MKG_Analogy
1.0.0
Code et ensembles de données pour l'article ICLR2023 "raisonnement analogique multimodal sur les graphiques de connaissances"

Dans ce travail, nous proposons une nouvelle tâche de raisonnement analogique multimodal sur le graphique de connaissances. Un aperçu de la tâche de raisonnement analogique multimodal peut être considéré comme suit:
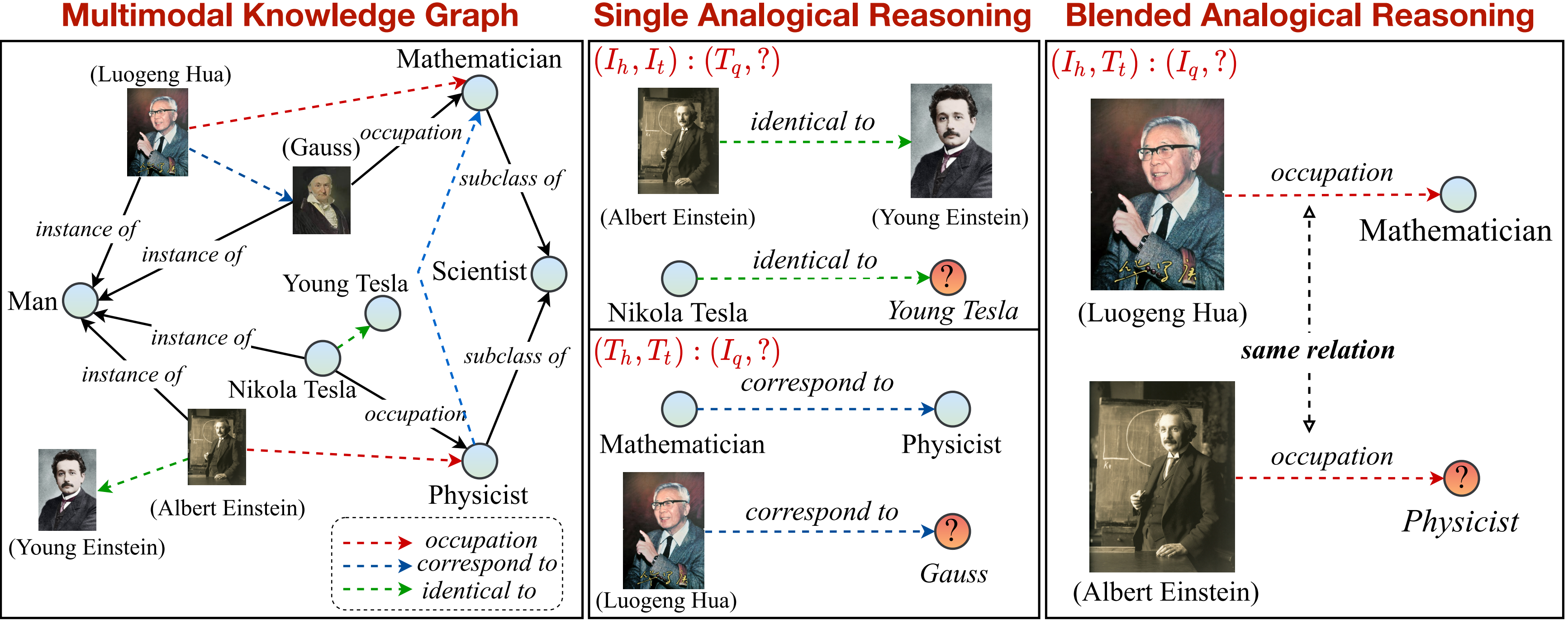
Nous fournissons un graphique de connaissances pour soutenir et diviser davantage la tâche en modèles uniques et mélangés. Notez que la relation marquée par des flèches en pointillés (
pip install -r requirements.txt
Pour prendre en charge la tâche de raisonnement analogique multimodal, nous collectons un jeu de données de