MKG_Analogy
1.0.0
ICLR2023 용지의 코드 및 데이터 세트 "지식 그래프에 대한 멀티 모달 유사성 추론"

이 연구에서 우리는 지식 그래프에 대한 새로운 다 유사성 추론의 새로운 작업을 제안합니다. 멀티 모드 유사성 추론 작업에 대한 개요는 다음과 같이 볼 수 있습니다.
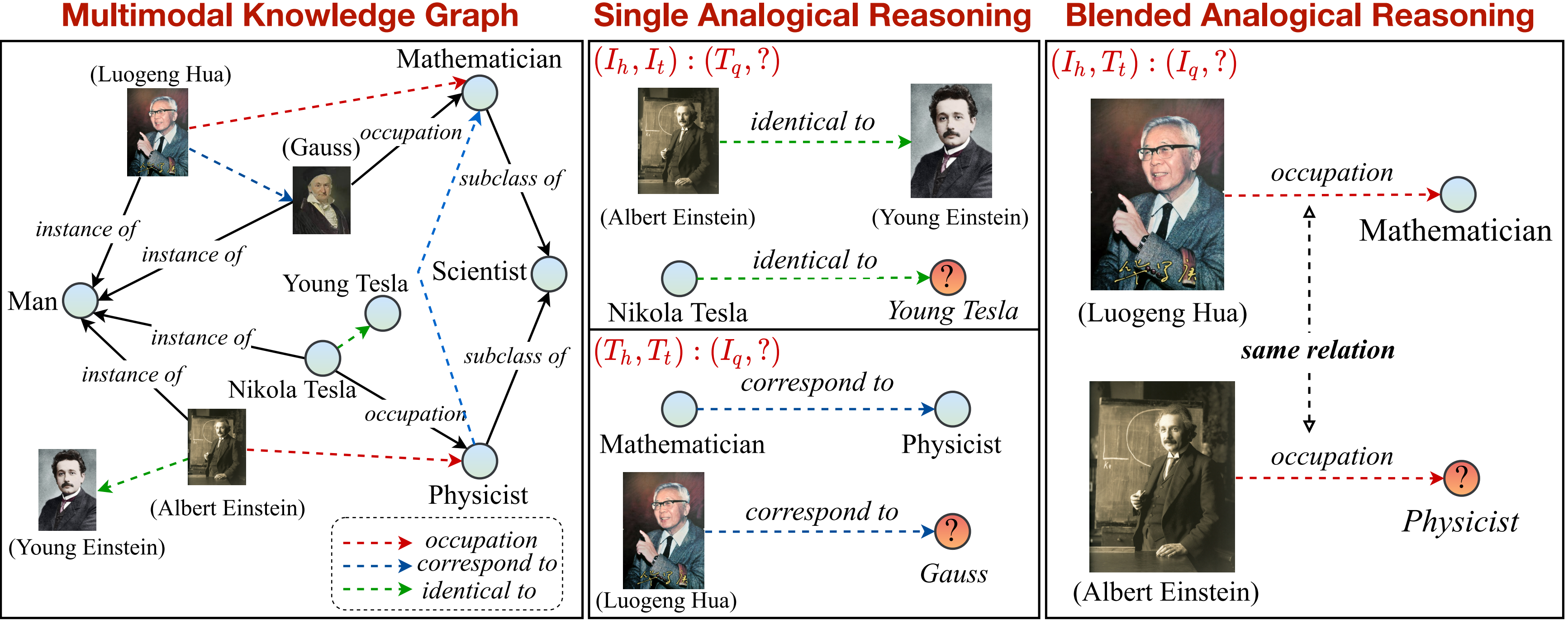
우리는 작업을 단일 및 혼합 패턴으로 지원하고 더 나누기위한 지식 그래프를 제공합니다. 점선 화살표로 표시된 관계 (
pip install -r requirements.txt
멀티 모드 유사성 추론 작업을 지원하기 위해 멀티 모달 지식 그래프 데이터 세트 Markg와 멀티 모달 유사성 추론 데이터 세트 화성을 수집합니다. 다음 그림과 같이 데이터 수집의 시각적 개요 :
