BERTweet
1.0.0
transformersfairseqBertweet adalah model bahasa berskala besar publik pertama yang dilatih sebelumnya untuk tweet bahasa Inggris. Bertweet dilatih berdasarkan prosedur pra-pelatihan Roberta. Korpus yang digunakan untuk pra-pelatihan Bertweet terdiri dari 850M tweet bahasa Inggris (Token Kata 16B ~ 80GB), berisi tweet 845m yang dialirkan dari 01/2012 hingga 08/2019 dan 5m tweet terkait dengan pandemi Covid-19 . Arsitektur umum dan hasil eksperimen Bertweet dapat ditemukan di makalah kami:
@inproceedings{bertweet,
title = {{BERTweet: A pre-trained language model for English Tweets}},
author = {Dat Quoc Nguyen and Thanh Vu and Anh Tuan Nguyen},
booktitle = {Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations},
pages = {9--14},
year = {2020}
}
Harap kutip makalah kami ketika Bertweet digunakan untuk membantu menghasilkan hasil yang dipublikasikan atau dimasukkan ke dalam perangkat lunak lain.
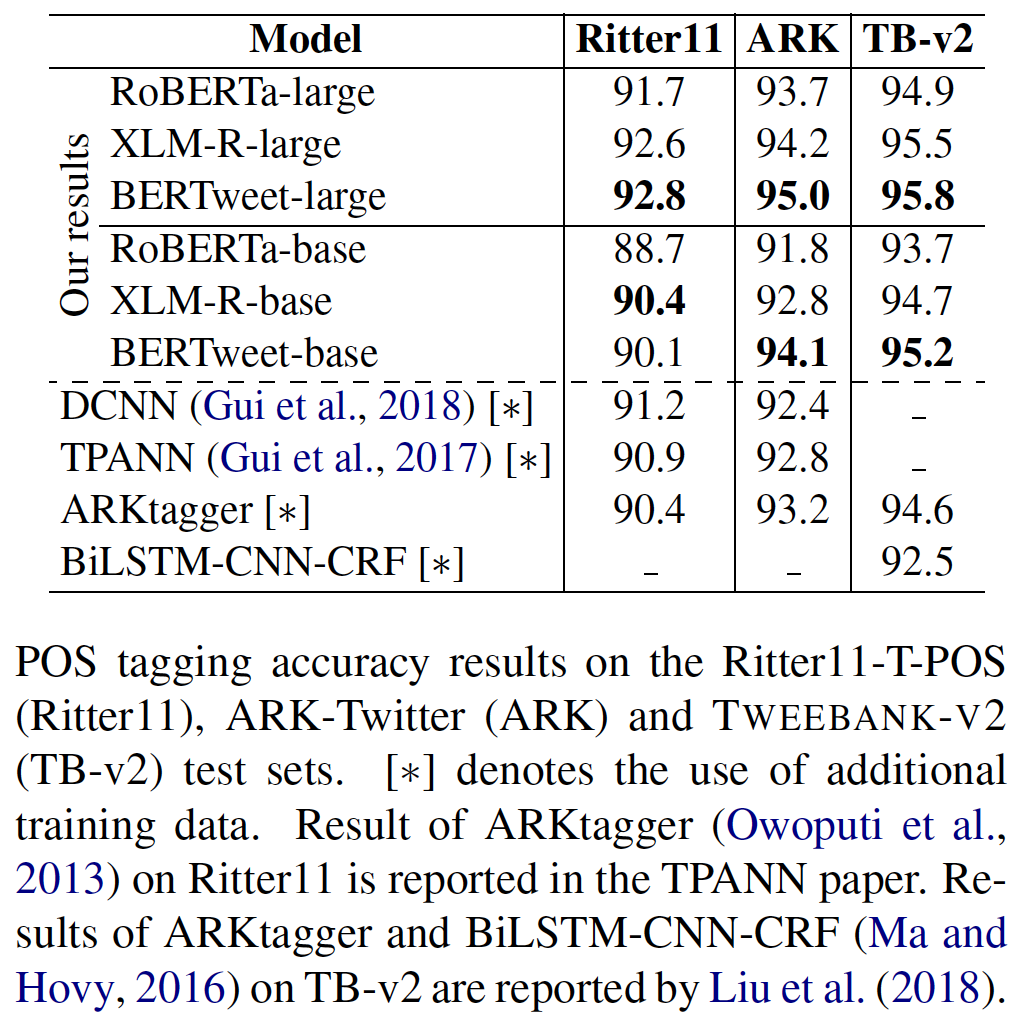
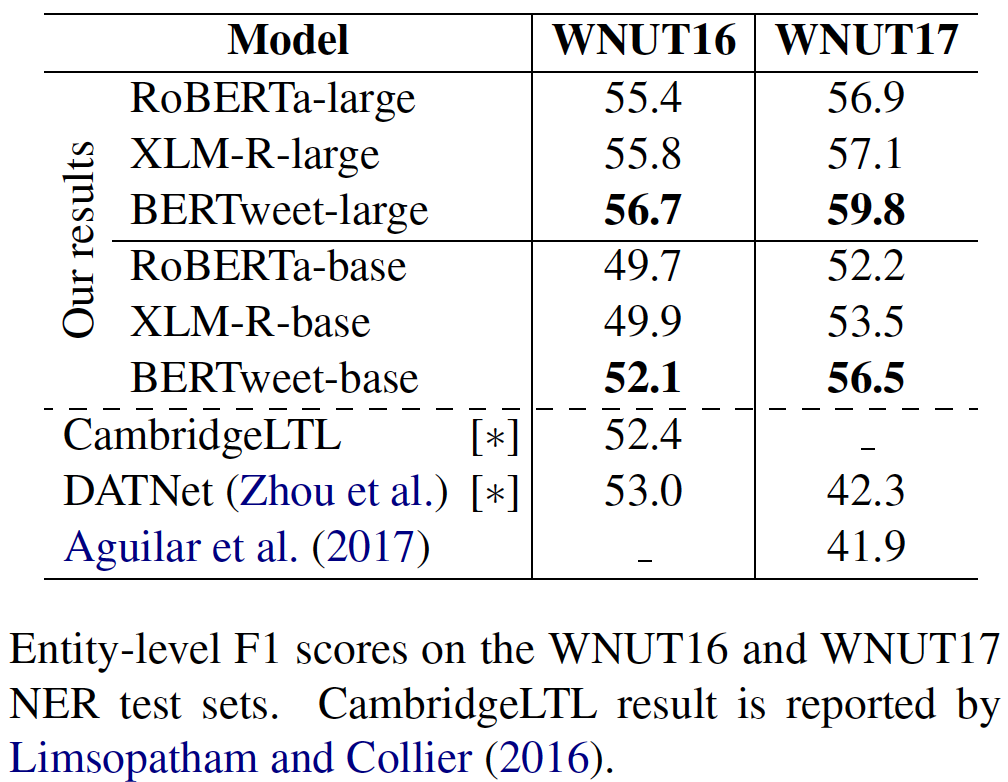
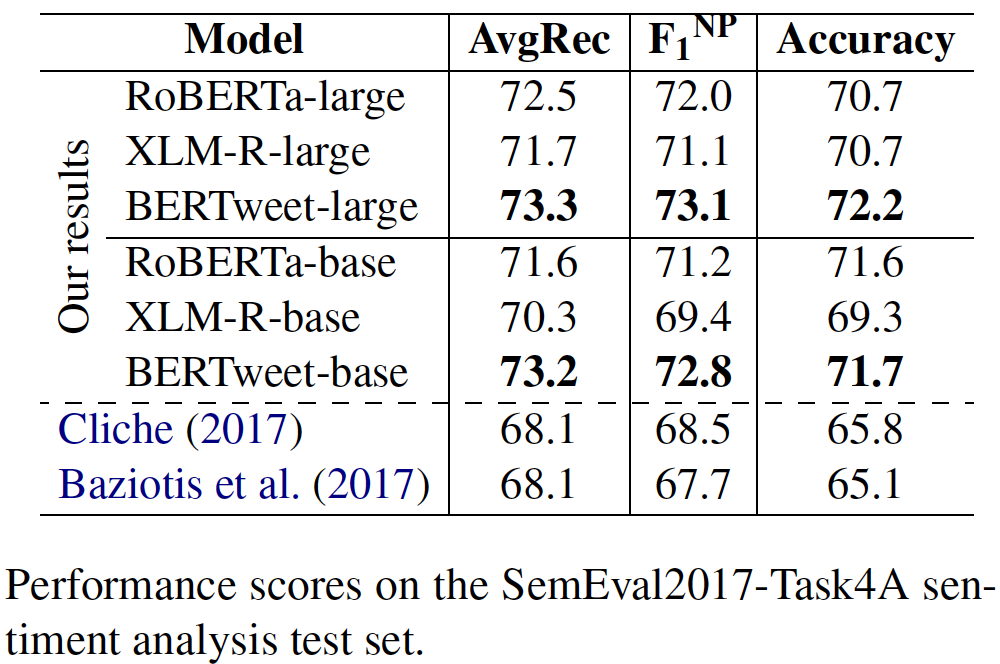
