simple effective text matching pytorch
1.0.0
이것은 ACL 2019 논문의 Pytorch 구현 "더 풍부한 정렬 기능과 일치하는 간단하고 효과적인 텍스트"입니다. 원래 Tensorflow 구현 : https://github.com/alibaba-edu/simple-efficative-text-matching.
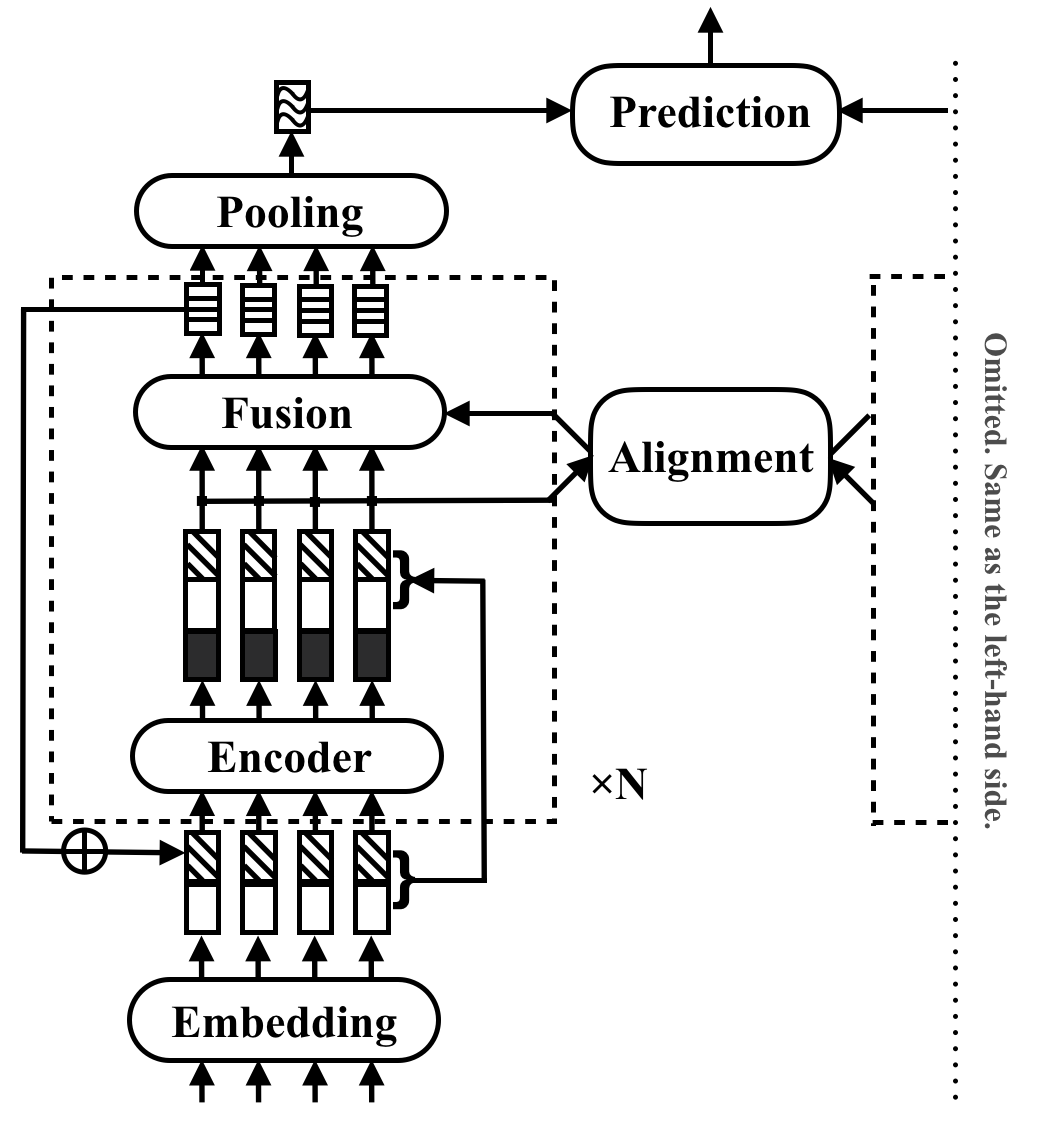
RE2는 범용 텍스트 매칭 응용 프로그램을위한 빠르고 강력한 신경 구조입니다. 텍스트 일치 작업에서 모델은 입력으로 두 개의 텍스트 시퀀스를 취하고 관계를 예측합니다. 이 방법은 이러한 작업에서 강력한 성능에 충분한 것을 탐색하는 것을 목표로합니다. 이전에 텍스트 일치에서 핵심 빌딩 블록으로 간주 된 많은 느린 구성 요소를 단순화하는 한편, 세 가지 주요 기능을 오리지널 포인트-시기 기능, 이전의 정렬 된 기능 및 컨텍스트 기능 등 세 가지 주요 기능을 직접 사용할 수 있습니다.
