voicesmith
v0.2.0
Voicesmith는 코딩 경험없이 단일 및 멀티 스피커 모델을 모두 훈련하고 추론 할 수있게합니다. 데이터 세트에서 Delightfultts 및 Univnet의 수정 된 버전을 기반으로 Speech Pipeline에 대해 매우 견고한 텍스트를 미세 조정합니다. 두 모델 모두 독점적 인 5000 스피커 데이터 세트에서 사전에 사전 처리되었습니다. 또한 자동 텍스트 정규화와 같은 데이터 세트 전처리를위한 몇 가지 도구를 제공합니다.
이 소프트웨어의 이전 버전을 사용하여 매우 감정적 인 감정적 인 60 스피커 데이터 세트에 대한 교육을받은 모델을 사용하려면 여기를 클릭하십시오.
Node.js의 최신 버전이 설치되어 있는지 확인하십시오.
저장소를 복제하십시오
git clone https://github.com/dunky11/voicesmith
종속성을 설치하면 1 분이 걸릴 수 있습니다
cd voicesmith
npm install
여기를 클릭하고 최신 버전으로 폴더를 선택하고 모든 파일을 다운로드하여 리포지토리 자산 폴더 내에 배치하십시오.
프로젝트를 시작하십시오
npm start
위에서 1-4 단계를 따르십시오.
RUN MAKE, 이것은 내부 설치자가있는 폴더를 만듭니다. 설치 프로그램은 운영 체제를 기준으로 다릅니다.
npm make
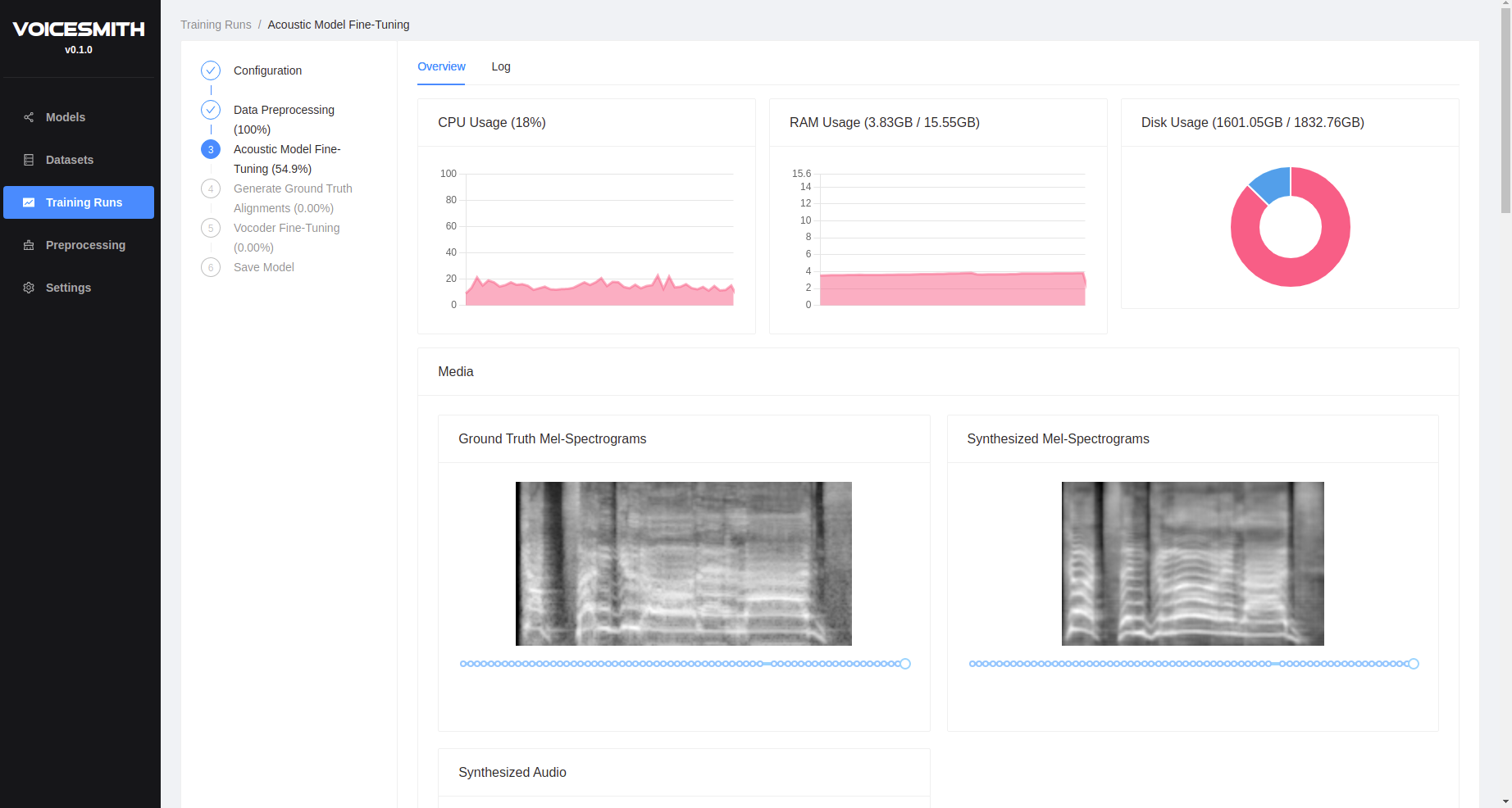
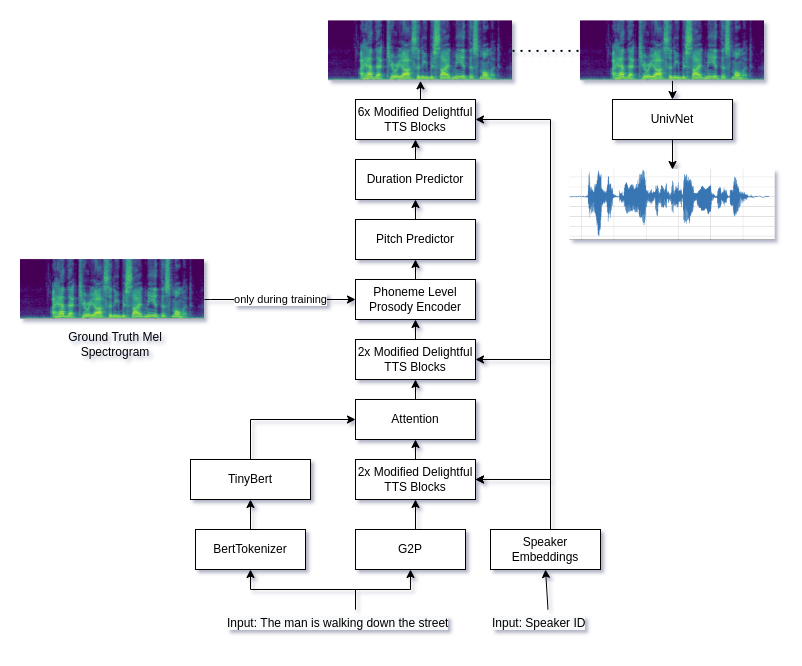
Voicesmith는 현재 2 단계 수정 된 Delightfultts 및 Univnet 파이프 라인을 사용합니다.
프로젝트에서 귀하의 지원을 보여주십시오. 풀 요청은 항상 환영합니다.
이 프로젝트는 Apache -2.0 라이센스에 따라 라이센스가 부여됩니다. 자세한 내용은 License.md 파일을 참조하십시오.


