simple effective text matching pytorch
1.0.0
これは、ACL 2019ペーパー「より豊富なアライメント機能とシンプルで効果的なテキストマッチング」のPytorch実装です。元のTensorflow実装:https://github.com/alibaba-edu/simple-effective-text-matching。
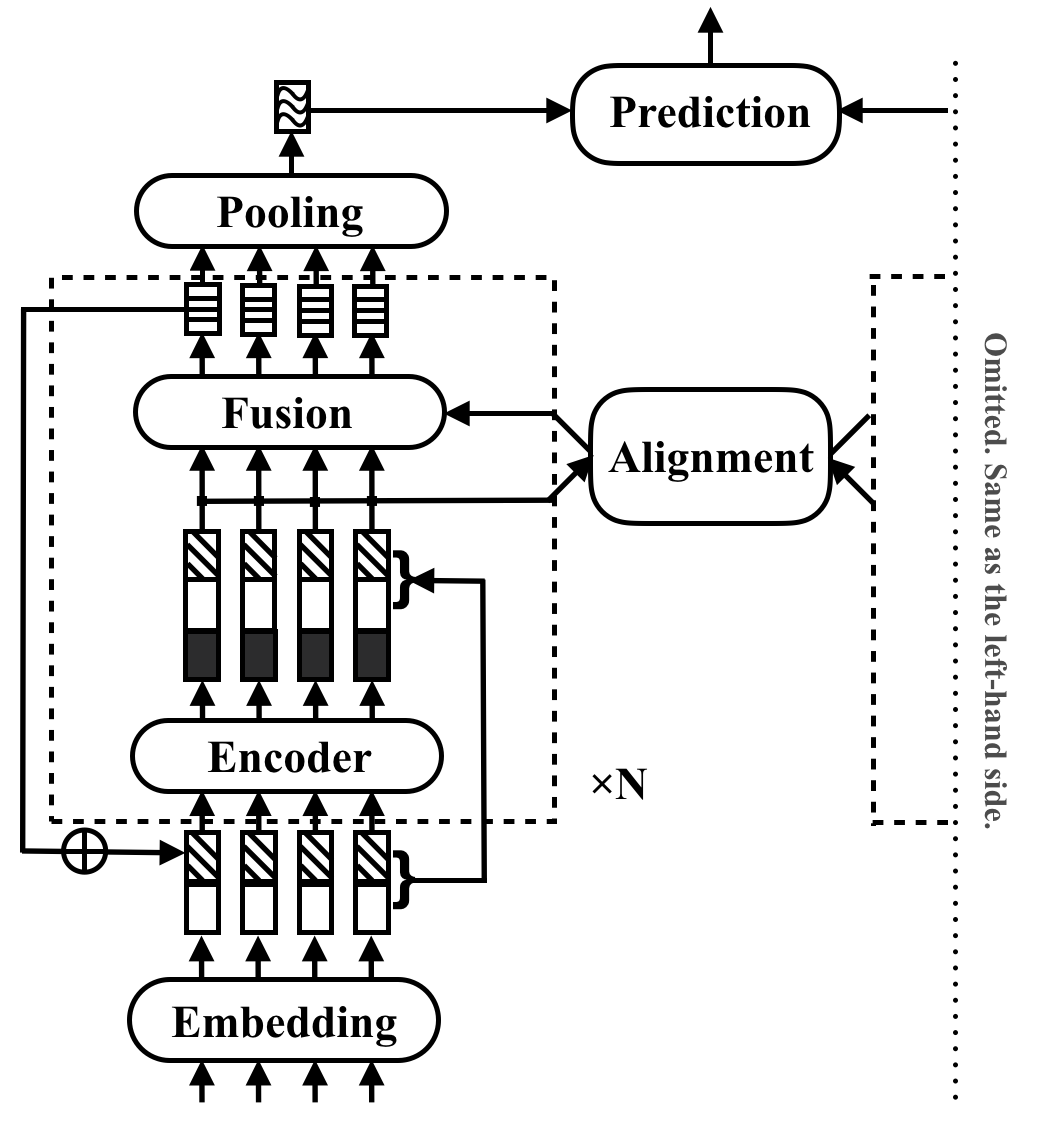
RE2は、汎用テキストマッチングアプリケーションの高速で強力なニューラルアーキテクチャです。テキストマッチングタスクでは、モデルは入力として2つのテキストシーケンスを取得し、関係を予測します。この方法は、これらのタスクで強力なパフォーマンスに十分なものを探ることを目的としています。以前はテキストマッチングでコアビルディングブロックと見なされていた多くのスローコンポーネントを簡素化し、3つの重要な機能をインターシーケンスアライメントに直接利用できるようにします:オリジナルのポイントごとの機能、以前のアライメント機能、コンテキスト機能。
RE2は、自然言語の推論のタスク全体で、SNLI、Scitail、Quora、Wikiqaの4つのベンチマークデータセットの最先端のデータと同等のパフォーマンスを達成します。同様に実行されたモデルと比較して、少なくとも6倍の推論速度があります。
次の表には、主要な実験結果が示されています。この論文は、10回の実行の平均偏差と標準偏差を報告しています。推論時間(秒単位)は、Intel I7 CPUで長さ20の8ペアのバッチを処理することにより測定されます。 CSRANとDIINが使用するPOS機能の計算時間は含まれていません。
| モデル | snli | シテール | Quora | ウィキカ | 推論時間 |
|---|---|---|---|---|---|
| ビンプ | 86.9 | - | 88.2 | 0.731 | 0.05 |
| esim | 88.0 | 70.6 | - | - | - |
| diin | 88.0 | - | 89.1 | - | 1.79 |
| csran | 88.7 | 86.7 | 89.2 | - | 0.28 |
| RE2 | 88.9±0.1 | 86.0±0.6 | 89.2±0.2 | 0.7618±0.0040 | 0.03〜0.05 |
コンポーネントと実験結果の詳細については、論文を参照してください。
pip install -r requirements.txtresources/論文で使用されるデータは、次のように作成されています。
data/orig 。cd data/orig/SNLI && gunzip *.gz )cd data && python prepare_snli.pydata/origに解凍します。cd data && python prepare_scitail.pydata/origにダウンロードして解凍します。cd data && python prepare_quora.pydata/orig 。cd data && python prepare_wikiqa.pymake -Bコマンドを使用して、 qg-emnlp07-data/eval/trec_eval-8.0のソースファイルをコンパイルします。バイナリファイル「TREC_EVAL」をresources/に移動します。 新しいテキストマッチングモデルをトレーニングするには、次のコマンドを実行します。
