simple effective text matching pytorch
1.0.0
Esta é uma implementação Pytorch do artigo da ACL 2019 "correspondência de texto simples e eficaz com recursos de alinhamento mais ricos". A implementação original do TensorFlow: https://github.com/alibaba-edu/simple-effective-text-satching.
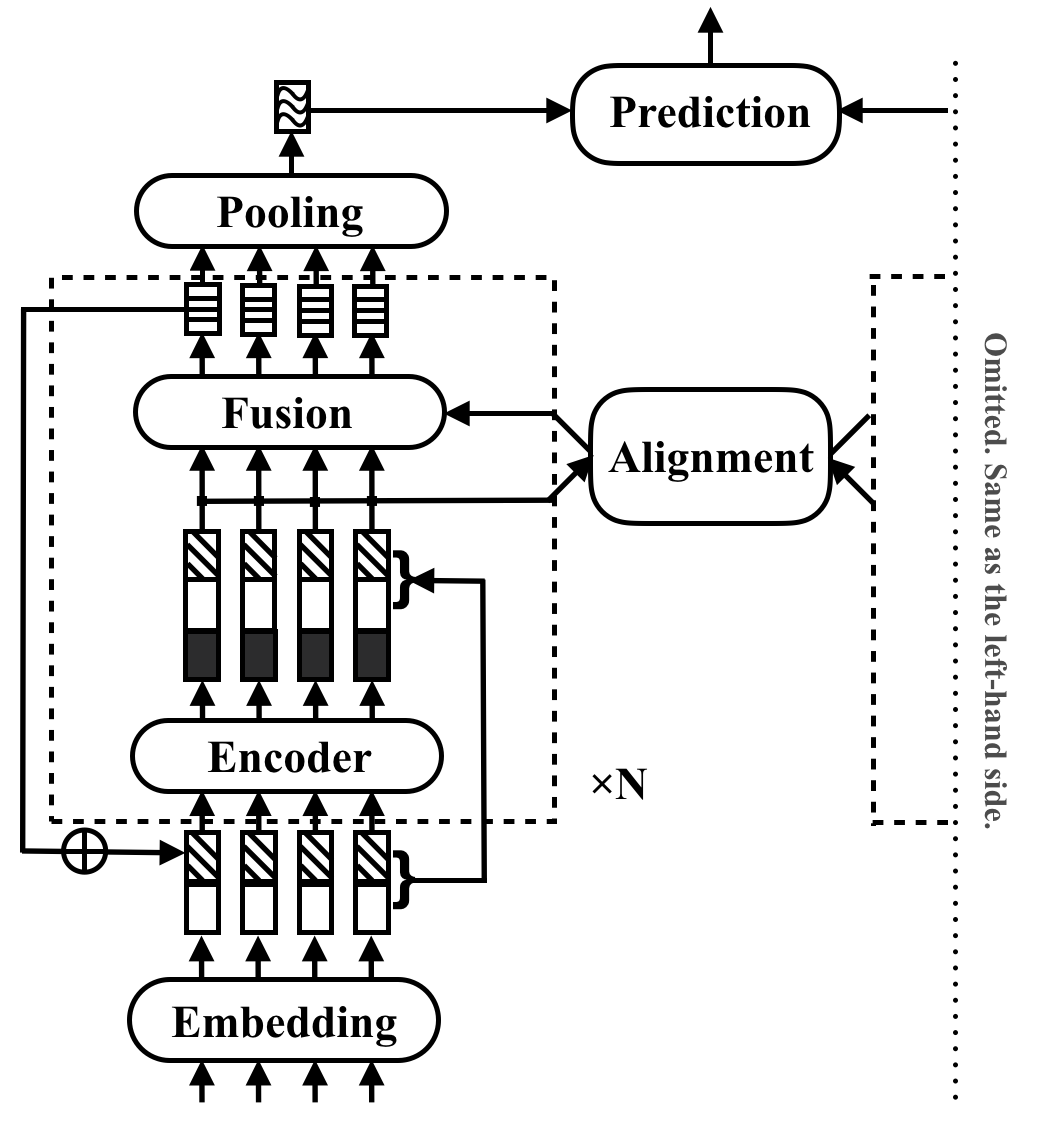
O RE2 é uma arquitetura neural rápida e forte para aplicações de correspondência de texto de uso geral. Em uma tarefa de correspondência de texto, um modelo leva duas seqüências de texto como entrada e prevê seu relacionamento. Este método tem como objetivo explorar o que é suficiente para um forte desempenho nessas tarefas. Ele simplifica muitos componentes lentos que são considerados anteriormente como blocos de construção principais na correspondência de texto, mantendo três recursos principais diretamente disponíveis para o alinhamento entre seqüências: recursos originais, recursos alinhados anteriores e recursos contextuais.
