voicesmith
v0.2.0
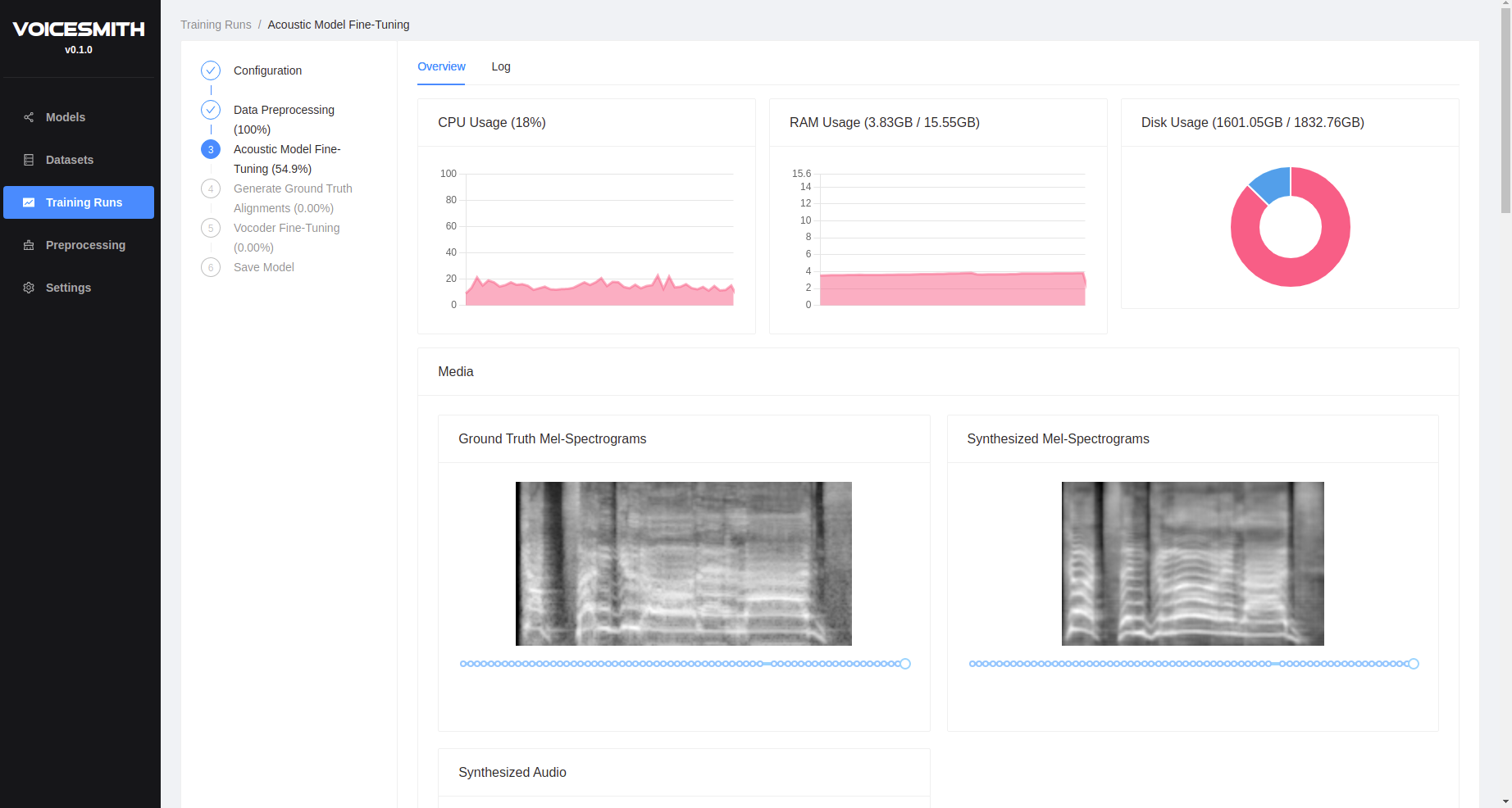
Voicesmith permite entrenar e inferir en modelos individuales y multiespeaker sin ninguna experiencia de codificación. Atunta un texto bastante sólido a la tubería del habla basada en una versión modificada de DelightfullTts y Univnet en su conjunto de datos. Ambos modelos estaban provocados en un conjunto de datos de altavoces 5000 patentado. También proporciona algunas herramientas para el preprocesamiento del conjunto de datos como la normalización automática de texto.
Si desea jugar con un modelo entrenado en un conjunto de datos de altavoces emocional altamente emocional de 60 utilizando una versión anterior de este software, haga clic aquí.
Asegúrese de tener la última versión de Node.js instalada
Clonar el repositorio
git clone https://github.com/dunky11/voicesmith
Instalar dependencias, esto puede tomar un minuto
cd voicesmith
npm install
Haga clic aquí, seleccione la carpeta con la última versión, descargue todos los archivos y colóquelos dentro de la carpeta de activos de repositorios.
Comience el proyecto
npm start
Siga los pasos 1 - 4 desde arriba.
Ejecutar Make, esto creará una carpeta llamada/Make con un instalador en el interior. El instalador será diferente según su sistema operativo.
npm make
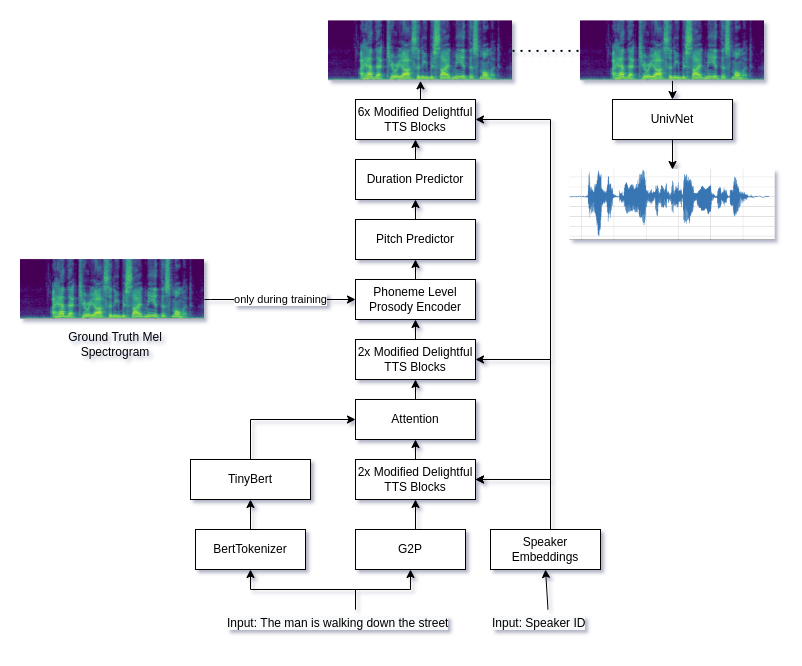
VoicesMith actualmente utiliza una DelightfullFulTts modificada de dos etapas y una tubería Univnet.
Muestre su apoyo del proyecto. Las solicitudes de extracción siempre son bienvenidas.
Este proyecto tiene licencia bajo la licencia Apache -2.0: consulte el archivo License.md para obtener más detalles.


