pgsql search
1.0.0

Strömungs- und geplante Funktionen:
Dieses Projekt verwendet Pixi, um Abhängigkeiten und Umgebungen zu verwalten.
Wenn Sie sich unter Linux oder macOS befinden, können Sie Pixi mit den folgenden Befehlen installieren:
curl -fsSL https://pixi.sh/install.sh | bashKlonen Sie dann das Repository:
git clone https://github.com/dnth/pgsql-search.git
cd pgsql-searchInstallieren Sie das Projekt:
pixi installDies sollte alle Abhängigkeiten des Projekts einbauen, einschließlich PostgreSQL, CUDA, Pytorch und PGVector in eine virtuelle Umgebung.
Tipp
Warum pixi und nicht uv ?
Wir verwenden die PostgreSQL -Datenbank in diesem Projekt und sie können nicht direkt über uv oder pip installiert werden. PostgreSQL ist jedoch über conda installierbar.
Anstatt conda zu verwenden, verwenden wir pixi um die Umgebung und die Abhängigkeiten zu verwalten. Außerdem verwendet pixi uv unter der Motorhaube, um Python -Pakete zu ziehen. Dies gibt uns die Geschwindigkeit von uv für Python -Pakete und die Flexibilität von conda für Abhängigkeiten auf Systemebene.
Starten Sie den lokalen Datenbankserver:
pixi run configure-db Dies initialisiert die Datenbank und startet den Server. Sie sollten einen Ordner namens mylocal_db in Ihrem aktuellen Verzeichnis sehen. Dieser Ordner enthält die Datenbankdateien.
Sobald die Datenbank eingerichtet ist, führen wir das QuickStart -Skript aus:
pixi run quickstartIn diesem Skript lädt ein Datensatz mit Bildern und Bildunterschriften, erstellt eine Datenbank, fügt den Datensatz in die Datenbank ein und führt eine Volltextsuche aus und druckte die Ergebnisse aus.
Wenn alles gut läuft, sollten Sie die im Terminal gedruckten Ergebnisse sehen.
Derzeit unterstützen wir nur die Umarmung von Gesichtsdatensätzen. Laden wir einen Datensatz mit Bildern und Bildunterschriften.
from pgsql_search . loader import HuggingFaceDatasets
ds = HuggingFaceDatasets ( "UCSC-VLAA/Recap-COCO-30K" ) # Load the dataset
ds . save_images ( "../data/images" ) # Save the images to a local folder
ds = ds . select_columns ([ "image_filepath" , "caption" ]) # Select the columns we want to use ds.dataset ist ein umarmendes Dataset . Sie können alle vom datasets -Paket unterstützten Vorgänge ausführen.
ds . dataset Dataset({
features: ['image_filepath', 'caption'],
num_rows: 30504
})
Aus ds.Dataset sehen wir, dass wir 30504 Zeilen im Datensatz mit 2 Spalten haben: image_filepath und caption . Jetzt können wir eine Datenbank erstellen und den Datensatz in die Datenbank einfügen.
from pgsql_search . database import PostgreSQLDatabase , ColumnType
PostgreSQLDatabase . create_database ( "my_database" )Fügen Sie den Datensatz in die Datenbank ein:
df = ds . dataset . to_pandas ()
with PostgreSQLDatabase ( "my_database" ) as db :
db . initialize_table ( "image_metadata" )
db . add_column ( "image_filepath" , ColumnType . TEXT , nullable = False )
db . add_column ( "caption" , ColumnType . TEXT , nullable = True )
db . insert_dataframe ( df )Nach Abschluss können wir eine Volltextsuche in der Datenbank ausführen.
from pgsql_search . database import PostgreSQLDatabase
query = "man in a yellow shirt"
with PostgreSQLDatabase ( "my_database" ) as db :
res = db . full_text_search (
query = query ,
table_name = "image_metadata" ,
search_column = "caption" ,
num_results = 10
)Die Ausgabe ist ein PANDAS -Datenframe mit den Ergebnissen und Abfrage.