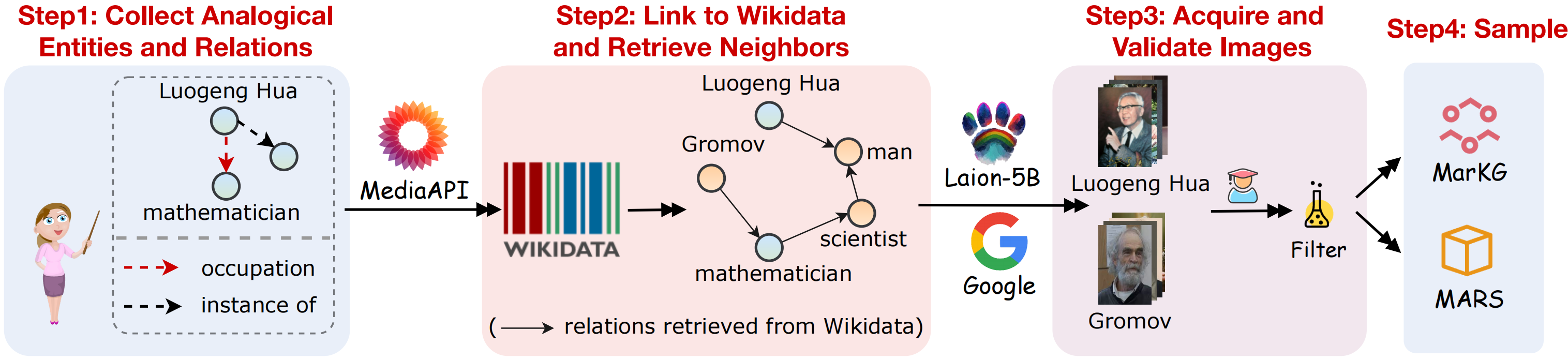
우리는 다음 단계를 따르는 데이터 세트를 수집합니다.
두 데이터 세트의 통계는 다음과 같은 그림에 표시됩니다.
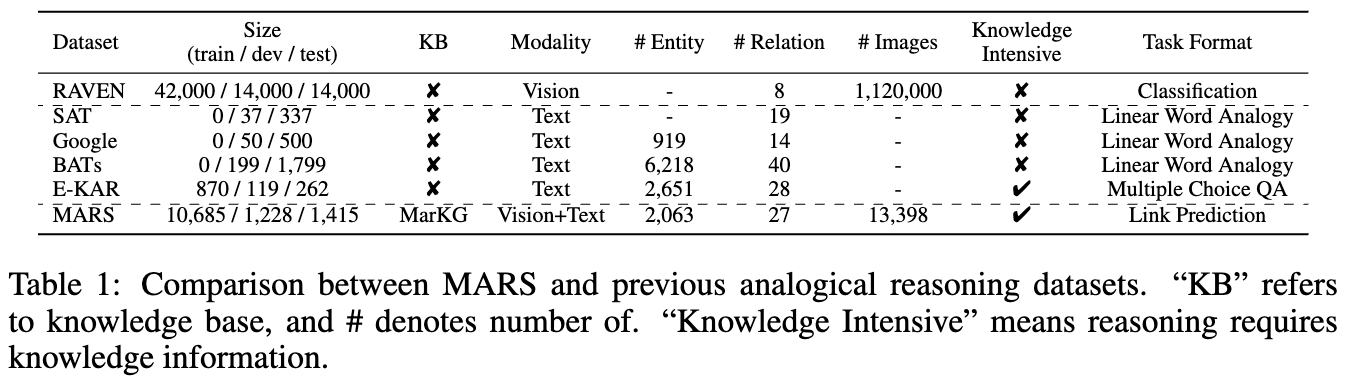
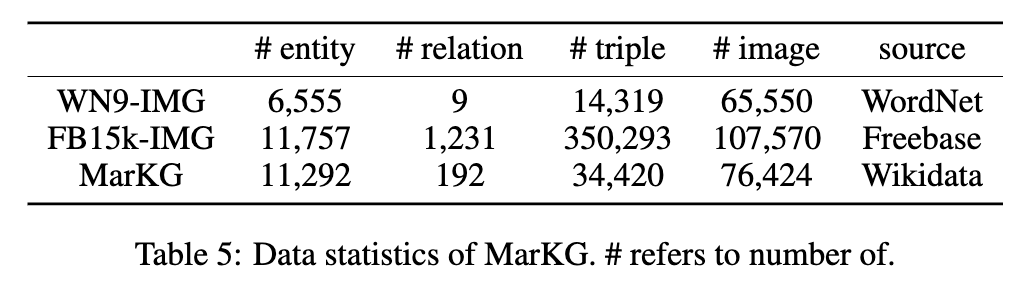
우리는 텍스트 데이터를 MarT/dataset/ 에 넣고 Google 드라이브 또는 Baidu Pan (Terabox) (Code : 7Hoc)을 통해 이미지 데이터를 다운로드하여 MarT/dataset/MARS/images 에 배치 할 수 있습니다. 자세한 내용은 Mart를 참조하십시오.
