BERTweet
1.0.0
transformersfairseqBertweet est le premier modèle public à grande échelle pré-formé pour les tweets anglais. Bertweet est formé en fonction de la procédure de pré-formation Roberta. Le corpus utilisé pour pré-trajet Bertweet se compose de 850 m de tweets en anglais (jetons de mot 16b ~ 80 Go), contenant 845 m de tweets diffusés du 01/2012 au 08/2019 et 5m Tweets liés à la pandémie Covid-19 . L'architecture générale et les résultats expérimentaux de Bertweet se trouvent dans notre article:
@inproceedings{bertweet,
title = {{BERTweet: A pre-trained language model for English Tweets}},
author = {Dat Quoc Nguyen and Thanh Vu and Anh Tuan Nguyen},
booktitle = {Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations},
pages = {9--14},
year = {2020}
}
Veuillez citer notre article lorsque Bertweet est utilisé pour aider à produire des résultats publiés ou est incorporé dans d'autres logiciels.
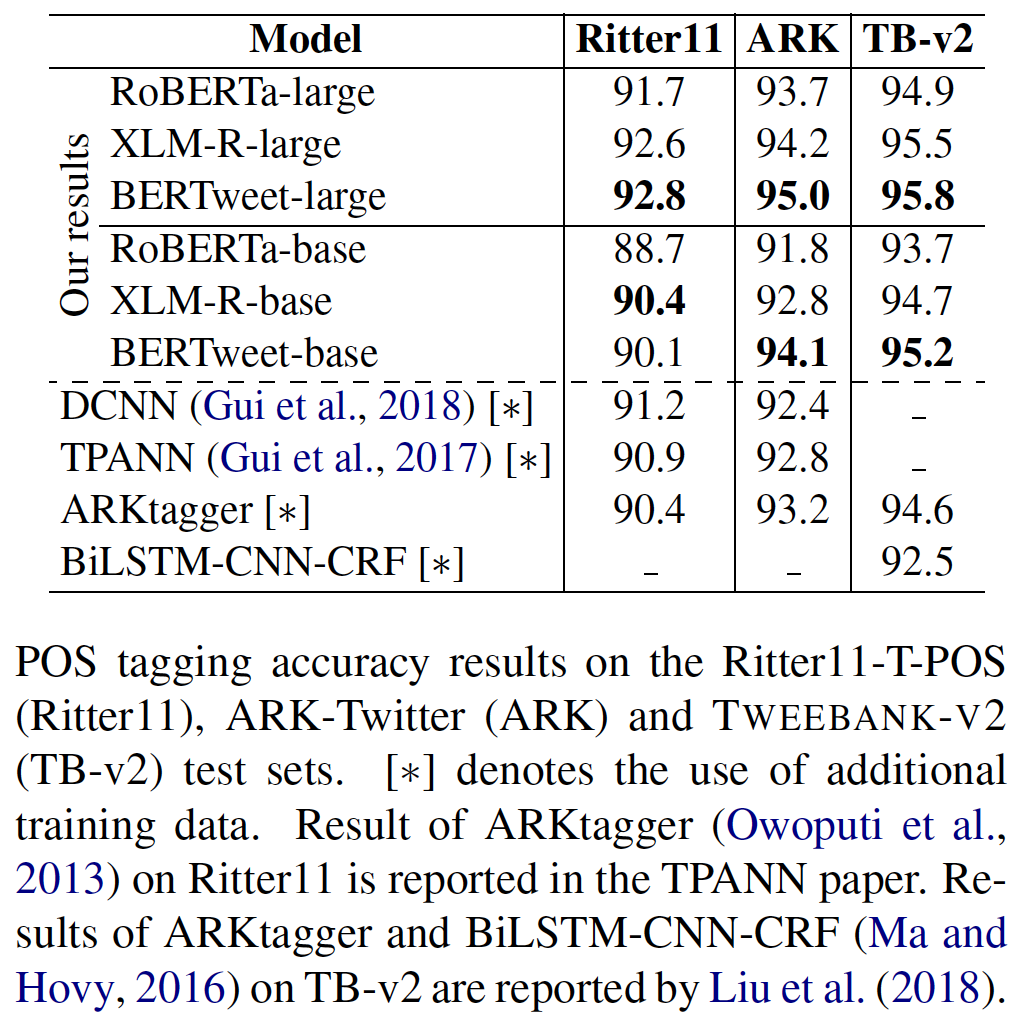
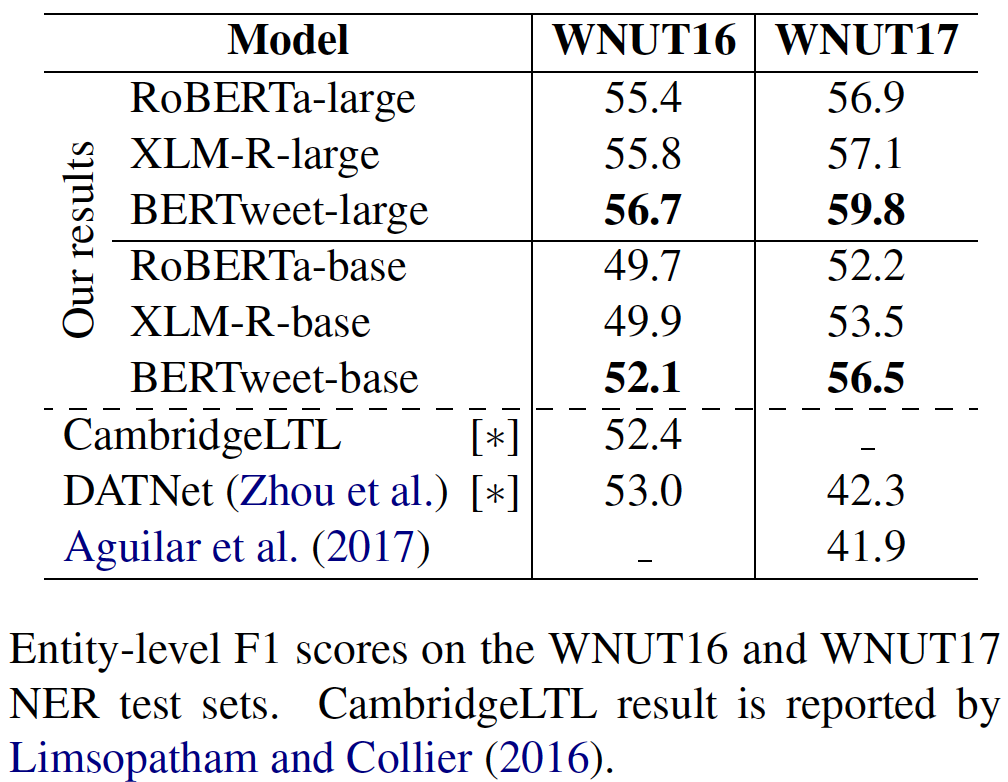
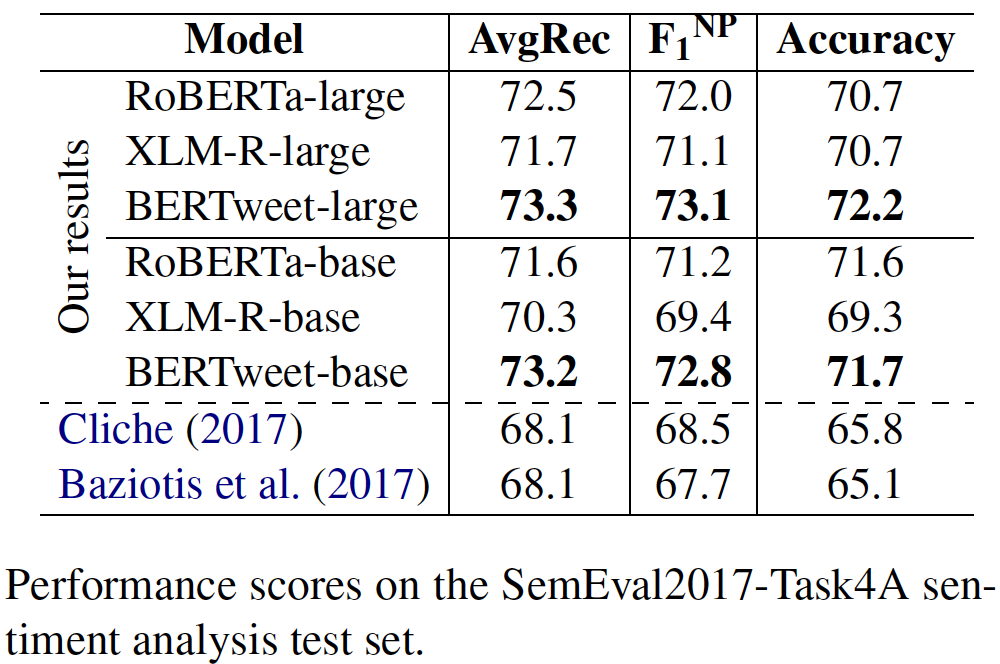
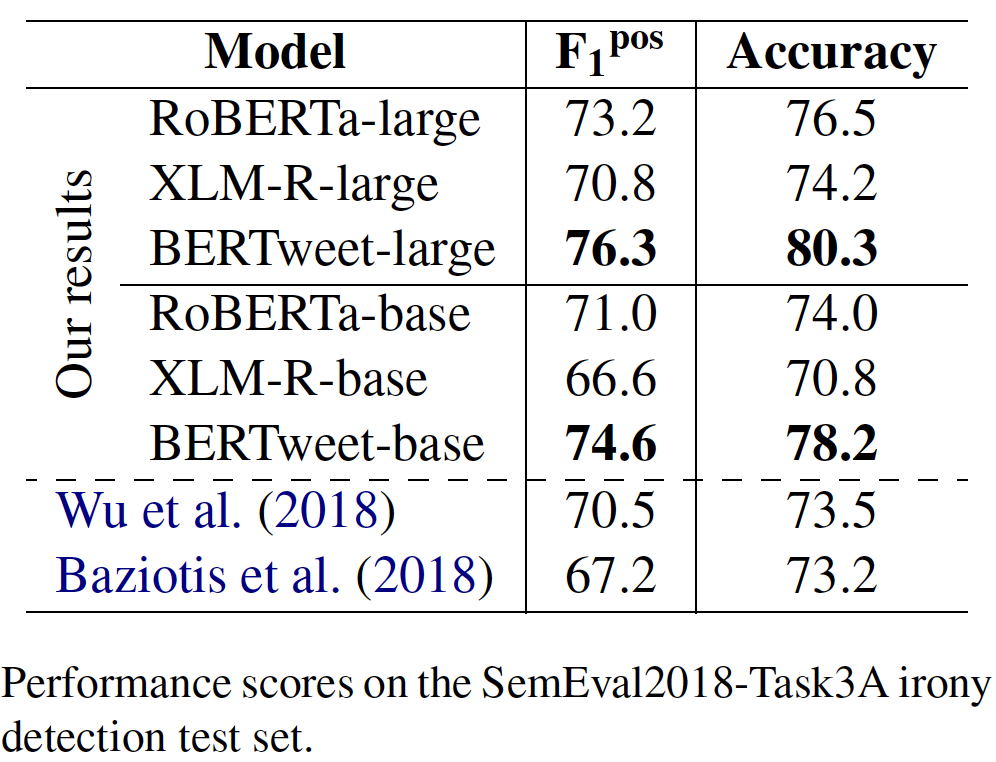
transformerstransformers avec PIP: pip install transformers ou installez transformers à partir de la source.transformers . Le processus de fusion d'un jetons rapide pour Bertweet est dans la discussion, comme mentionné dans cette demande de traction. Si les utilisateurs souhaitent utiliser le jeton rapide, les utilisateurs peuvent installer transformers comme suit: git clone --single-branch --branch fast_tokenizers_BARTpho_PhoBERT_BERTweet https://github.com/datquocnguyen/transformers.git
cd transformers
pip3 install -e .