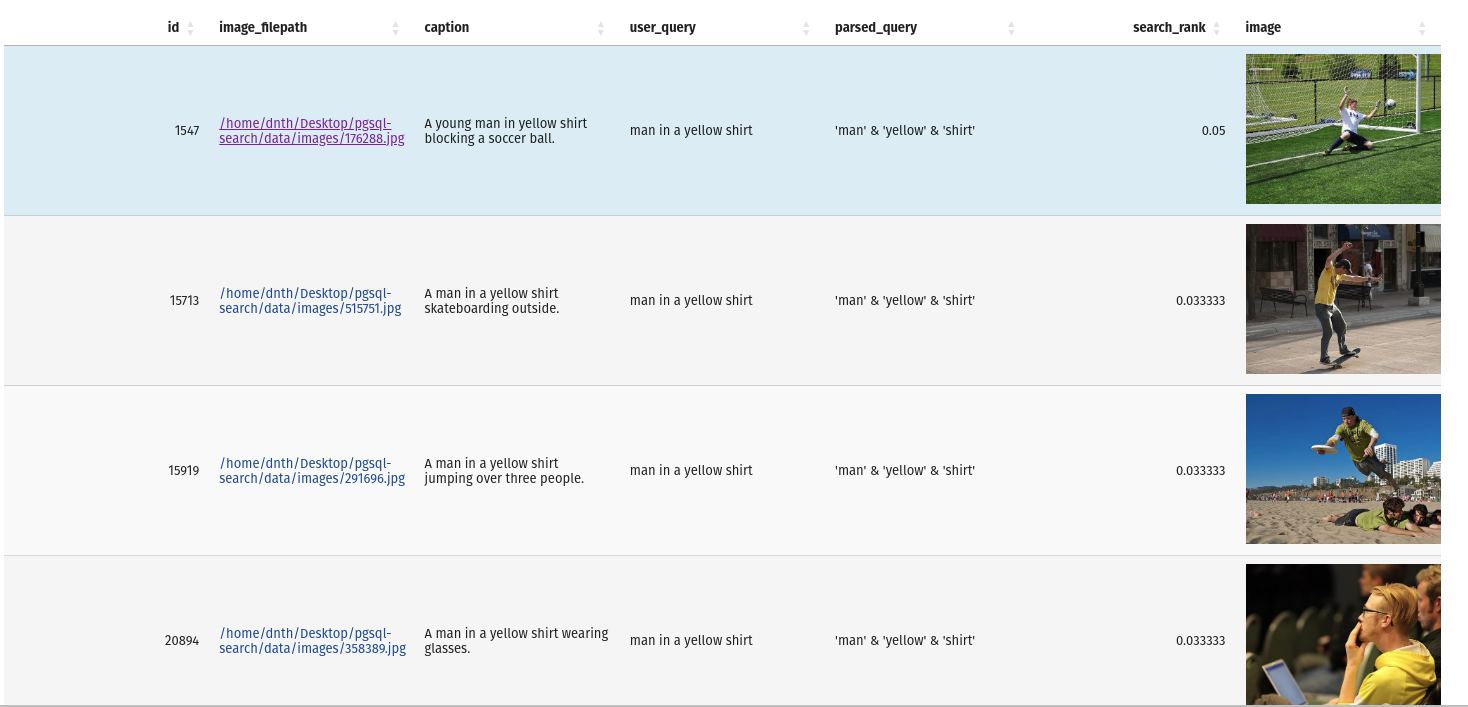
Wenn Sie die Datenbank inspizieren möchten, können Sie dies mit dem folgenden Befehl tun:
pixi run inspect-dbDadurch wird ein interaktives Terminal geöffnet, um die Datenbank zu inspizieren.
Wenn Sie den Datenbankserver stoppen möchten, können Sie dies mit dem folgenden Befehl tun:
pixi run stop-dbUnd um die Datenbank vollständig zu entfernen:
pixi run remove-dbpixi run -e test pytest

