simple effective text matching pytorch
1.0.0
Il s'agit d'une implémentation Pytorch de l'article ACL 2019 "correspondant de texte simple et efficace avec des fonctionnalités d'alignement plus riches". L'implémentation d'origine TensorFlow: https://github.com/alibaba-edu/simple-effective-text-matching.
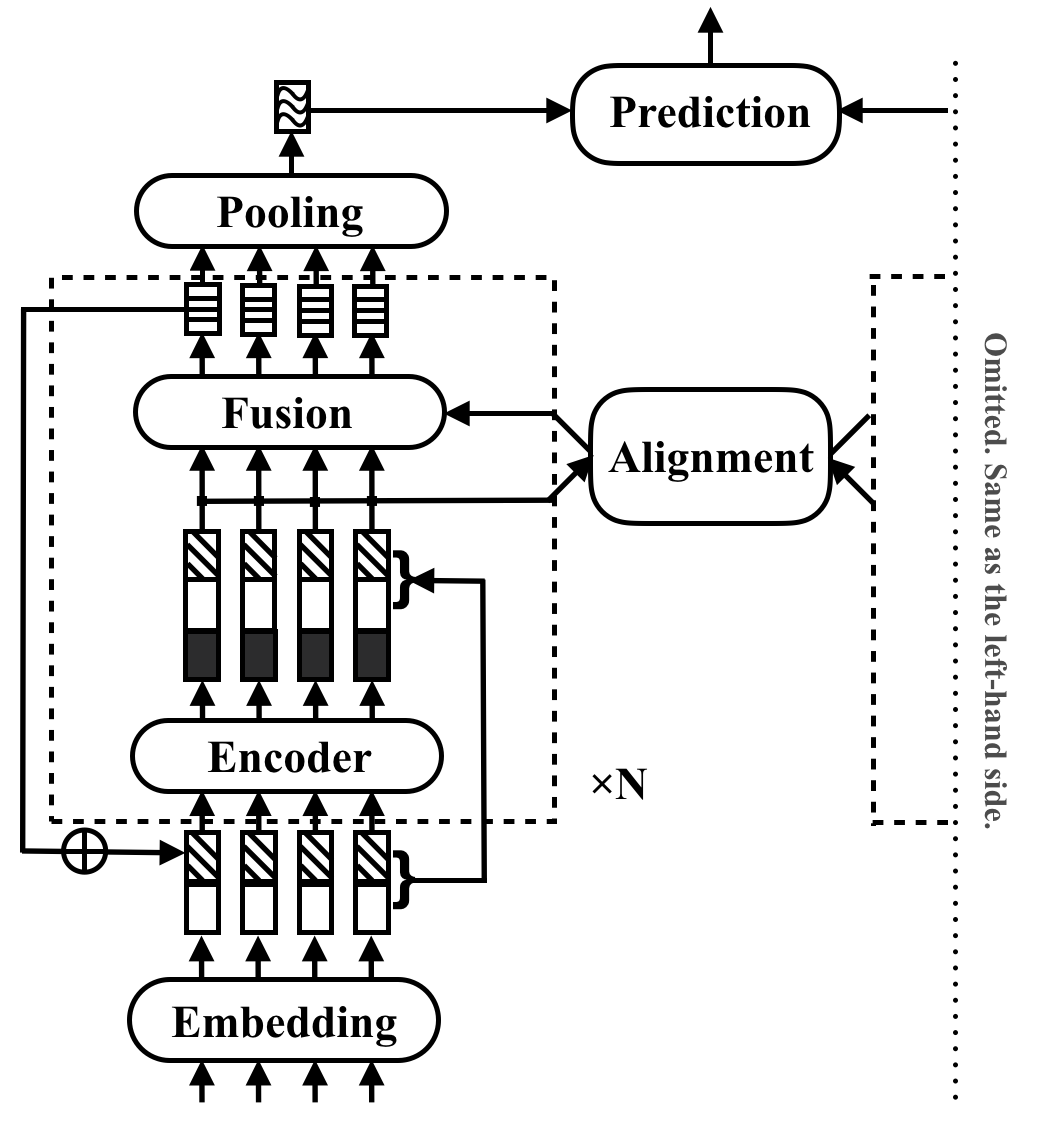
RE2 est une architecture neuronale rapide et forte pour les applications de correspondance de texte à usage général. Dans une tâche de correspondance de texte, un modèle prend deux séquences de texte en entrée et prédit leur relation. Cette méthode vise à explorer ce qui est suffisant pour de fortes performances dans ces tâches. Il simplifie de nombreux composants lents qui sont auparavant considérés comme des blocs de construction de base dans la correspondance de texte, tout en conservant trois fonctionnalités clés directement disponibles pour l'alignement inter-séquence: fonctionnalités ponctuelles d'origine, fonctionnalités alignées précédentes et fonctionnalités contextuelles.
