BERTweet
1.0.0
transformersfairseqBertweet ist das erste öffentliche groß angelegte Sprachmodell für englische Tweets. Bertweet wird basierend auf dem Roberta-Vorausbildungsverfahren geschult. Das Corpus, das für Bertweet vor dem Training verwendet wird, besteht aus 850 m englischen Tweets (16B Word-Token ~ 80 GB), die 845 m Tweets enthält, die von 01/2012 bis 08/2019 und 5 m mit der Covid-19- Pandemie bezogen wurden. Die allgemeine Architektur und experimentelle Ergebnisse von Bertweet finden Sie in unserem Artikel:
@inproceedings{bertweet,
title = {{BERTweet: A pre-trained language model for English Tweets}},
author = {Dat Quoc Nguyen and Thanh Vu and Anh Tuan Nguyen},
booktitle = {Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations},
pages = {9--14},
year = {2020}
}
Bitte zitieren Sie unser Papier, wenn Bertweet verwendet wird, um veröffentlichte Ergebnisse zu erzielen, oder in andere Software integriert wird.
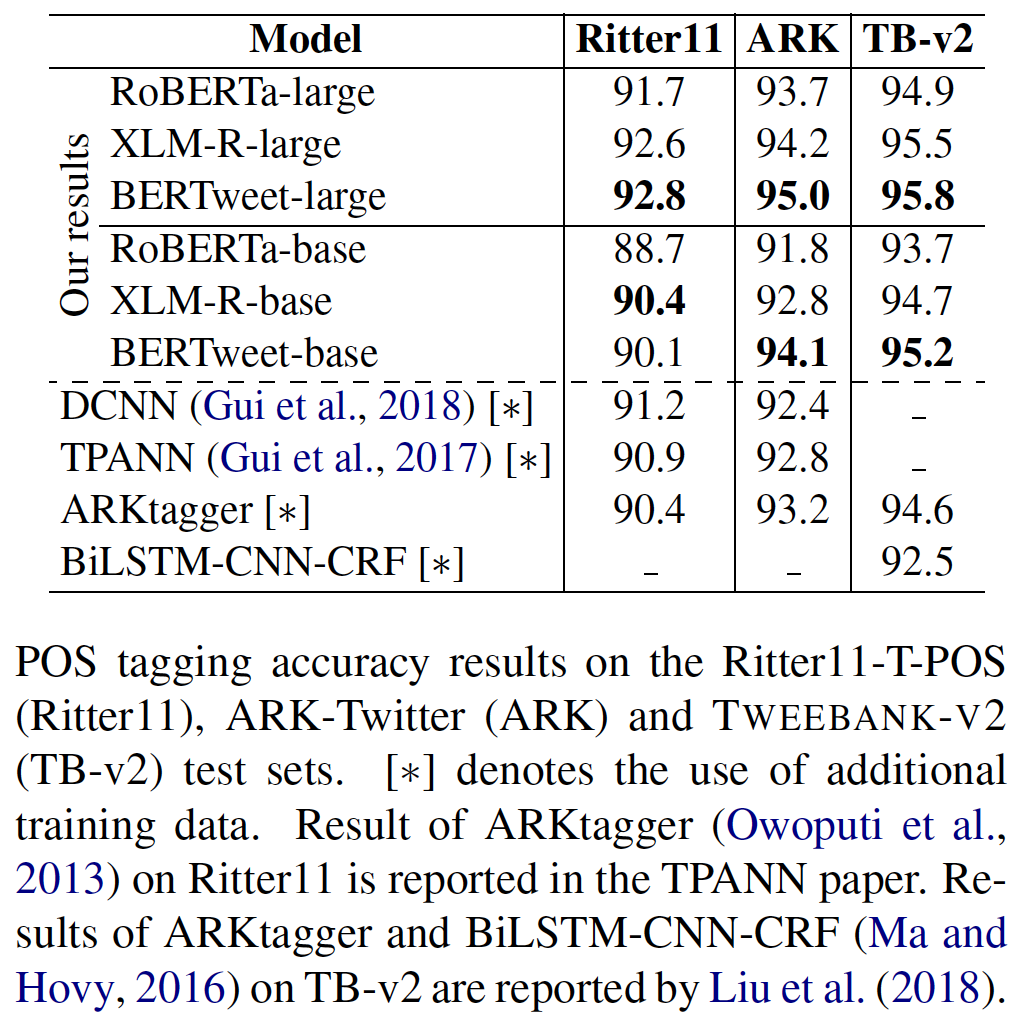
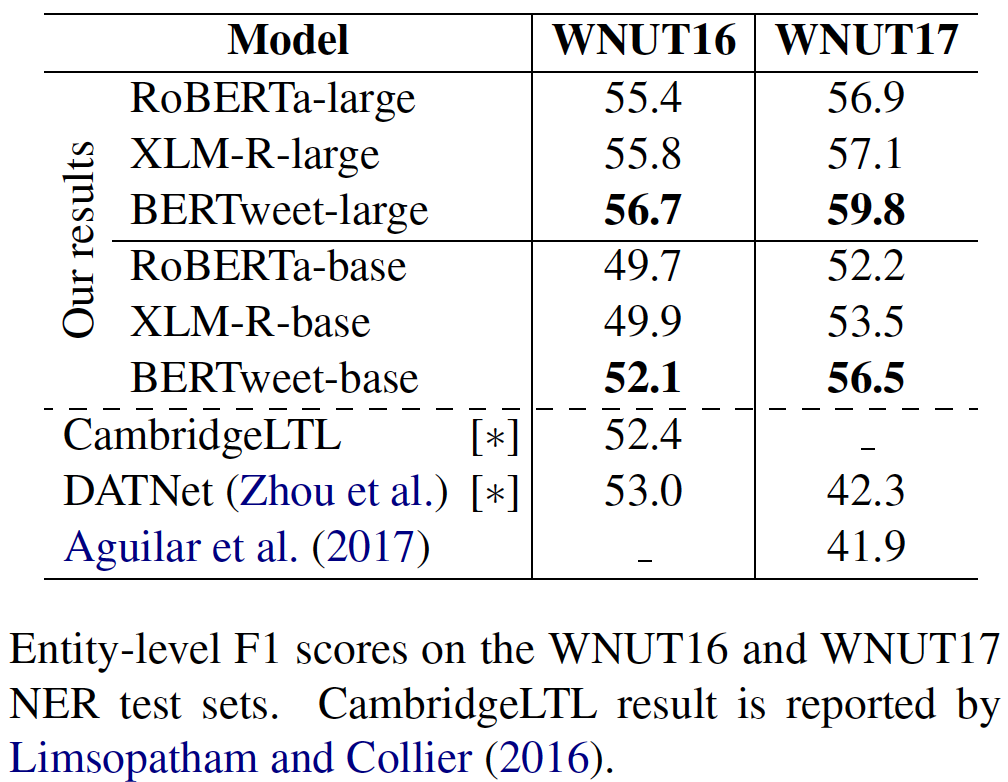
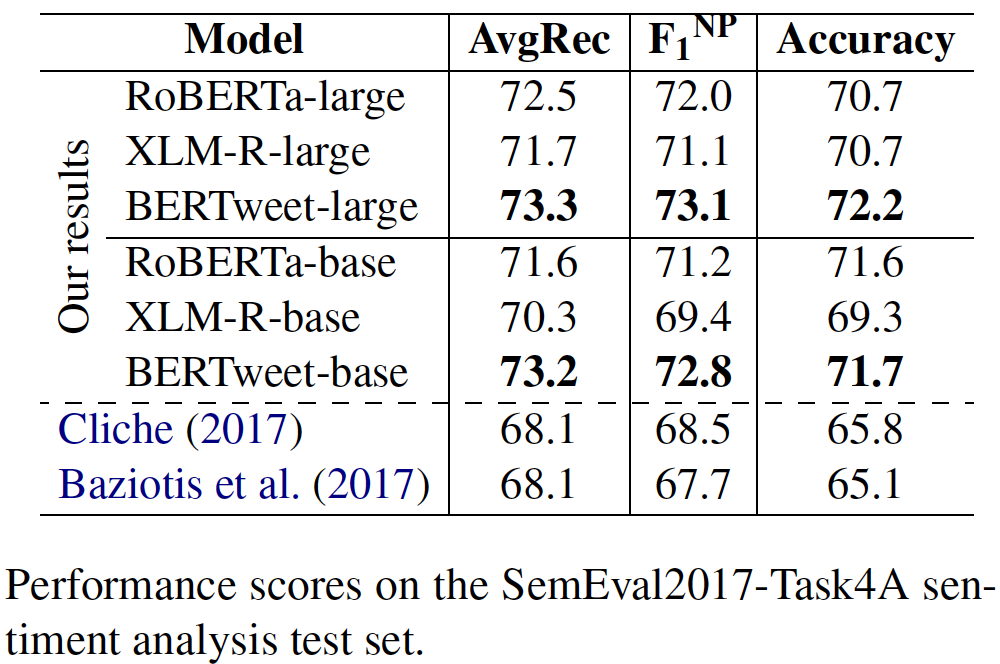
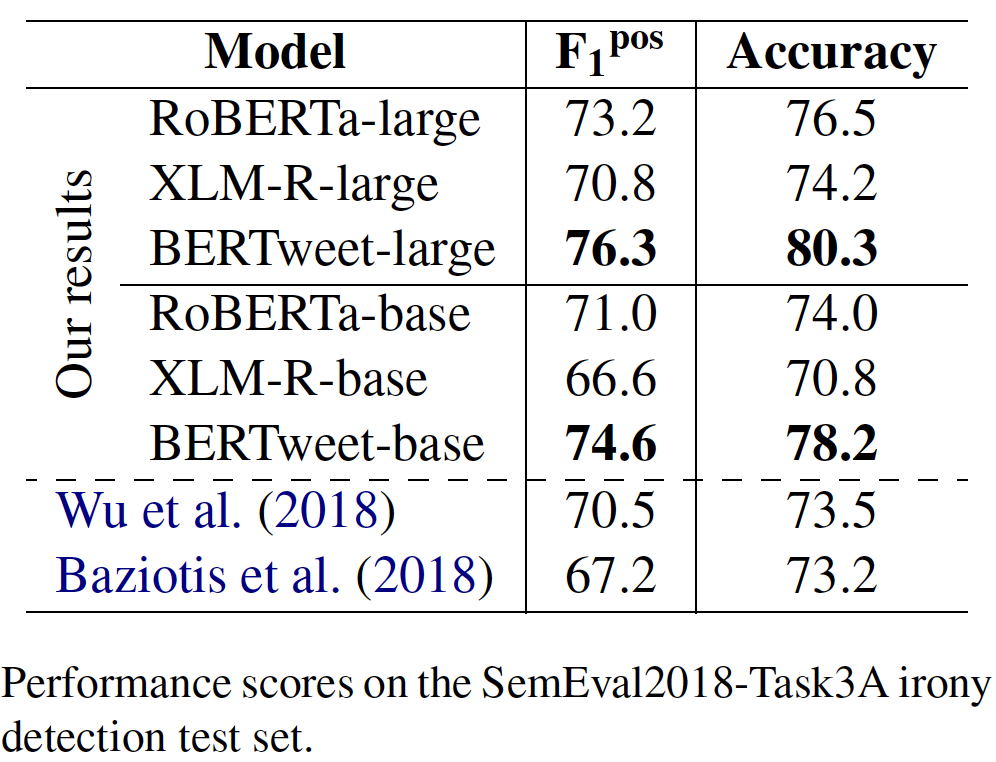
transformerstransformers mit PIP: pip install transformers oder installieren Sie transformers aus der Quelle.transformers -Zweig zusammengefasst haben. Der Prozess der Verschmelzung eines schnellen Tokenzers für Bertweet ist in der Diskussion, wie in dieser Pull -Anfrage erwähnt. Wenn Benutzer den Fast Tokenizer verwenden möchten, können die Benutzer transformers wie folgt installieren: git clone --single-branch --branch fast_tokenizers_BARTpho_PhoBERT_BERTweet https://github.com/datquocnguyen/transformers.git
cd transformers
pip3 install -e .