graphiques de connaissances multimodal MarkG et un jeu de données de raisonnement analogique multimodal Mars. Un aperçu visuel de la collecte de données comme indiqué dans la figure suivante:
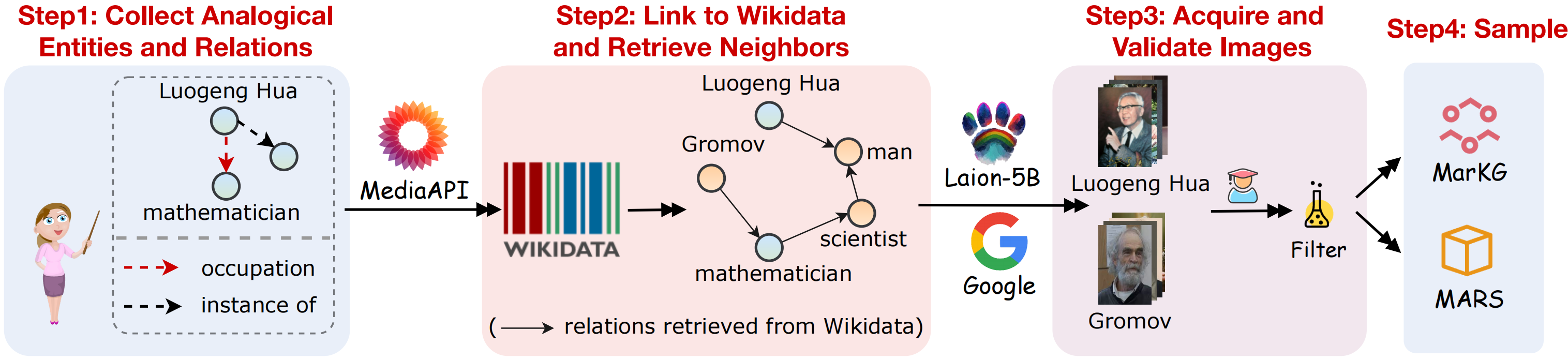
Nous collectons les ensembles de données suivant les étapes ci-dessous:
Les statistiques des deux ensembles de données sont présentées dans les chiffres suivants:
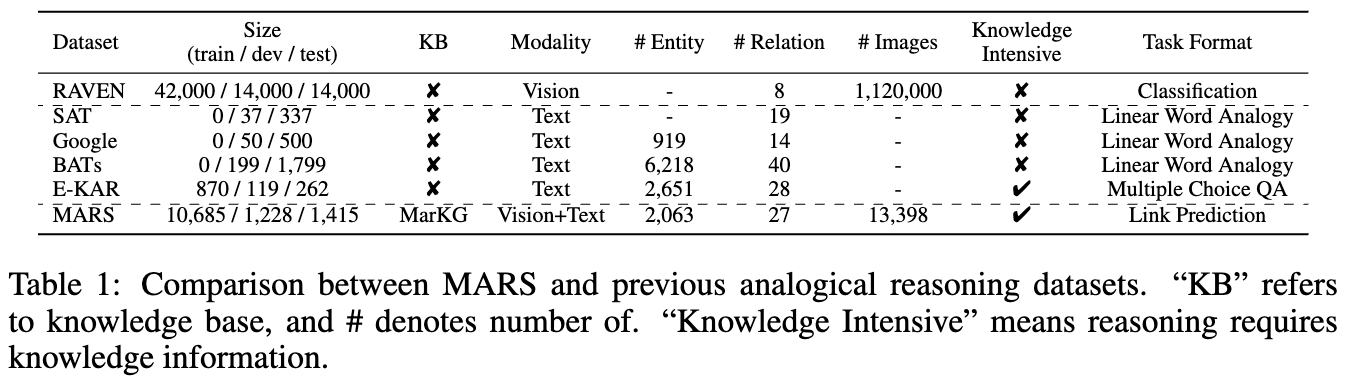
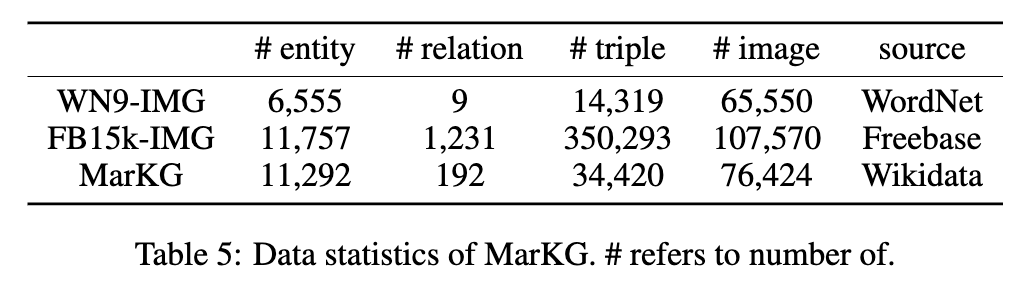
Nous mettons les données de texte sous MarT/dataset/ , et les données d'image peuvent être téléchargées via Google Drive ou le Baidu Pan (Terabox) (code: 7HOC) et placés sur MarT/dataset/MARS/images . Veuillez vous référer à Mart pour plus de détails.