RE2는 4 가지 벤치 마크 데이터 세트에서 SNLI, Scitail, Quora 및 Wikiqa, 자연 언어 추론, 동작 식별 및 답변 선택 과제가없는 작업 별 적응에 대한 성능을 달성합니다. 유사하게 수행 된 모델에 비해 6 배 더 빠른 추론 속도를 가지고 있습니다.
다음 표에는 주요 실험 결과가 나와 있습니다. 이 논문은 10 런의 평균 및 표준 편차를보고합니다. 인텔 i7 CPU에서 8 쌍의 길이 20 쌍의 배치를 처리하여 추론 시간 (초)을 측정합니다. CSRAN 및 DIIN에서 사용하는 POS 기능의 계산 시간은 포함되지 않습니다.
| 모델 | snli | Scitail | Quora | 위키카 | 추론 시간 |
|---|---|---|---|---|---|
| bimpm | 86.9 | - | 88.2 | 0.731 | 0.05 |
| ESIM | 88.0 | 70.6 | - | - | - |
| 다이인 | 88.0 | - | 89.1 | - | 1.79 |
| CSRAN | 88.7 | 86.7 | 89.2 | - | 0.28 |
| RE2 | 88.9 ± 0.1 | 86.0 ± 0.6 | 89.2 ± 0.2 | 0.7618 ± 0.0040 | 0.03 ~ 0.05 |
구성 요소 및 실험 결과에 대한 자세한 내용은 논문을 참조하십시오.
pip install -r requirements.txtresources/논문에 사용 된 데이터는 다음과 같이 준비됩니다.
data/orig 에 대한 다운로드 및 분리 Snli (Tay et al.에 의해 사전 처리).cd data/orig/SNLI && gunzip *.gz )cd data && python prepare_snli.pydata/orig 로 다운로드하십시오.cd data && python prepare_scitail.pydata/orig .cd data && python prepare_quora.pydata/orig 에 대한 압축을 해제하십시오.cd data && python prepare_wikiqa.pymake -B 명령을 사용하여 qg-emnlp07-data/eval/trec_eval-8.0 에서 소스 파일을 컴파일하십시오. 이진 파일 "trec_eval"을 resources/ 로 이동하십시오. 새 텍스트 일치 모델을 훈련하려면 다음 명령을 실행하십시오.
python train.py $config_file .json5 구성 파일 예제 configs/ :
configs/main.json5 : 메인 실험 결과를 논문에서 복제하십시오.configs/robustness.json5 : 견고성 검사configs/ablation.json5 : 절제 연구자신의 구성 파일을 작성하는 지침 :
[
{
name : 'exp1' , // name of your experiment, can be the same across different data
__parents__ : [
'default' , // always put the default on top
'data/quora' , // data specific configurations in `configs/data`
// 'debug', // use "debug" to quick debug your code
] ,
__repeat__ : 5 , // how may repetitions you want
blocks : 3 , // other configurations for this experiment
} ,
// multiple configurations are executed sequentially
{
name : 'exp2' , // results under the same name will be overwritten
__parents__ : [
'default' ,
'data/quora' ,
] ,
__repeat__ : 5 ,
blocks : 4 ,
}
]구성 만 확인하려면 사용하십시오
python train.py $config_file .json5 --dry 존재하는 모델을 평가하려면 python evaluate.py $model_path $data_file 사용하십시오. 예는 다음과 같습니다.
python evaluate.py models/snli/benchmark/best.pt data/snli/train.txt
python evaluate.py models/snli/benchmark/best.pt data/snli/test.txt Pytorch 구현에서는 멀티 GPU 교육이 아직 지원되지 않습니다. 단일 16G GPU는 숨겨진 크기 200 및 배치 크기 512의 블록 <5를 할 때 훈련하기에 충분합니다. 강력성 검사를 제외한 모든 결과는 단일 16G GPU로 재생할 수 있습니다.
작업에서 RE2를 사용하는 경우 ACL 용지를 인용하십시오.
@inproceedings{yang2019simple,
title={Simple and Effective Text Matching with Richer Alignment Features},
author={Yang, Runqi and Zhang, Jianhai and Gao, Xing and Ji, Feng and Chen, Haiqing},
booktitle={Association for Computational Linguistics (ACL)},
year={2019}
}
이 프로젝트는 Apache License 2.0에 따라 있습니다.