python train.py $config_file .json5構成ファイルの例は、 configs/ :
configs/main.json5 :ペーパーの主な実験結果を複製します。configs/robustness.json5 :堅牢性チェックconfigs/ablation.json5 :アブレーション研究独自の構成ファイルを書き込む手順:
[
{
name : 'exp1' , // name of your experiment, can be the same across different data
__parents__ : [
'default' , // always put the default on top
'data/quora' , // data specific configurations in `configs/data`
// 'debug', // use "debug" to quick debug your code
] ,
__repeat__ : 5 , // how may repetitions you want
blocks : 3 , // other configurations for this experiment
} ,
// multiple configurations are executed sequentially
{
name : 'exp2' , // results under the same name will be overwritten
__parents__ : [
'default' ,
'data/quora' ,
] ,
__repeat__ : 5 ,
blocks : 4 ,
}
]構成のみを確認するには、使用します
python train.py $config_file .json5 --dry存在するモデルを評価するには、 python evaluate.py $model_path $data_fileを使用して、例を次に示します。
python evaluate.py models/snli/benchmark/best.pt data/snli/train.txt
python evaluate.py models/snli/benchmark/best.pt data/snli/test.txt マルチGPUトレーニングは、Pytorchの実装ではまだサポートされていないことに注意してください。単一の16G GPUは、隠されたサイズ200とバッチサイズ512のブロック<5の場合、トレーニングに十分です。堅牢性チェックを除くすべての結果は、単一の16G GPUで再現できます。
作業でRE2を使用している場合は、ACLペーパーを引用してください。
@inproceedings{yang2019simple,
title={Simple and Effective Text Matching with Richer Alignment Features},
author={Yang, Runqi and Zhang, Jianhai and Gao, Xing and Ji, Feng and Chen, Haiqing},
booktitle={Association for Computational Linguistics (ACL)},
year={2019}
}
このプロジェクトは、Apacheライセンス2.0に基づいています。