La structure attendue des fichiers est:
MKG_Analogy
|-- M-KGE # multimodal knowledge representation methods
| |-- IKRL_TransAE
| |-- RSME
|-- MarT
| |-- data # data process functions
| |-- dataset
| | |-- MarKG # knowledge graph data
| | |-- MARS # analogical reasoning data
| |-- lit_models # pytorch_lightning models
| |-- models # source code of models
| |-- scripts # running scripts
| |-- tools # tool function
| |-- main.py # main function
|-- resources # image resources
|-- requirements.txt
|-- README.md
Nous sélectionnons certaines méthodes de référence pour établir les résultats de référence initiaux sur Mars, y compris les méthodes de représentation des connaissances multimodales (IKRL, Transae, RSME), les modèles pré-formés en langue de vision (Visualbert, Vilbert, Vilt, Flava) et une méthode d'achèvement du graphique de connaissances multimodales (MKGFORMER).
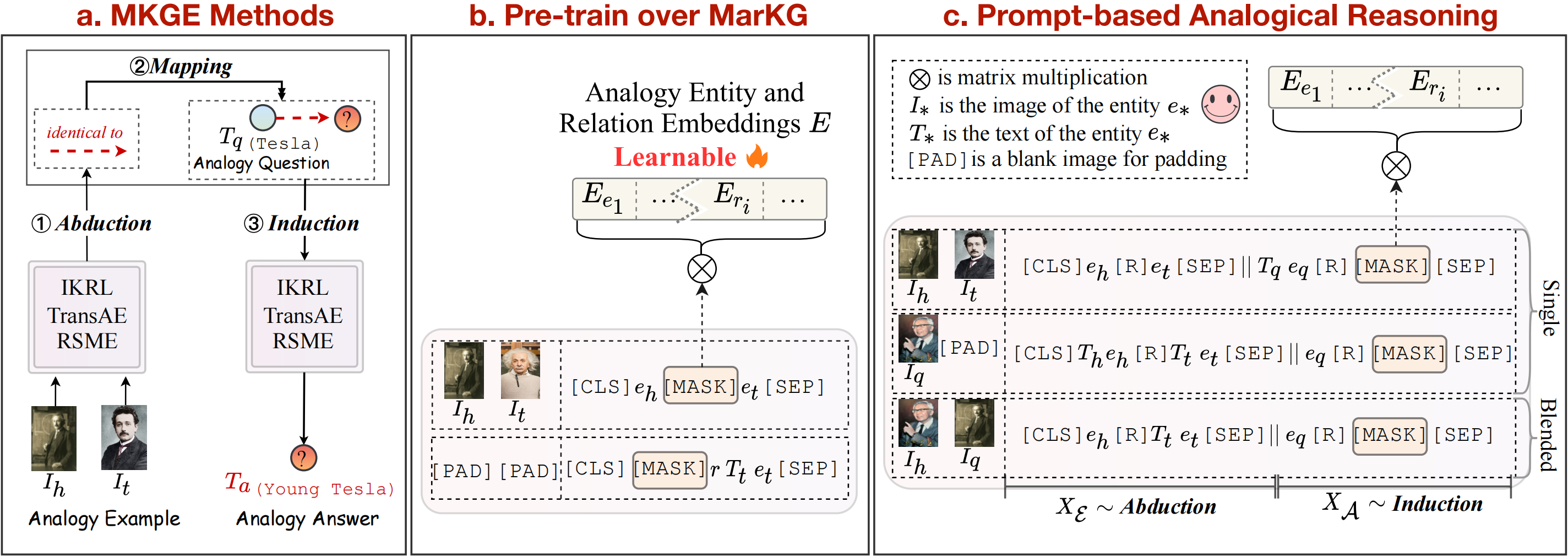
De plus, nous suivons la théorie de la cartographie de la structure pour considérer l'induction de la mappage d'abudction comme des étapes explicites de ligne de pip pour les méthodes de représentation des connaissances multimodales. Quant aux méthodes basées sur les transformateurs, nous proposons en outre Mart, un nouveau cadre qui combine implicitement ces trois étapes pour accomplir la tâche de raisonnement analogique multimodal de bout en bout, ce qui peut éviter la propagation des erreurs pendant le raisonnement analogique. L'aperçu des méthodes de base peut être vu dans la figure ci-dessus.
Nous reproduisons les modèles IKRL via Transae Framework, pour évaluer sur IKRL, exécutant le code suivant:
cd M-KGE/IKRL_TransAE
python IKRL.py Vous pouvez choisir un pré-transfort / affineur et un transe / analogie en modifiant les paramètres finetune et analogy dans IKRL.py , respectivement.
Pour évaluer sur IKRL, exécuter le code suivant:
cd M-KGE/IKRL_TransAE
