pgsql search
1.0.0

Recursos Currrent e planejados:
Este projeto usa Pixi para gerenciar dependências e ambientes.
Se você estiver no Linux ou MacOS, pode instalar o Pixi usando os seguintes comandos:
curl -fsSL https://pixi.sh/install.sh | bashEm seguida, clone o repositório:
git clone https://github.com/dnth/pgsql-search.git
cd pgsql-searchInstale o projeto:
pixi installIsso deve instalar todas as dependências do projeto, incluindo PostgreSQL, CUDA, Pytorch e PGVector em um ambiente virtual.
Dica
Por que pixi e não uv ?
Estamos usando o banco de dados PostgreSQL neste projeto e ele não é instalável diretamente via uv ou pip . Mas o PostgreSQL é instalável via conda .
Em vez de usar conda , usamos pixi para gerenciar o ambiente e as dependências. Além disso, pixi usa uv sob o capô para puxar pacotes Python. Isso nos dá a velocidade do uv para pacotes Python e a flexibilidade do conda para dependências no nível do sistema.
Inicie o servidor de banco de dados local:
pixi run configure-db Isso inicializa o banco de dados e inicia o servidor. Você deve ver uma pasta chamada mylocal_db no seu diretório atual. Esta pasta contém os arquivos do banco de dados.
Depois que o banco de dados estiver configurado, vamos executar o script do QuickStart:
pixi run quickstartEste script carregará um conjunto de dados com imagens e legendas, criará um banco de dados, inserirá o conjunto de dados no banco de dados e executará uma pesquisa de texto completa e imprimirá os resultados.
Se tudo correr bem, você verá os resultados impressos no terminal.
Atualmente, apoiamos apenas os conjuntos de dados de face abraçados. Vamos carregar um conjunto de dados com imagens e legendas.
from pgsql_search . loader import HuggingFaceDatasets
ds = HuggingFaceDatasets ( "UCSC-VLAA/Recap-COCO-30K" ) # Load the dataset
ds . save_images ( "../data/images" ) # Save the images to a local folder
ds = ds . select_columns ([ "image_filepath" , "caption" ]) # Select the columns we want to use ds.dataset é um objeto Dataset de rosto abraçado. Você está livre para executar qualquer operações suportadas pelo pacote datasets .
ds . dataset Dataset({
features: ['image_filepath', 'caption'],
num_rows: 30504
})
De Ds.DataSet, vemos que temos 30504 linhas no conjunto de dados com 2 colunas: image_filepath e caption . Agora podemos criar um banco de dados e inserir o conjunto de dados no banco de dados.
from pgsql_search . database import PostgreSQLDatabase , ColumnType
PostgreSQLDatabase . create_database ( "my_database" )Insira o conjunto de dados no banco de dados:
df = ds . dataset . to_pandas ()
with PostgreSQLDatabase ( "my_database" ) as db :
db . initialize_table ( "image_metadata" )
db . add_column ( "image_filepath" , ColumnType . TEXT , nullable = False )
db . add_column ( "caption" , ColumnType . TEXT , nullable = True )
db . insert_dataframe ( df )Depois de concluído, podemos executar uma pesquisa completa de texto no banco de dados.
from pgsql_search . database import PostgreSQLDatabase
query = "man in a yellow shirt"
with PostgreSQLDatabase ( "my_database" ) as db :
res = db . full_text_search (
query = query ,
table_name = "image_metadata" ,
search_column = "caption" ,
num_results = 10
)A saída é um quadro de dados de pandas com os resultados e consultas.
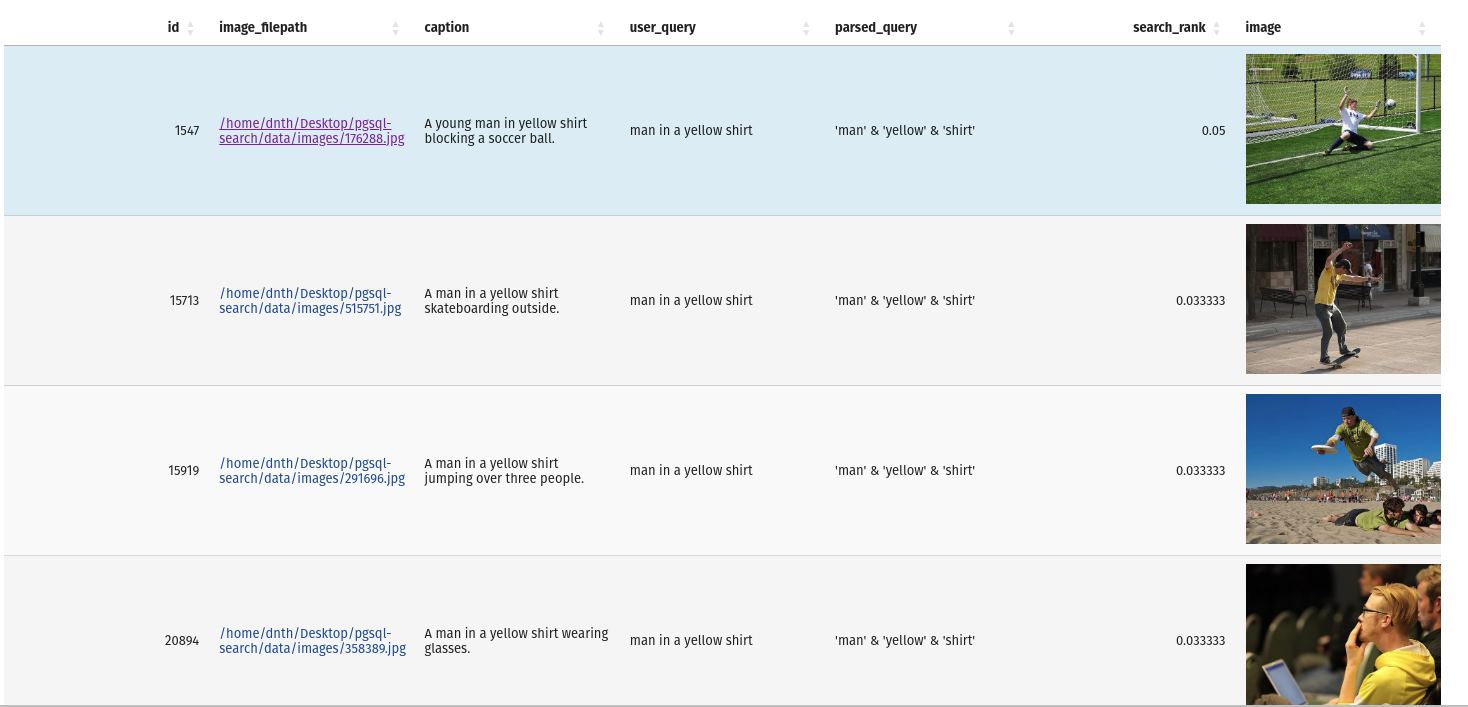
Se você deseja inspecionar o banco de dados, pode fazê -lo com o seguinte comando:
pixi run inspect-dbIsso abrirá um terminal interativo para inspecionar o banco de dados.
Se você quiser parar o servidor de banco de dados, pode fazê -lo com o seguinte comando:
pixi run stop-dbE para remover o banco de dados inteiramente:
pixi run remove-dbpixi run -e test pytest

