vector database food similarity
1.0.0
Caso de uso de recomendaciones de similitud para productos alimenticios con la base de datos de Chroma Vector basada en hechos alimenticios abiertos.
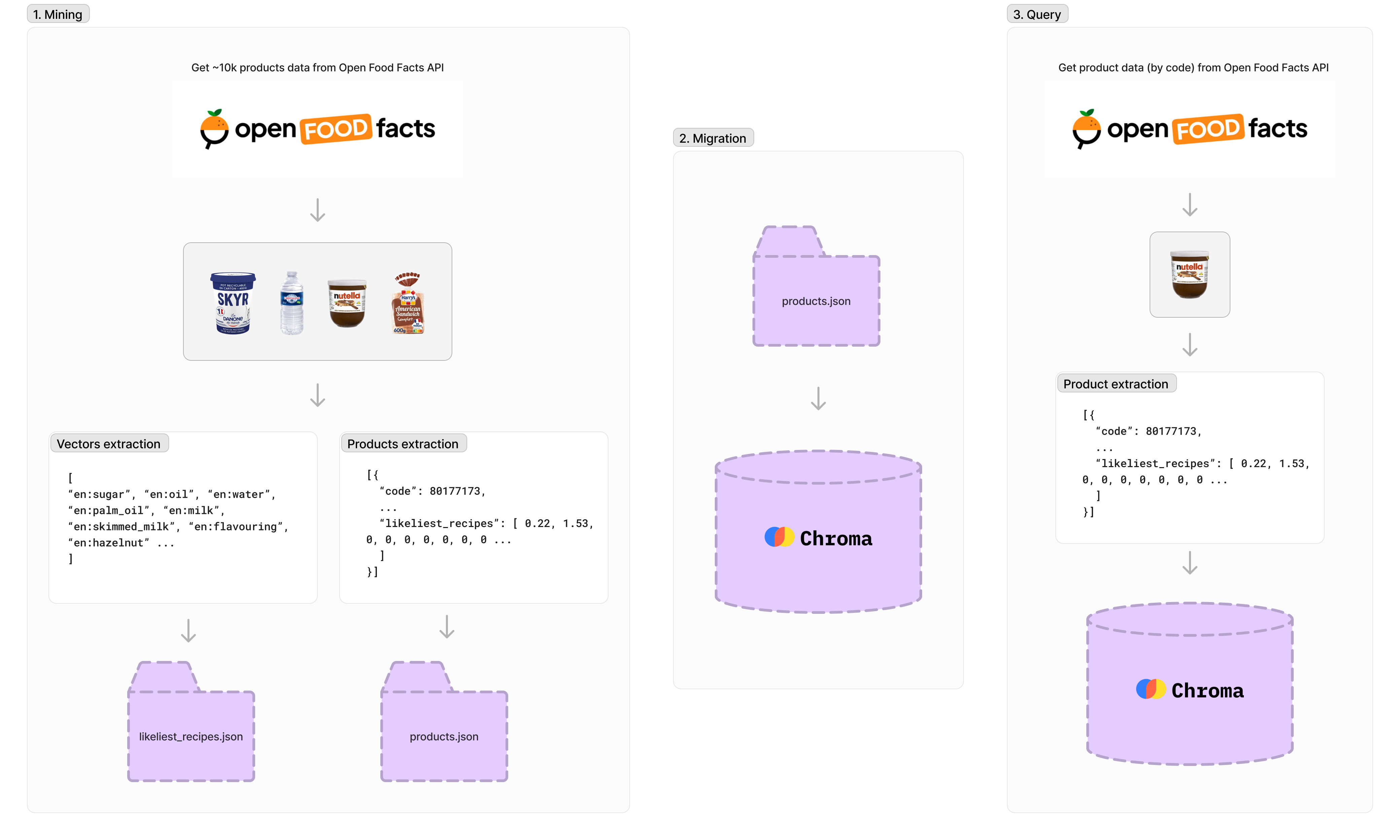
Alrededor de 10,000 productos se recuperan utilizando la API Open Food Data, pero algunos productos carecen de información, por lo que después del procesamiento, tenemos alrededor de 4,300 productos. Cada producto tiene un identificador, nombre, URL de imagen y el porcentaje de ingredientes. Hay más de 1.500 vectores indexados, y cada vector representa el porcentaje de un ingrediente en el producto alimentario total (como azúcar, aceite, agua, etc.).
Para iniciar la generación de conjuntos de datos, ejecute el siguiente comando:
npm run data-mining La migración exportará conjuntos de datos de productos ( products.json ) a la base de datos de Chroma local.
Para lanzar la migración, ejecute:
npm run migration Para realizar una consulta a la base de datos Vector, debe generar vectores a partir de datos del producto.
Primero, llamamos a la API del producto Open Food Data. Luego, generamos vectores para incrustar ( likeliest_recipes.json ) y los usamos para hacer una solicitud a la base de datos.
Por defecto, cuando se realiza una consulta en la base de datos de Chroma, se determinan productos similares utilizando la norma de Squared L2 Norm :
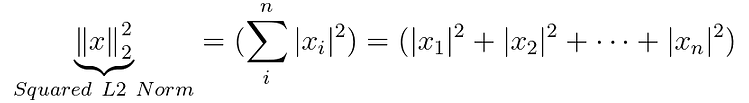
Otras normas vectoriales también están disponibles, como el Inner product o Cosine similarity , más detalles sobre Chroma y HNSWLIB.
npm cidocker run -p 8000:8000 chromadb/chroma:0.4.213017620429484 : https://world.openfoodfacts.org/product/3017620429484/nutella-hazelnut-spread-ferrero) node ./query.js product=3017620429484Todos los conjuntos de datos se han extraído utilizando la API Open Food Data. Donar para abrir el proyecto de datos de alimentos
Este proyecto tiene licencia con la licencia GNU AGPL V3.
Vea la licencia para más detalles.