tokenizers avec PIP: pip3 install tokenizers| Modèle | #params | Cambre. | Longueur maximale | Données de pré-formation |
|---|---|---|---|---|
vinai/bertweet-base | 135m | base | 128 | 850m Tweets anglais (enveloppés) |
vinai/bertweet-covid19-base-cased | 135m | base | 128 | 23m tweets anglais Covid-19 (enveloppés) |
vinai/bertweet-covid19-base-uncased | 135m | base | 128 | 23m tweets anglais Covid-19 (non cuites) |
vinai/bertweet-large | 355m | grand | 512 | 873m Tweets anglais (enveloppés) |
vinai/bertweet-covid19-base-cased et vinai/bertweet-covid19-base-uncased sont entraînés par la pré-formation préalable du modèle pré-formé vinai/bertweet-base sur un Corpus de 23M COVID-19 Tweets anglais.vinai/bertweet-large . import torch
from transformers import AutoModel , AutoTokenizer
bertweet = AutoModel . from_pretrained ( "vinai/bertweet-large" )
tokenizer = AutoTokenizer . from_pretrained ( "vinai/bertweet-large" )
# INPUT TWEET IS ALREADY NORMALIZED!
line = "DHEC confirms HTTPURL via @USER :crying_face:"
input_ids = torch . tensor ([ tokenizer . encode ( line )])
with torch . no_grad ():
features = bertweet ( input_ids ) # Models outputs are now tuples
## With TensorFlow 2.0+:
# from transformers import TFAutoModel
# bertweet = TFAutoModel.from_pretrained("vinai/bertweet-large") Avant d'appliquer du BPE au corpus pré-formation de tweets anglais, nous avons tokenisé ces tweets à l'aide TweetTokenizer à partir de la boîte à outils NLTK et utilisé le package emoji pour traduire les icônes d'émotion en chaînes de texte (ici, chaque icône est appelée token de mot). Nous avons également normalisé les tweets en convertissant les mentions des utilisateurs et les liens Web / URL en jetons spéciaux @USER et HTTPURL , respectivement. Ainsi, il est recommandé d'appliquer également la même étape de prétraitement pour les applications en aval basées sur Bertweet par les tweets d'entrée bruts.
Compte tenu des tweets d'entrée bruts, pour obtenir la même sortie de prétraitement, les utilisateurs peuvent utiliser notre module TweetNormalizer.
pip3 install nltk emoji==0.6.0emoji doit être de 0,5,4 ou 0,6,0. Les versions emoji plus récentes ont été mises à jour vers les versions plus récentes des graphiques emoji, donc non conformes à celle utilisée pour le prétraitement de notre corpus Tweet avant la formation. import torch
from transformers import AutoTokenizer
from TweetNormalizer import normalizeTweet
tokenizer = AutoTokenizer . from_pretrained ( "vinai/bertweet-large" )
line = normalizeTweet ( "DHEC confirms https://postandcourier.com/health/covid19/sc-has-first-two-presumptive-cases-of-coronavirus-dhec-confirms/article_bddfe4ae-5fd3-11ea-9ce4-5f495366cee6.html?utm_medium=social&utm_source=twitter&utm_campaign=user-share… via @postandcourier ?" )
input_ids = torch . tensor ([ tokenizer . encode ( line )])fairseqVeuillez consulter les détails ici!
MIT License
Copyright (c) 2020-2021 VinAI
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.