O RE2 atinge o desempenho em pé de igualdade com o estado da arte em quatro conjuntos de dados de referência: SNLI, Scitail, Quora e Wikiqa, entre tarefas de inferência de linguagem natural, paráfrase de identificação e seleção de respostas, sem ou poucas ou poucas adaptações específicas da tarefa. Possui pelo menos 6 vezes a velocidade de inferência mais rápida em comparação com os modelos realizados similarmente.
A tabela a seguir lista os principais resultados do experimento. O artigo relata a média e o desvio padrão de 10 corridas. O tempo de inferência (em segundos) é medido processando um lote de 8 pares de comprimento 20 nas CPUs Intel i7. O tempo de computação dos recursos de PDV usado por CSRAN e Diin não está incluído.
| Modelo | Snli | Scitail | Quora | Wikiqa | Tempo de inferência |
|---|---|---|---|---|---|
| Bimpm | 86.9 | - | 88.2 | 0,731 | 0,05 |
| Esim | 88.0 | 70.6 | - | - | - |
| Diin | 88.0 | - | 89.1 | - | 1.79 |
| CSRAN | 88.7 | 86.7 | 89.2 | - | 0,28 |
| Re2 | 88,9 ± 0,1 | 86,0 ± 0,6 | 89,2 ± 0,2 | 0,7618 ± 0,0040 | 0,03 ~ 0,05 |
Consulte o artigo para obter mais detalhes dos componentes e resultados da experiência.
pip install -r requirements.txtresources/Os dados usados no artigo são preparados da seguinte forma:
data/orig .cd data/orig/SNLI && gunzip *.gz )cd data && python prepare_snli.pydata/orig .cd data && python prepare_scitail.pydata/orig .cd data && python prepare_quora.pydata/orig .cd data && python prepare_wikiqa.pymake -B para compilar os arquivos de origem no qg-emnlp07-data/eval/trec_eval-8.0 . Mova o arquivo binário "TREC_EVAL" para resources/ . Para treinar um novo modelo de correspondência de texto, execute o seguinte comando:
python train.py $config_file .json5 Exemplo de arquivos de configuração são fornecidos em configs/ :
configs/main.json5 : Replique o resultado principal resulta no papel.configs/robustness.json5 : Verificações de robustezconfigs/ablation.json5 : estudo de ablaçãoAs instruções para escrever seus próprios arquivos de configuração:
[
{
name : 'exp1' , // name of your experiment, can be the same across different data
__parents__ : [
'default' , // always put the default on top
'data/quora' , // data specific configurations in `configs/data`
// 'debug', // use "debug" to quick debug your code
] ,
__repeat__ : 5 , // how may repetitions you want
blocks : 3 , // other configurations for this experiment
} ,
// multiple configurations are executed sequentially
{
name : 'exp2' , // results under the same name will be overwritten
__parents__ : [
'default' ,
'data/quora' ,
] ,
__repeat__ : 5 ,
blocks : 4 ,
}
]Para verificar apenas as configurações, use
python train.py $config_file .json5 --dry Para avaliar um modelo existente, use python evaluate.py $model_path $data_file , aqui está um exemplo:
python evaluate.py models/snli/benchmark/best.pt data/snli/train.txt
python evaluate.py models/snli/benchmark/best.pt data/snli/test.txt Observe que o treinamento multi-GPU ainda não é suportado na implementação do Pytorch. Uma única GPU de 16g é suficiente para treinamento quando blocos <5 com tamanho oculto 200 e tamanho 512 em lote. Todos os resultados relatados no artigo, exceto que as verificações de robustez podem ser reproduzidas com uma única GPU de 16g.
Cite o papel da ACL se você usar o RE2 em seu trabalho:
@inproceedings{yang2019simple,
title={Simple and Effective Text Matching with Richer Alignment Features},
author={Yang, Runqi and Zhang, Jianhai and Gao, Xing and Ji, Feng and Chen, Haiqing},
booktitle={Association for Computational Linguistics (ACL)},
year={2019}
}
Este projeto está no Apache License 2.0.


