simple effective text matching pytorch
1.0.0
Esta es una implementación de Pytorch del documento de ACL 2019 "Matriota de texto simple y efectiva con características de alineación más ricas". La implementación original de TensorFlow: https://github.com/alibaba-edu/simple-effective-text-matching.
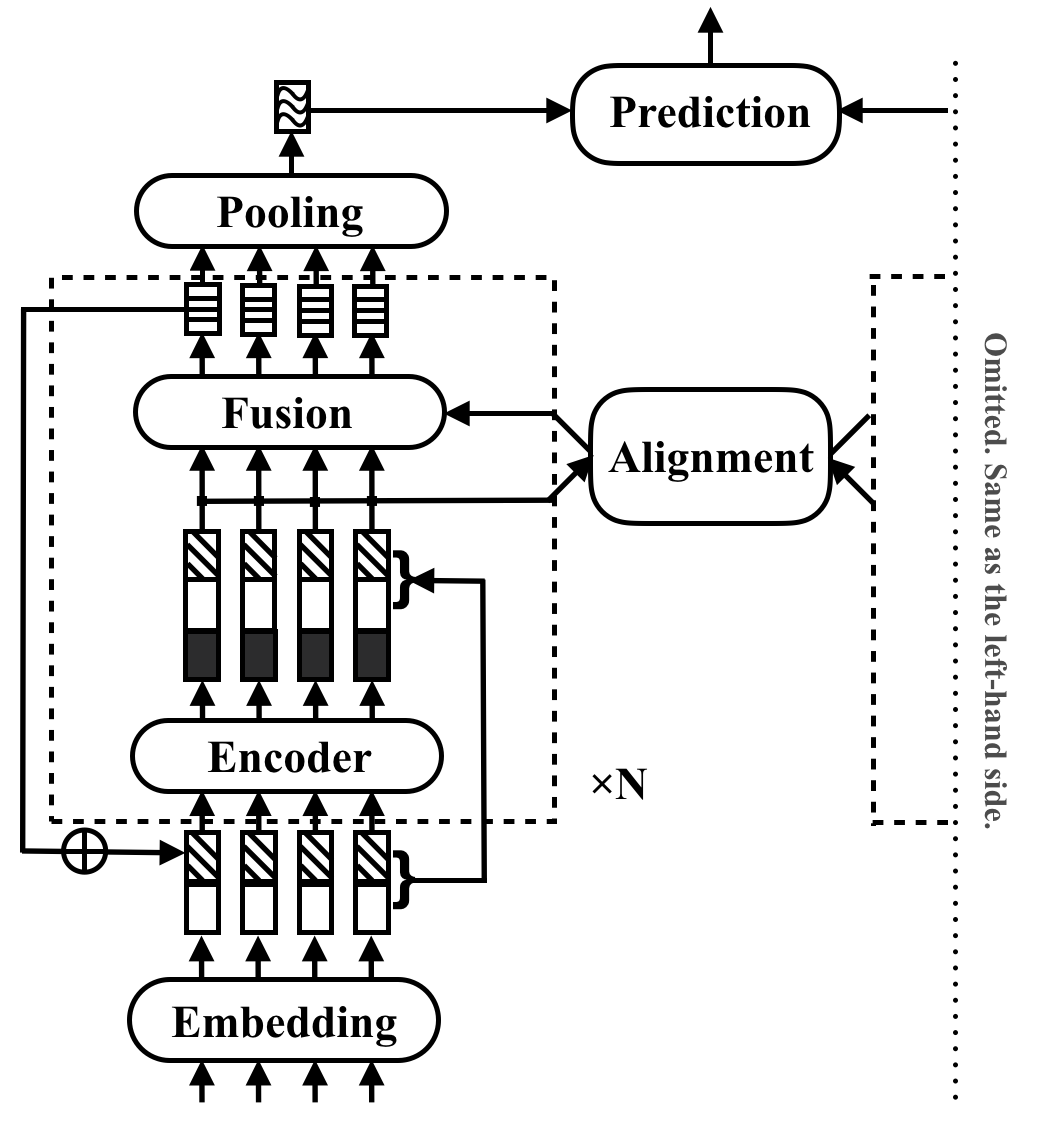
RE2 es una arquitectura neuronal rápida y fuerte para aplicaciones de coincidencia de texto de propósito general. En una tarea de coincidencia de texto, un modelo toma dos secuencias de texto como entrada y predice su relación. Este método tiene como objetivo explorar qué es suficiente para un fuerte rendimiento en estas tareas. Simplifica muchos componentes lentos que anteriormente se consideran como bloques de construcción de núcleo en la coincidencia de texto, al tiempo que mantiene tres características clave directamente disponibles para la alineación entre secuencias: características originales de punto, características alineadas anteriores y características contextuales.
