
6.1 Token bekommen
Die Beantragung eines Telegrammbots kann leicht bei Google gefunden werden. Das Wichtigste ist, die Token -ID des Bots zu erhalten.
6.2 Abhängigkeitsinstallation
pip install pyTelegramBotAPI6.3 Konfiguration
" channel " : {
" type " : " telegram " ,
" telegram " :{
" bot_token " : " YOUR BOT TOKEN ID "
}
}Anforderungen: Ein Server und ein Google Mail -Konto.
Mitwirkender: Simon
Befolgen Sie die offizielle Dokumentation, um ein App -Kennwort für Ihr Google -Konto zu erstellen. Konfigurieren Sie wie unten, und Jubel !!!
" channel " : {
" type " : " gmail " ,
" gmail " : {
" subject_keyword " : [ " bot " , " @bot " ],
" host_email " : " [email protected] " ,
" host_password " : " GMAIL ACCESS KEY "
}
}❉ Benötigt kein Server oder eine öffentliche IP mehr
Mitwirkender: Amaoo
Abhängigkeiten
pip3 install slack_boltKonfiguration
" channel " : {
" type " : " slack " ,
" slack " : {
" slack_bot_token " : " xoxb-xxxx " ,
" slack_app_token " : " xapp-xxxx "
}
}Setzen Sie Bot Token Scope - OAuth & Erlaubnis
Schreiben Sie den BOT -Benutzer oAuth -Token in die Konfigurationsdatei slack_bot_token .
app_mentions:read
chat:write
Aktivieren Sie den Socket -Modus - Socket -Modus
Wenn Sie kein Token auf Anwendungsebene erstellt haben, werden Sie aufgefordert, eines zu erstellen. Schreiben Sie das erstellte Token in die Konfigurationsdatei slack_app_token .
Event -Abonnement (Ereignisabonnements) - Abonnieren Sie Bot -Ereignisse
app_mention
Referenzdokumentation
https://slack.dev/bolt-python/tutorial/getting-started
Anforderungen:
Abhängigkeiten
pip3 install requests flaskKonfiguration
" channel " : {
" type " : " dingtalk " ,
" dingtalk " : {
" image_create_prefix " : [ " draw " , " draw " , " Draw " ],
" port " : " 8081 " , # External port
" dingtalk_token " : " xx " , # Access token of the webhook address
" dingtalk_post_token " : " xx " , # Verification token carried in the header when DingTalk posts back messages
" dingtalk_secret " : " xx " # Security encryption signature string in the group robot
}
}Referenzdokumentation :
Roboter erzeugen
Adresse: https://open-dev.dingtalk.com/fe/app#/corp/robot fügen Sie einen Roboter hinzu, setzen Sie die ausgehende IP des Servers in der Entwicklungsverwaltung und die Nachrichtempfängeradresse (die externe Adresse in der Konfiguration).
Abhängigkeiten
pip3 install requests flaskKonfiguration
" channel " : {
" type " : " feishu " ,
" feishu " : {
" image_create_prefix " : [
" draw " ,
" draw " ,
" Draw "
],
" port " : " 8082 " , # External port
" app_id " : " xxx " , # Application app_id
" app_secret " : " xxx " , # Application Secret
" verification_token " : " xxx " # Event subscription Verification Token
}
}Roboter erzeugen
Adresse: https://open.feishu.cn/app/
Anforderungen: Ein Server und ein zertifiziertes Unternehmen WeChat.
Die config.json für Enterprise WeChat muss den Typ nur in wechat_com ändern, wobei die Standardmeldung Server -Server -URL: http: // ip: 8888/wechat empfängt.
" channel " : {
" type " : " wechat_com " ,
" wechat_com " : {
" wechat_token " : " YOUR TOKEN " , # Token value
" port " : " 8888 " , # Port the program listens on
" app_id " : " YOUR APP ID " , # App ID
" app_secret " : " YOUR APP SECRET " , # App secret
" wechat_corp_id " : " YOUR CORP ID " ,
" wechat_encoding_aes_key " : " YOUR AES KEY "
}
}HINWEIS: Die Server -IP -Adresse muss in der Liste "Enterprise Trusted IP" konfiguriert werden. Andernfalls erhalten Benutzer keine proaktiv gedrückten Nachrichten.
Referenzdokumentation :
clear_memory_commands : Dialog interne Befehle zum aktiven vorherigen Speicher, das String -Array kann den Befehlsaliase anpassen.

