vector database food similarity
1.0.0
Use case of similarity recommendations for food products with Chroma vector database based on Open Food Facts.
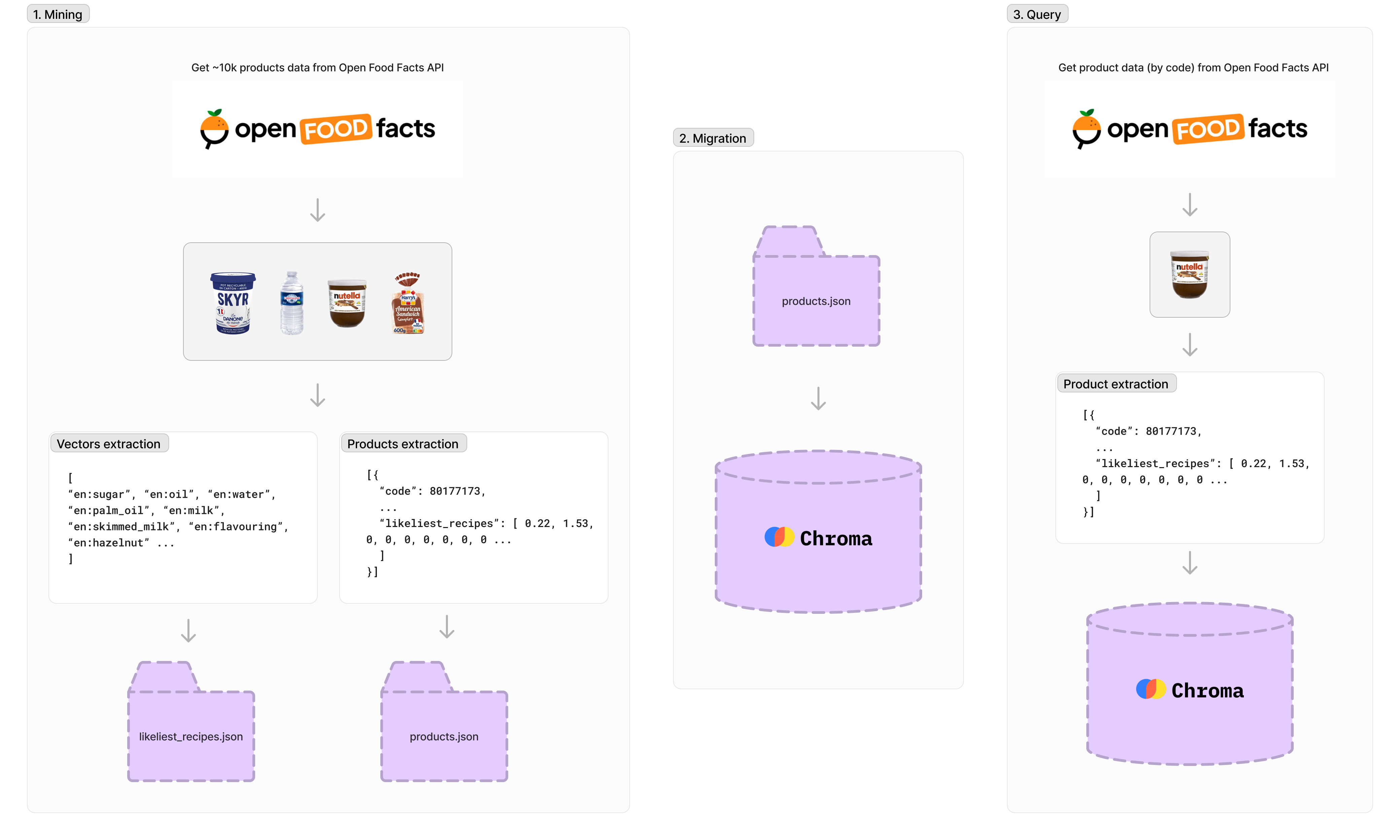
Around 10,000 products are retrieved using the Open Food Facts API but some products lack information, so after processing, we have around 4,300 products.
Each product has a unique identifier, name, image URL, and the percentage of ingredients. There are over 1,500 indexed vectors, with each vector representing the percentage of an ingredient in the total food product (such as sugar, oil, water, etc.).
To initiate the generation of datasets, run the following command:
npm run data-miningMigration will export products datasets (products.json) to local Chroma database.
To launch the migration, run:
npm run migrationTo perform a query to the vector database, you need to generate vectors from product data.
First, we call the Open Food Facts product API. Then, we generate vectors for embedding (likeliest_recipes.json) and use them to make a request to the database.
By default, when a query is performed on the Chroma database, similar products are determined using the Squared L2 Norm vector norm:
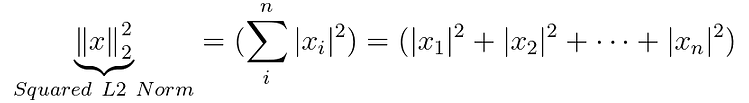
Others vector norms are also available such as the Inner product or Cosine similarity, more details on Chroma and Hnswlib.
npm cidocker run -p 8000:8000 chromadb/chroma:0.4.213017620429484: https://world.openfoodfacts.org/product/3017620429484/nutella-hazelnut-spread-ferrero)
node ./query.js product=3017620429484All datasets have been extracted using the Open Food Facts API. Donate to Open Food Facts project
This project is licensed with GNU AGPL v3 License.
See LICENSE for more details.


