pgsql search
1.0.0

Currrent y características planificadas:
Este proyecto utiliza PIXI para administrar dependencias y entornos.
Si está en Linux o MacOS, puede instalar PIXI usando los siguientes comandos:
curl -fsSL https://pixi.sh/install.sh | bashLuego clone el repositorio:
git clone https://github.com/dnth/pgsql-search.git
cd pgsql-searchInstale el proyecto:
pixi installEsto debería instalar todas las dependencias del proyecto, incluidos PostgreSQL, CUDA, Pytorch y PgVector en un entorno virtual.
Consejo
¿Por qué pixi y no uv ?
Estamos utilizando la base de datos PostgreSQL en este proyecto y no se puede instalar directamente a través de uv o pip . Pero PostgreSQL se puede instalar a través de conda .
En lugar de usar conda , usamos pixi para administrar el entorno y las dependencias. Además, pixi usa uv debajo del capó para extraer los paquetes de Python. Esto nos da la velocidad de uv para los paquetes de Python y la flexibilidad de conda para las dependencias de nivel del sistema.
Inicie el servidor de base de datos local:
pixi run configure-db Esto inicializa la base de datos e inicia el servidor. Debería ver una carpeta llamada mylocal_db en su directorio actual. Esta carpeta contiene los archivos de la base de datos.
Una vez que se configura la base de datos, ejecutemos el script QuickStart:
pixi run quickstartEste script cargará un conjunto de datos con imágenes y subtítulos, creará una base de datos, insertará el conjunto de datos en la base de datos y ejecutará una búsqueda de texto completa e imprime los resultados.
Si todo va bien, debería ver los resultados impresos en la terminal.
Actualmente, solo apoyamos los conjuntos de datos de la cara. Cargamos un conjunto de datos con imágenes y subtítulos.
from pgsql_search . loader import HuggingFaceDatasets
ds = HuggingFaceDatasets ( "UCSC-VLAA/Recap-COCO-30K" ) # Load the dataset
ds . save_images ( "../data/images" ) # Save the images to a local folder
ds = ds . select_columns ([ "image_filepath" , "caption" ]) # Select the columns we want to use ds.dataset es un objeto Dataset de cara de abrazo. Usted es libre de realizar cualquier operación compatible con el paquete datasets .
ds . dataset Dataset({
features: ['image_filepath', 'caption'],
num_rows: 30504
})
Desde DS.Dataset vemos que tenemos 30504 filas en el conjunto de datos con 2 columnas: image_filepath y caption . Ahora podemos crear una base de datos e insertar el conjunto de datos en la base de datos.
from pgsql_search . database import PostgreSQLDatabase , ColumnType
PostgreSQLDatabase . create_database ( "my_database" )Inserte el conjunto de datos en la base de datos:
df = ds . dataset . to_pandas ()
with PostgreSQLDatabase ( "my_database" ) as db :
db . initialize_table ( "image_metadata" )
db . add_column ( "image_filepath" , ColumnType . TEXT , nullable = False )
db . add_column ( "caption" , ColumnType . TEXT , nullable = True )
db . insert_dataframe ( df )Una vez completado, podemos ejecutar una búsqueda de texto completa en la base de datos.
from pgsql_search . database import PostgreSQLDatabase
query = "man in a yellow shirt"
with PostgreSQLDatabase ( "my_database" ) as db :
res = db . full_text_search (
query = query ,
table_name = "image_metadata" ,
search_column = "caption" ,
num_results = 10
)La salida es un marco de datos PANDAS con los resultados y la consulta.
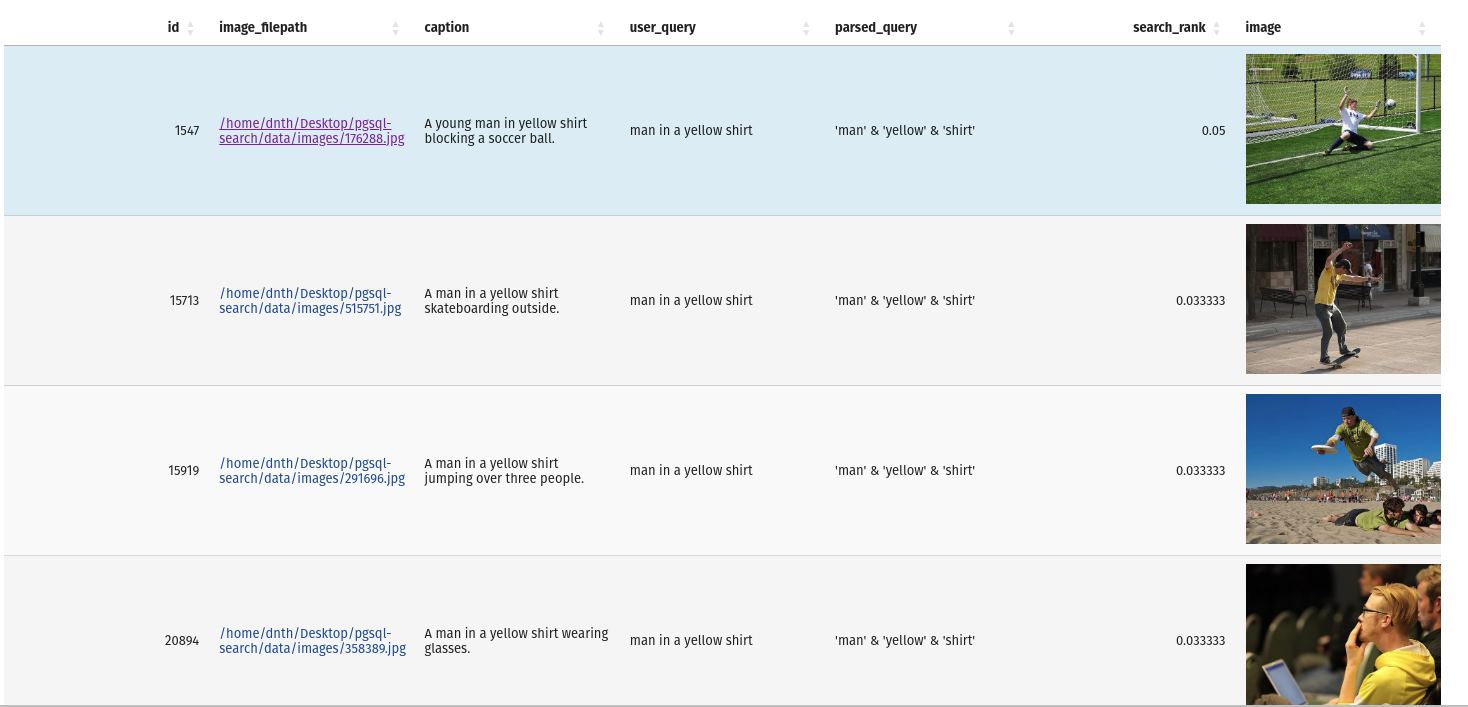
Si desea inspeccionar la base de datos, puede hacerlo con el siguiente comando:
pixi run inspect-dbEsto abrirá un terminal interactivo para inspeccionar la base de datos.
Si desea detener el servidor de la base de datos, puede hacerlo con el siguiente comando:
pixi run stop-dbY para eliminar la base de datos por completo:
pixi run remove-dbpixi run -e test pytest