파일의 예상 구조는 다음과 같습니다.
MKG_Analogy
|-- M-KGE # multimodal knowledge representation methods
| |-- IKRL_TransAE
| |-- RSME
|-- MarT
| |-- data # data process functions
| |-- dataset
| | |-- MarKG # knowledge graph data
| | |-- MARS # analogical reasoning data
| |-- lit_models # pytorch_lightning models
| |-- models # source code of models
| |-- scripts # running scripts
| |-- tools # tool function
| |-- main.py # main function
|-- resources # image resources
|-- requirements.txt
|-- README.md
우리는 다중 모드 지식 표현 방법 (IKRL, Transae, RSME), 미리 훈련 된 비전 언어 모델 (Visualbert, Vilbert, Vilt, Flava) 및 MKGFormer (Multimodal Knowledge Graph Completion Method)를 포함하여 화성에서 초기 벤치 마크 결과를 설정하기위한 몇 가지 기준 방법을 선택합니다.
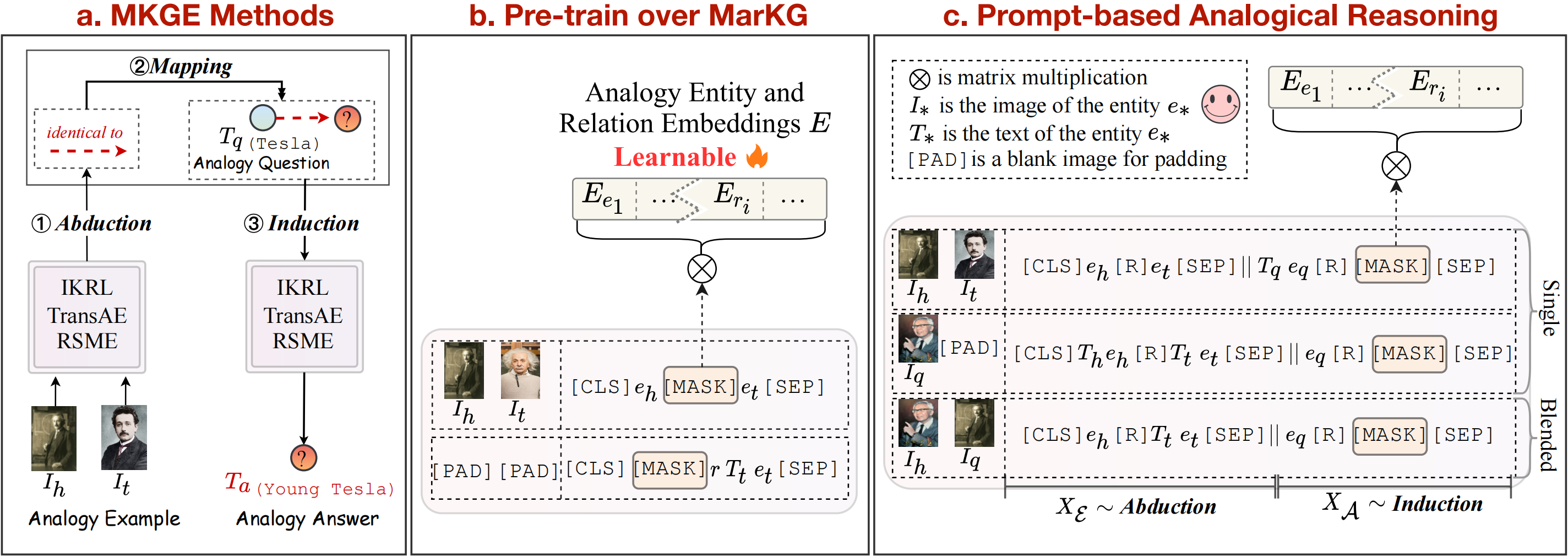
또한, 우리는 구조-매핑 이론을 따라 abudcction-mapping-induction을 다중 모드 지식 표현 방법에 대한 명시 적 Pipline 단계로 간주합니다. 변압기 기반 방법에 관해서는, 우리는 또한이 세 단계를 암시 적으로 결합하여 멀티 모달 유사성 추론 작업 종단-엔드를 달성하는 새로운 프레임 워크 인 Mart를 추가로 제안합니다. 기준 방법의 개요는 위 그림에서 볼 수 있습니다.
