vector database food similarity
1.0.0
개방형 음식 사실을 기반으로하는 Chroma 벡터 데이터베이스가있는 식품에 대한 유사성 권장 사항 사용 사례.
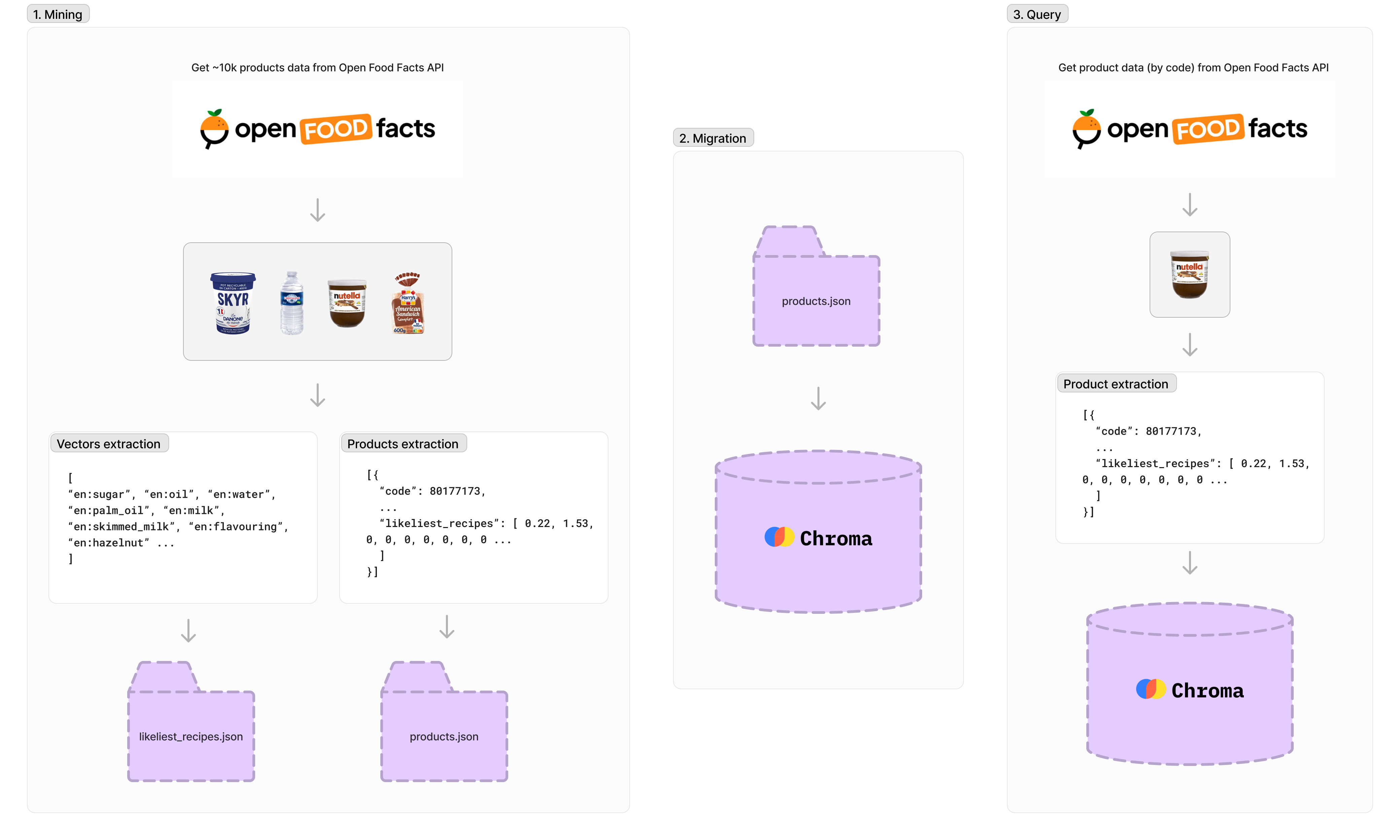
Open Food Facts API를 사용하여 약 10,000 개의 제품을 검색하지만 일부 제품에는 정보가 부족하므로 처리 후 약 4,300 개의 제품이 있습니다. 각 제품에는 고유 한 식별자, 이름, 이미지 URL 및 성분의 백분율이 있습니다. 1,500 개가 넘는 인덱스 벡터가 있으며, 각 벡터는 총 식품 (예 : 설탕, 오일, 물 등)의 성분의 백분율을 나타냅니다.
데이터 세트 생성을 시작하려면 다음 명령을 실행하십시오.
npm run data-mining 마이그레이션은 제품 데이터 세트 ( products.json )를 로컬 Chroma 데이터베이스로 내보낼 것입니다.
마이그레이션을 시작하려면 실행하십시오.
npm run migration 벡터 데이터베이스에 대한 쿼리를 수행하려면 제품 데이터에서 벡터를 생성해야합니다.
먼저 Open Food Facts Product API라고합니다. 그런 다음 임베딩을위한 벡터를 생성하고 ( likeliest_recipes.json ) 데이터베이스에 요청하는 데 사용합니다.
기본적으로 Chroma 데이터베이스에서 쿼리가 수행되면 Squared L2 Norm 벡터 규범을 사용하여 유사한 제품을 결정합니다.
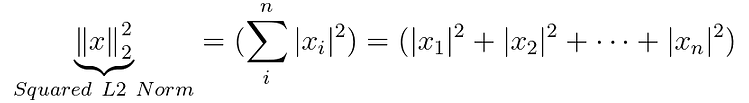
Inner product 또는 Cosine similarity , Chroma 및 HNSWLIB에 대한 자세한 내용과 같은 다른 벡터 규범도 사용할 수 있습니다.
npm cidocker run -p 8000:8000 chromadb/chroma:0.4.213017620429484 : https://world.openfoodfacts.org/3017620429484/nutella-heazelnut-spread-ferrero)에서 찾을 수 있습니다. node ./query.js product=3017620429484모든 데이터 세트는 Open Food Facts API를 사용하여 추출되었습니다. Open Food Facts 프로젝트에 기부하십시오
이 프로젝트는 GNU AGPL V3 라이센스로 라이센스가 부여됩니다.
자세한 내용은 라이센스를 참조하십시오.


