pgsql search
1.0.0

Current et fonctionnalités prévues:
Ce projet utilise Pixi pour gérer les dépendances et les environnements.
Si vous êtes sur Linux ou MacOS, vous pouvez installer Pixi en utilisant les commandes suivantes:
curl -fsSL https://pixi.sh/install.sh | bashPuis cloner le référentiel:
git clone https://github.com/dnth/pgsql-search.git
cd pgsql-searchInstallez le projet:
pixi installCela devrait installer toutes les dépendances du projet, y compris PostgreSQL, CUDA, Pytorch et PGVector dans un environnement virtuel.
Conseil
Pourquoi pixi et non uv ?
Nous utilisons la base de données PostgreSQL dans ce projet et elle n'est pas installée directement via uv ou pip . Mais PostgreSQL est instalable via conda .
Au lieu d'utiliser conda , nous utilisons pixi pour gérer l'environnement et les dépendances. De plus, pixi utilise uv sous le capot pour tirer les packages Python. Cela nous donne la vitesse des uv pour les packages Python et la flexibilité des conda pour les dépendances au niveau du système.
Démarrez le serveur de base de données locale:
pixi run configure-db Cela initialise la base de données et démarre le serveur. Vous devriez voir un dossier nommé mylocal_db dans votre répertoire actuel. Ce dossier contient les fichiers de base de données.
Une fois la base de données configurée, exécutons le script QuickStart:
pixi run quickstartCe script chargera un ensemble de données avec des images et des légendes, créera une base de données, insérez l'ensemble de données dans la base de données et effectuez une recherche de texte intégral et imprimez les résultats.
Si tout se passe bien, vous devriez voir les résultats imprimés dans le terminal.
Actuellement, nous prenons uniquement des ensembles de données de visage Hugging Face. Chargez un ensemble de données avec des images et des légendes.
from pgsql_search . loader import HuggingFaceDatasets
ds = HuggingFaceDatasets ( "UCSC-VLAA/Recap-COCO-30K" ) # Load the dataset
ds . save_images ( "../data/images" ) # Save the images to a local folder
ds = ds . select_columns ([ "image_filepath" , "caption" ]) # Select the columns we want to use ds.dataset est un objet Dataset étreint. Vous êtes libre d'effectuer toutes les opérations prises en charge par le package datasets .
ds . dataset Dataset({
features: ['image_filepath', 'caption'],
num_rows: 30504
})
De D.Dataset, nous voyons que nous avons 30504 lignes dans l'ensemble de données avec 2 colonnes: image_filepath et caption . Maintenant, nous pouvons créer une base de données et insérer l'ensemble de données dans la base de données.
from pgsql_search . database import PostgreSQLDatabase , ColumnType
PostgreSQLDatabase . create_database ( "my_database" )Insérez l'ensemble de données dans la base de données:
df = ds . dataset . to_pandas ()
with PostgreSQLDatabase ( "my_database" ) as db :
db . initialize_table ( "image_metadata" )
db . add_column ( "image_filepath" , ColumnType . TEXT , nullable = False )
db . add_column ( "caption" , ColumnType . TEXT , nullable = True )
db . insert_dataframe ( df )Une fois terminé, nous pouvons effectuer une recherche de texte intégral dans la base de données.
from pgsql_search . database import PostgreSQLDatabase
query = "man in a yellow shirt"
with PostgreSQLDatabase ( "my_database" ) as db :
res = db . full_text_search (
query = query ,
table_name = "image_metadata" ,
search_column = "caption" ,
num_results = 10
)La sortie est un Pandas DataFrame avec les résultats et la requête.
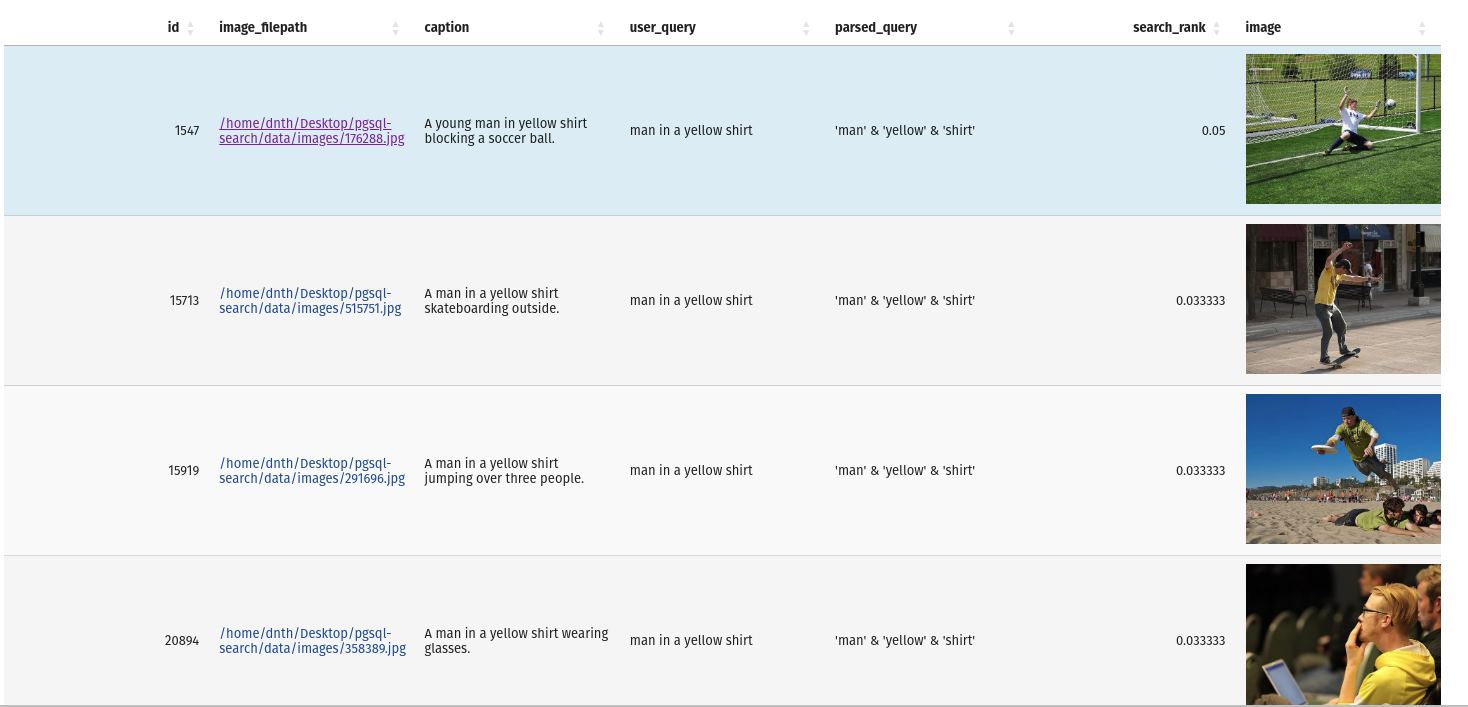
Si vous souhaitez inspecter la base de données, vous pouvez le faire avec la commande suivante:
pixi run inspect-dbCela ouvrira un terminal interactif pour inspecter la base de données.
Si vous souhaitez arrêter le serveur de base de données, vous pouvez le faire avec la commande suivante:
pixi run stop-dbEt pour supprimer entièrement la base de données:
pixi run remove-dbpixi run -e test pytest