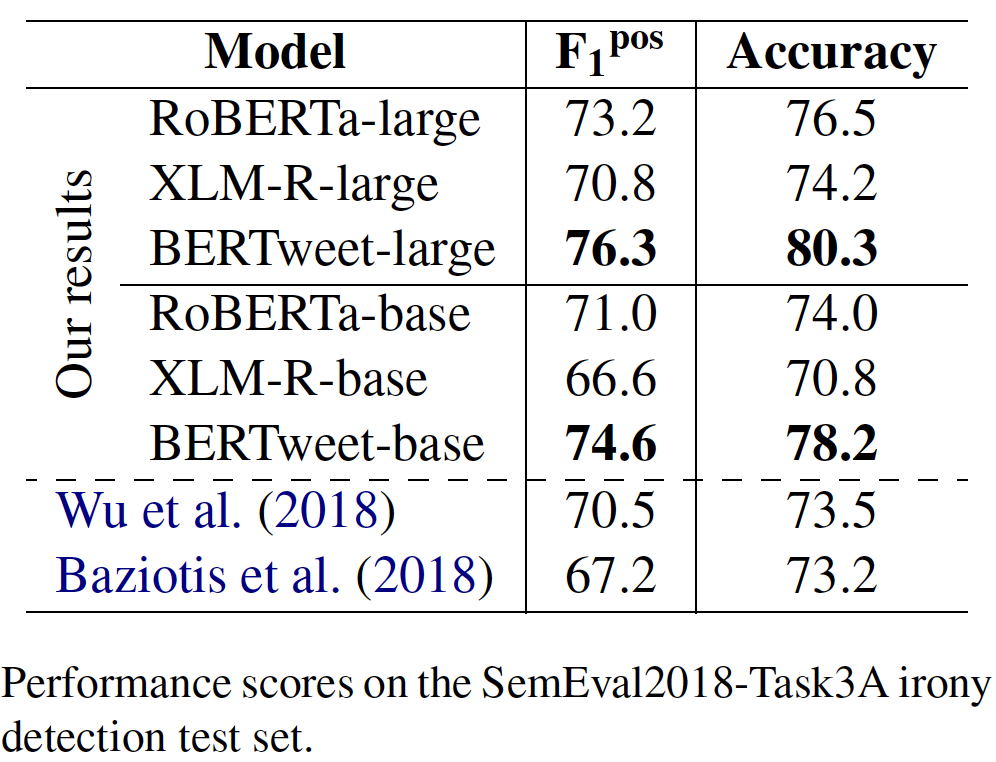
transformerstransformers dengan Pip: pip install transformers , atau Instal transformers Dari Sumber.transformers utama. Proses penggabungan tokenizer cepat untuk Bertweet sedang dalam diskusi, seperti yang disebutkan dalam permintaan tarik ini. Jika pengguna ingin menggunakan tokenizer cepat, pengguna dapat menginstal transformers sebagai berikut: git clone --single-branch --branch fast_tokenizers_BARTpho_PhoBERT_BERTweet https://github.com/datquocnguyen/transformers.git
cd transformers
pip3 install -e .