RE2 obtient des performances à égalité avec l'état de l'art sur quatre ensembles de données de référence: SNLI, Scitail, Quora et Wikiqa, à travers les tâches de l'inférence du langage naturel, l'identification paraphrase et la sélection des réponses sans ou peu de tâches. Il a au moins 6 fois une vitesse d'inférence plus rapide par rapport aux modèles effectués de manière similaire.
Le tableau suivant répertorie les principaux résultats de l'expérience. Le document rapporte l'écart moyen et standard de 10 cycles. Le temps d'inférence (en secondes) est mesuré en traitant un lot de 8 paires de longueur 20 sur les processeurs Intel i7. Le temps de calcul des caractéristiques POS utilisés par CSRAN et DIIN n'est pas inclus.
| Modèle | Snli | Snitail | Quora | Wikiqa | Temps d'inférence |
|---|---|---|---|---|---|
| Bimpm | 86.9 | - | 88.2 | 0,731 | 0,05 |
| Esim | 88.0 | 70.6 | - | - | - |
| Diin | 88.0 | - | 89.1 | - | 1.79 |
| Csran | 88.7 | 86.7 | 89.2 | - | 0,28 |
| RE2 | 88,9 ± 0,1 | 86,0 ± 0,6 | 89,2 ± 0,2 | 0,7618 ± 0,0040 | 0,03 ~ 0,05 |
Reportez-vous à l'article pour plus de détails sur les composants et les résultats de l'expérience.
pip install -r requirements.txtresources/Les données utilisées dans le papier sont préparées comme suit:
data/orig .cd data/orig/SNLI && gunzip *.gz )cd data && python prepare_snli.pydata/orig .cd data && python prepare_scitail.pydata/orig .cd data && python prepare_quora.pydata/orig .cd data && python prepare_wikiqa.pymake -B pour compiler les fichiers source dans qg-emnlp07-data/eval/trec_eval-8.0 . Déplacez le fichier binaire "Trec_eval" vers resources/ . Pour former un nouveau modèle de correspondance de texte, exécutez la commande suivante:
python train.py $config_file .json5 Des exemples de fichiers de configuration sont fournis dans configs/ :
configs/main.json5 : reproduire le résultat de l'expérience principale dans l'article.configs/robustness.json5 : vérifications de la robustesseconfigs/ablation.json5 : étude d'ablationLes instructions pour rédiger vos propres fichiers de configuration:
[
{
name : 'exp1' , // name of your experiment, can be the same across different data
__parents__ : [
'default' , // always put the default on top
'data/quora' , // data specific configurations in `configs/data`
// 'debug', // use "debug" to quick debug your code
] ,
__repeat__ : 5 , // how may repetitions you want
blocks : 3 , // other configurations for this experiment
} ,
// multiple configurations are executed sequentially
{
name : 'exp2' , // results under the same name will be overwritten
__parents__ : [
'default' ,
'data/quora' ,
] ,
__repeat__ : 5 ,
blocks : 4 ,
}
]Pour vérifier les configurations uniquement, utilisez
python train.py $config_file .json5 --dry Pour évaluer un modèle existant, utilisez python evaluate.py $model_path $data_file , voici un exemple:
python evaluate.py models/snli/benchmark/best.pt data/snli/train.txt
python evaluate.py models/snli/benchmark/best.pt data/snli/test.txt Notez que la formation multi-GPU n'est pas encore prise en charge dans l'implémentation de Pytorch. Un seul GPU 16G est suffisant pour l'entraînement lorsque les blocs <5 avec une taille cachée 200 et une taille de lot 512. Tous les résultats rapportés dans le document, sauf que les vérifications de la robustesse peuvent être reproduites avec un seul GPU 16G.
Veuillez citer le papier ACL si vous utilisez RE2 dans votre travail:
@inproceedings{yang2019simple,
title={Simple and Effective Text Matching with Richer Alignment Features},
author={Yang, Runqi and Zhang, Jianhai and Gao, Xing and Ji, Feng and Chen, Haiqing},
booktitle={Association for Computational Linguistics (ACL)},
year={2019}
}
Ce projet est sous la licence 2.0 Apache.


