vector database food similarity
1.0.0
Gunakan kasus rekomendasi kesamaan untuk produk makanan dengan database vektor chroma berdasarkan fakta makanan terbuka.
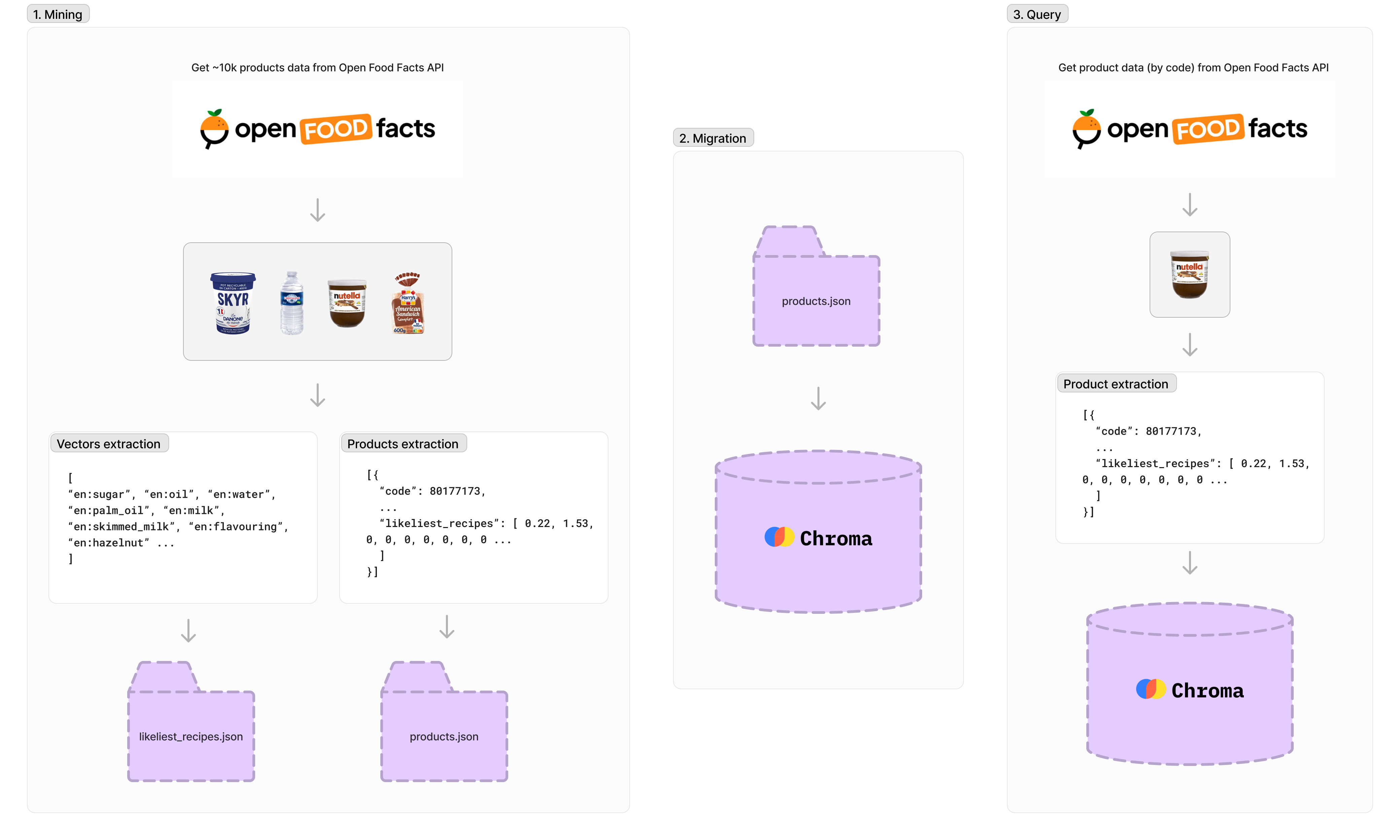
Sekitar 10.000 produk diambil menggunakan API Fakta Makanan Terbuka tetapi beberapa produk kekurangan informasi, jadi setelah diproses, kami memiliki sekitar 4.300 produk. Setiap produk memiliki pengidentifikasi unik, nama, URL gambar, dan persentase bahan. Ada lebih dari 1.500 vektor yang diindeks, dengan masing -masing vektor mewakili persentase bahan dalam total produk makanan (seperti gula, minyak, air, dll.).
Untuk memulai pembuatan dataset, jalankan perintah berikut:
npm run data-mining Migrasi akan mengekspor Dataset Produk ( products.json ) ke database Chroma lokal.
Untuk meluncurkan migrasi, jalankan:
npm run migration Untuk melakukan kueri ke database vektor, Anda perlu menghasilkan vektor dari data produk.
Pertama, kami menyebut API Produk Fakta Makanan Terbuka. Kemudian, kami menghasilkan vektor untuk embedding ( likeliest_recipes.json ) dan menggunakannya untuk membuat permintaan ke database.
Secara default, ketika kueri dilakukan pada database Chroma, produk serupa ditentukan menggunakan norma vektor Squared L2 Norm :
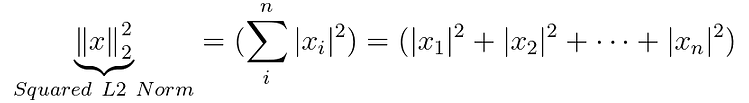
Norma vektor lainnya juga tersedia seperti Inner product atau Cosine similarity , lebih detail tentang Chroma dan HNSWLIB.
npm cidocker run -p 8000:8000 chromadb/chroma:0.4.213017620429484 : https://world.openfoodfacts.org/product/3017620429484/nutella-hazelnut-spread-ferrero) node ./query.js product=3017620429484Semua set data telah diekstraksi menggunakan API Fakta Makanan Terbuka. Donasi untuk Proyek Fakta Makanan Terbuka
Proyek ini dilisensikan dengan lisensi GNU AGPL V3.
Lihat lisensi untuk detail lebih lanjut.