RE2 logra el rendimiento a la par con el estado del arte en cuatro conjuntos de datos de referencia: SNLI, Scitail, Quora y Wikiqa, a través de tareas de inferencia del lenguaje natural, identificación de paráfrasis y selección de respuestas con ningún o pocas adaptaciones específicas de tareas. Tiene una velocidad de inferencia al menos 6 veces más rápida en comparación con los modelos realizados de manera similar.
La siguiente tabla enumera los principales resultados del experimento. El documento informa la desviación promedio y estándar de 10 corridas. El tiempo de inferencia (en segundos) se mide procesando un lote de 8 pares de longitud 20 en las CPU Intel I7. No se incluye el tiempo de cálculo de las características de POS utilizadas por Csran y Diin.
| Modelo | Snli | Caramelo | Quora | Wikiqa | Tiempo de inferencia |
|---|---|---|---|---|---|
| Bimpm | 86.9 | - | 88.2 | 0.731 | 0.05 |
| Esim | 88.0 | 70.6 | - | - | - |
| Diin | 88.0 | - | 89.1 | - | 1.79 |
| Csran | 88.7 | 86.7 | 89.2 | - | 0.28 |
| RE2 | 88.9 ± 0.1 | 86.0 ± 0.6 | 89.2 ± 0.2 | 0.7618 ± 0.0040 | 0.03 ~ 0.05 |
Consulte el documento para obtener más detalles de los componentes y los resultados del experimento.
pip install -r requirements.txtresources/Los datos utilizados en el documento se preparan de la siguiente manera:
data/orig .cd data/orig/SNLI && gunzip *.gz )cd data && python prepare_snli.pydata/orig .cd data && python prepare_scitail.pydata/orig .cd data && python prepare_quora.pydata/orig .cd data && python prepare_wikiqa.pymake -B para compilar los archivos de origen en qg-emnlp07-data/eval/trec_eval-8.0 . Mueva el archivo binario "trec_eval" a resources/ . Para entrenar un nuevo modelo de coincidencia de texto, ejecute el siguiente comando:
python train.py $config_file .json5 Los archivos de configuración de ejemplo se proporcionan en configs/ :
configs/main.json5 : replique el resultado del experimento principal en el papel.configs/robustness.json5 : comprobaciones de robustezconfigs/ablation.json5 : estudio de ablaciónLas instrucciones para escribir sus propios archivos de configuración:
[
{
name : 'exp1' , // name of your experiment, can be the same across different data
__parents__ : [
'default' , // always put the default on top
'data/quora' , // data specific configurations in `configs/data`
// 'debug', // use "debug" to quick debug your code
] ,
__repeat__ : 5 , // how may repetitions you want
blocks : 3 , // other configurations for this experiment
} ,
// multiple configurations are executed sequentially
{
name : 'exp2' , // results under the same name will be overwritten
__parents__ : [
'default' ,
'data/quora' ,
] ,
__repeat__ : 5 ,
blocks : 4 ,
}
]Para verificar solo las configuraciones, use
python train.py $config_file .json5 --dry Para evaluar un modelo existente, use python evaluate.py $model_path $data_file , aquí hay un ejemplo:
python evaluate.py models/snli/benchmark/best.pt data/snli/train.txt
python evaluate.py models/snli/benchmark/best.pt data/snli/test.txt Tenga en cuenta que la capacitación multi-GPU aún no está compatible en la implementación de Pytorch. Una sola GPU de 16 g es suficiente para el entrenamiento cuando los bloques <5 con el tamaño 200 oculto y el tamaño de lotes 512. Todos los resultados informados en el documento, excepto las controles de robustez, se pueden reproducir con un solo GPU de 16 g.
Cite el documento de ACL si usa RE2 en su trabajo:
@inproceedings{yang2019simple,
title={Simple and Effective Text Matching with Richer Alignment Features},
author={Yang, Runqi and Zhang, Jianhai and Gao, Xing and Ji, Feng and Chen, Haiqing},
booktitle={Association for Computational Linguistics (ACL)},
year={2019}
}
Este proyecto está bajo la licencia Apache 2.0.