tokenizers dengan PIP: pip3 install tokenizers| Model | #params | Lengkungan. | Panjang maksimal | Data pra-pelatihan |
|---|---|---|---|---|
vinai/bertweet-base | 135m | basis | 128 | 850m Tweet Bahasa Inggris (Cased) |
vinai/bertweet-covid19-base-cased | 135m | basis | 128 | 23M COVID-19 Tweet Bahasa Inggris (Cased) |
vinai/bertweet-covid19-base-uncased | 135m | basis | 128 | 23M COVID-19 Tweet Bahasa Inggris (Uncased) |
vinai/bertweet-large | 355m | besar | 512 | 873M Tweet Bahasa Inggris (Cased) |
vinai/bertweet-covid19-base-cased dan vinai/bertweet-covid19-base-uncased dihasilkan oleh pra-pelatihan lebih lanjut model pra-terlatih vinai/bertweet-base pada corpus 23M COVID-19 tweet Inggris.vinai/bertweet-large . import torch
from transformers import AutoModel , AutoTokenizer
bertweet = AutoModel . from_pretrained ( "vinai/bertweet-large" )
tokenizer = AutoTokenizer . from_pretrained ( "vinai/bertweet-large" )
# INPUT TWEET IS ALREADY NORMALIZED!
line = "DHEC confirms HTTPURL via @USER :crying_face:"
input_ids = torch . tensor ([ tokenizer . encode ( line )])
with torch . no_grad ():
features = bertweet ( input_ids ) # Models outputs are now tuples
## With TensorFlow 2.0+:
# from transformers import TFAutoModel
# bertweet = TFAutoModel.from_pretrained("vinai/bertweet-large") Sebelum menerapkan BPE ke corpus pra-pelatihan tweet bahasa Inggris, kami tokenized tweet ini menggunakan TweetTokenizer dari toolkit NLTK dan menggunakan paket emoji untuk menerjemahkan ikon emosi ke dalam string teks (di sini, setiap ikon disebut sebagai token kata). Kami juga menormalkan tweet dengan mengonversi sebutan pengguna dan tautan Web/URL ke token khusus @USER dan HTTPURL , masing -masing. Dengan demikian disarankan untuk juga menerapkan langkah pra-pemrosesan yang sama untuk aplikasi hilir berbasis Bertweet Wrt tweet input mentah.
Mengingat tweet input mentah, untuk mendapatkan output pra-pemrosesan yang sama, pengguna dapat menggunakan modul tweetNormalizer kami.
pip3 install nltk emoji==0.6.0emoji harus 0,5.4 atau 0.6.0. Versi emoji yang lebih baru telah diperbarui ke versi yang lebih baru dari grafik emoji, sehingga tidak konsisten dengan yang digunakan untuk pra-pemrosesan corpus tweet pra-pelatihan kami. import torch
from transformers import AutoTokenizer
from TweetNormalizer import normalizeTweet
tokenizer = AutoTokenizer . from_pretrained ( "vinai/bertweet-large" )
line = normalizeTweet ( "DHEC confirms https://postandcourier.com/health/covid19/sc-has-first-two-presumptive-cases-of-coronavirus-dhec-confirms/article_bddfe4ae-5fd3-11ea-9ce4-5f495366cee6.html?utm_medium=social&utm_source=twitter&utm_campaign=user-share… via @postandcourier ?" )
input_ids = torch . tensor ([ tokenizer . encode ( line )])fairseqSilakan lihat detailnya di sini!
MIT License
Copyright (c) 2020-2021 VinAI
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.