tokenizers mit PIP: pip3 install tokenizers| Modell | #params | Bogen. | Maximale Länge | Daten vor dem Training |
|---|---|---|---|---|
vinai/bertweet-base | 135 m | Base | 128 | 850 m englische Tweets (Gehäuse) |
vinai/bertweet-covid19-base-cased | 135 m | Base | 128 | 23m Covid-19 English Tweets (Gehäuse) |
vinai/bertweet-covid19-base-uncased | 135 m | Base | 128 | 23m Covid-19 English Tweets (ungezogen) |
vinai/bertweet-large | 355 m | groß | 512 | 873m Englische Tweets (Gehäuse) |
vinai/bertweet-covid19-base-cased und vinai/bertweet-covid19-base-uncased werden ergeben, indem die vorgebrachten Modell- vinai/bertweet-base auf einem Korpus von 23 m COVID-199-Tweets vor dem Training weiter vorgebracht werden.vinai/bertweet-large . import torch
from transformers import AutoModel , AutoTokenizer
bertweet = AutoModel . from_pretrained ( "vinai/bertweet-large" )
tokenizer = AutoTokenizer . from_pretrained ( "vinai/bertweet-large" )
# INPUT TWEET IS ALREADY NORMALIZED!
line = "DHEC confirms HTTPURL via @USER :crying_face:"
input_ids = torch . tensor ([ tokenizer . encode ( line )])
with torch . no_grad ():
features = bertweet ( input_ids ) # Models outputs are now tuples
## With TensorFlow 2.0+:
# from transformers import TFAutoModel
# bertweet = TFAutoModel.from_pretrained("vinai/bertweet-large") Bevor wir BPE auf den Vorbildungskorpus englischer Tweets anwenden, haben wir diese Tweets mit TweetTokenizer aus dem NLTK-Toolkit mithilfe des emoji Pakets mithilfe von Emotionsymbolen in Textzeichenfolgen token (hier wird jedes Symbol als Worttoken bezeichnet). Wir haben die Tweets auch normalisiert, indem wir Benutzererwartungen und Web/URL -Links in spezielle Token @USER bzw. HTTPURL konvertierten. Daher wird empfohlen, auch denselben Vorverarbeitungsschritt für Bertweet-basierte nachgeschaltete Anwendungen anzuwenden.
Angesichts der RAW-Eingabe-Tweets können Benutzer unser TweetNormalizer-Modul verwenden, um dieselbe Vorverarbeitungsausgabe zu erhalten.
pip3 install nltk emoji==0.6.0emoji -Version muss entweder 0.5.4 oder 0,6,0 sein. Neuere emoji Versionen wurden auf neuere Versionen der Emoji-Diagramme aktualisiert, wodurch nicht mit derjenigen übereinstimmt, die zur Vorverarbeitung unseres Tweet-Corpus vor dem Training verwendet wird. import torch
from transformers import AutoTokenizer
from TweetNormalizer import normalizeTweet
tokenizer = AutoTokenizer . from_pretrained ( "vinai/bertweet-large" )
line = normalizeTweet ( "DHEC confirms https://postandcourier.com/health/covid19/sc-has-first-two-presumptive-cases-of-coronavirus-dhec-confirms/article_bddfe4ae-5fd3-11ea-9ce4-5f495366cee6.html?utm_medium=social&utm_source=twitter&utm_campaign=user-share… via @postandcourier ?" )
input_ids = torch . tensor ([ tokenizer . encode ( line )])fairseqWeitere Informationen finden Sie hier!
MIT License
Copyright (c) 2020-2021 VinAI
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.