python TransAE.py Vous pouvez choisir un prétraitement / affiner et un transe / analogie en modifiant les paramètres finetune et analogy dans TransAE.py , respectivement.
Nous ne fournissons qu'une partie des données pour RSME. Pour évaluer sur RSME, vous devez générer les données complètes en suivant les scripts:
cd M-KGE/RSME
python image_encoder.py # -> analogy_vit_best_img_vec.pickle
python utils.py # -> img_vec_id_analogy_vit.pickleTout d'abord, pré-entraînez les modèles sur Markg:
bash run.sh Modifiez ensuite le paramètre --checkpoint et affinez les modèles sur Mars:
bash run_finetune.shPlus de détails de formation sur les modèles ci-dessus peuvent faire référence à leurs référentiels officiels.
Nous tirons parti du cadre MART pour les modèles basés sur les transformateurs. MART contient deux étapes: prétraitement et affinure.
Pour former les modèles rapidement, nous codons les données de l'image à l'avance avec ce script (notez que la taille des données codées est d'environ 7 Go):
cd MarT
python tools/encode_images_data.pyPrenant l'exemple de mkgformer, pré-entraînez d'abord le modèle via le script suivant:
bash scripts/run_pretrain_mkgformer.shAprès la pré-formation, affinez le modèle via le script suivant:
bash scripts/run_finetune_mkgformer.sh ? Nous fournissons les meilleurs points de contrôle des modèles basés sur les transformateurs lors des phrases finales et pré-formation sur ce Google Drive. Téléchargez-les et ajoutez --only_test dans scripts/run_finetune_xxx.sh pour tester des expériences.
Si vous utilisez ou étendez notre travail, veuillez citer le papier comme suit:
@inproceedings {
zhang2023multimodal,
title = { Multimodal Analogical Reasoning over Knowledge Graphs } ,
author = { Ningyu Zhang and Lei Li and Xiang Chen and Xiaozhuan Liang and Shumin Deng and Huajun Chen } ,
booktitle = { The Eleventh International Conference on Learning Representations } ,
year = { 2023 } ,
url = { https://openreview.net/forum?id=NRHajbzg8y0P }
}

