vector database food similarity
1.0.0
Cas d'utilisation des recommandations de similitude pour les produits alimentaires avec une base de données Vector Chroma basée sur des faits alimentaires ouverts.
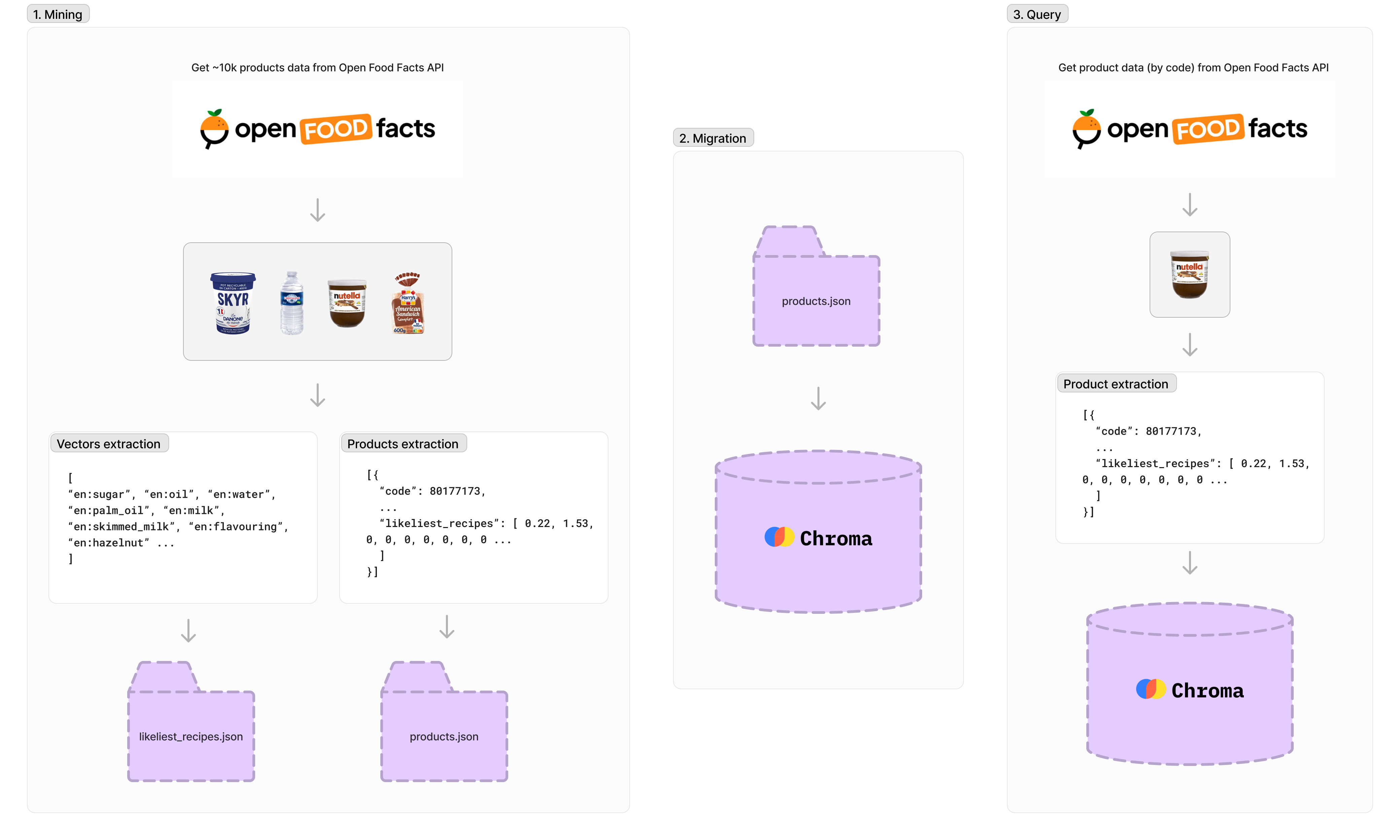
Environ 10 000 produits sont récupérés à l'aide de l'API Open Food Facts, mais certains produits manquent d'informations, donc après le traitement, nous avons environ 4 300 produits. Chaque produit a un identifiant unique, un nom, une URL d'image et le pourcentage d'ingrédients. Il y a plus de 1 500 vecteurs indexés, chaque vecteur représentant le pourcentage d'un ingrédient dans le produit alimentaire total (comme le sucre, l'huile, l'eau, etc.).
Pour initier la génération d'ensembles de données, exécutez la commande suivante:
npm run data-mining La migration exportera des ensembles de données de produits ( products.json ) vers la base de données de chrome locale.
Pour lancer la migration, exécutez:
npm run migration Pour effectuer une requête dans la base de données vectorielle, vous devez générer des vecteurs à partir des données du produit.
Tout d'abord, nous appelons l'API du produit Open Food Facts. Ensuite, nous générons des vecteurs pour l'intégration ( likeliest_recipes.json ) et les utilisons pour faire une demande à la base de données.
Par défaut, lorsqu'une requête est effectuée sur la base de données de chroma, les produits similaires sont déterminés à l'aide de la norme vectorielle Squared L2 Norm :
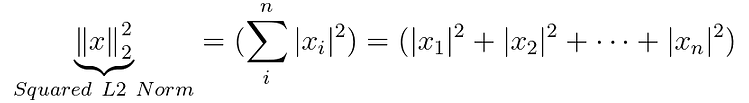
D'autres normes vectorielles sont également disponibles telles que la Cosine similarity Inner product ou du cosinus, plus de détails sur le chroma et le HNSWLIB.
npm cidocker run -p 8000:8000 chromadb/chroma:0.4.213017620429484 : https://world.openfoodfacts.org/product/3017620429484/nutella-helnut-spread-ferrero) node ./query.js product=3017620429484Tous les ensembles de données ont été extraits à l'aide de l'API Open Food Facts. Don à Open Food Facts Project
Ce projet est autorisé avec une licence GNU AGPL V3.
Voir la licence pour plus de détails.