Transae 프레임 워크를 통해 IKRL 모델을 재현하여 다음 코드를 실행하고 IKRL을 평가합니다.
cd M-KGE/IKRL_TransAE
python IKRL.py IKRL.py 에서 각각 finetune 및 analogy 매개 변수를 수정하여 사전 트레인/미세 조정 및 Transe/Aralogy를 선택할 수 있습니다.
다음 코드를 실행하고 IKRL을 평가하려면 다음과 같은 코드를 실행하십시오.
cd M-KGE/IKRL_TransAE
python TransAE.py TransAE.py 에서 각각 finetune 및 analogy 매개 변수를 수정하여 사전 트레인/미세 조정 및 Transe/Aralogy를 선택할 수 있습니다.
RSME에 대한 데이터의 일부만 제공합니다. RSME를 평가하려면 다음 스크립트를 통해 전체 데이터를 생성해야합니다.
cd M-KGE/RSME
python image_encoder.py # -> analogy_vit_best_img_vec.pickle
python utils.py # -> img_vec_id_analogy_vit.pickle첫째, Markg에 대한 모델을 미리 훈련하십시오.
bash run.sh 그런 다음 --checkpoint 매개 변수를 수정하고 화성에서 모델을 미세 조정하십시오.
bash run_finetune.sh위의 모델에 대한 더 많은 교육 세부 사항은 해외 리포지토리를 참조 할 수 있습니다.
변압기 기반 모델을 위해 Mart 프레임 워크를 활용합니다. Mart에는 사전 훈련 및 미세 조정의 두 단계가 포함되어 있습니다.
모델을 빠르게 훈련시키기 위해이 스크립트를 사용하여 이미지 데이터를 미리 인코딩합니다 (인코딩 된 데이터의 크기는 약 7GB).
cd MarT
python tools/encode_images_data.pymkgformer를 예로 들어, 먼저 다음 스크립트를 통해 모델을 미리 훈련하십시오.
bash scripts/run_pretrain_mkgformer.sh사전 훈련 후 다음 스크립트를 통해 모델을 미세 조정하십시오.
bash scripts/run_finetune_mkgformer.sh ? 우리는이 Google 드라이브에서 미세 조정 및 사전 훈련 문구 중에 변압기 기반 모델의 최상의 체크 포인트를 제공합니다. 실험 테스트를 위해 scripts/run_finetune_xxx.sh 에 --only_test 추가하십시오.
우리의 작업을 사용하거나 연장하는 경우 다음과 같이 논문을 인용하십시오.
@inproceedings {
zhang2023multimodal,
title = { Multimodal Analogical Reasoning over Knowledge Graphs } ,
author = { Ningyu Zhang and Lei Li and Xiang Chen and Xiaozhuan Liang and Shumin Deng and Huajun Chen } ,
booktitle = { The Eleventh International Conference on Learning Representations } ,
year = { 2023 } ,
url = { https://openreview.net/forum?id=NRHajbzg8y0P }
}

