reformer pytorch
1.4.4
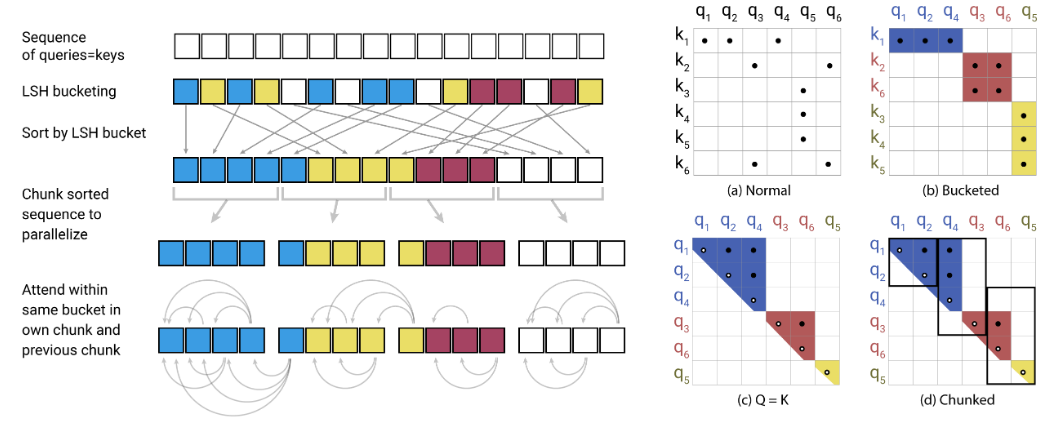
Ini adalah implementasi Pytorch dari reformer https://openreview.net/pdf?id=rkgnkkhtvb
Ini termasuk perhatian LSH, jaringan reversibel, dan chunking. Ini telah divalidasi dengan tugas regresif auto (enwik8).
Token 32K
Token 81k dengan presisi setengah
$ pip install reformer_pytorchModel Bahasa Reformer Sederhana
# should fit in ~ 5gb - 8k tokens
import torch
from reformer_pytorch import ReformerLM
model = ReformerLM (
num_tokens = 20000 ,
dim = 1024 ,
depth = 12 ,
max_seq_len = 8192 ,
heads = 8 ,
lsh_dropout = 0.1 ,
ff_dropout = 0.1 ,
post_attn_dropout = 0.1 ,
layer_dropout = 0.1 , # layer dropout from 'Reducing Transformer Depth on Demand' paper
causal = True , # auto-regressive or not
bucket_size = 64 , # average size of qk per bucket, 64 was recommended in paper
n_hashes = 4 , # 4 is permissible per author, 8 is the best but slower
emb_dim = 128 , # embedding factorization for further memory savings
dim_head = 64 , # be able to fix the dimension of each head, making it independent of the embedding dimension and the number of heads
ff_chunks = 200 , # number of chunks for feedforward layer, make higher if there are memory issues
attn_chunks = 8 , # process lsh attention in chunks, only way for memory to fit when scaling to 16k tokens
num_mem_kv = 128 , # persistent learned memory key values, from all-attention paper
full_attn_thres = 1024 , # use full attention if context length is less than set value
reverse_thres = 1024 , # turn off reversibility for 2x speed for sequence lengths shorter or equal to the designated value
use_scale_norm = False , # use scale norm from 'Transformers without tears' paper
use_rezero = False , # remove normalization and use rezero from 'ReZero is All You Need'
one_value_head = False , # use one set of values for all heads from 'One Write-Head Is All You Need'
weight_tie = False , # tie parameters of each layer for no memory per additional depth
weight_tie_embedding = False , # use token embedding for projection of output, some papers report better results
n_local_attn_heads = 2 , # many papers suggest mixing local attention heads aids specialization and improves on certain tasks
pkm_layers = ( 4 , 7 ), # specify layers to use product key memory. paper shows 1 or 2 modules near the middle of the transformer is best
pkm_num_keys = 128 , # defaults to 128, but can be increased to 256 or 512 as memory allows
use_full_attn = False # only turn on this flag to override and turn on full attention for all sequence lengths. for comparison with LSH to show that it is working
). cuda ()
x = torch . randint ( 0 , 20000 , ( 1 , 8192 )). long (). cuda ()
y = model ( x ) # (1, 8192, 20000)The Reformer (hanya setumpuk perhatian LSH yang dapat dibalik)
# should fit in ~ 5gb - 8k embeddings
import torch
from reformer_pytorch import Reformer
model = Reformer (
dim = 512 ,
depth = 12 ,
heads = 8 ,
lsh_dropout = 0.1 ,
causal = True
). cuda ()
x = torch . randn ( 1 , 8192 , 512 ). cuda ()
y = model ( x ) # (1, 8192, 512)Perhatian dengan LSH
import torch
from reformer_pytorch import LSHSelfAttention
attn = LSHSelfAttention (
dim = 128 ,
heads = 8 ,
bucket_size = 64 ,
n_hashes = 8 ,
causal = False
)
x = torch . randn ( 10 , 1024 , 128 )
y = attn ( x ) # (10, 1024, 128)LSH (Locality Sensitive Hashing) Perhatian
import torch
from reformer_pytorch import LSHAttention
attn = LSHAttention (
bucket_size = 64 ,
n_hashes = 16 ,
causal = True
)
qk = torch . randn ( 10 , 1024 , 128 )
v = torch . randn ( 10 , 1024 , 128 )
out , attn , buckets = attn ( qk , v ) # (10, 1024, 128)
# attn contains the unsorted attention weights, provided return_attn is set to True (costly otherwise)
# buckets will contain the bucket number (post-argmax) of each token of each batch Repositori ini mendukung masker pada urutan input input_mask (bx i_seq) , urutan konteks context_mask (bx c_seq) , serta matriks perhatian penuh yang jarang digunakan sendiri input_attn_mask (bx i_seq x i_seq) , semuanya dibuat kompatibel dengan perhatian LSH. Topeng terbuat dari boolean di mana False menunjukkan menutupi sebelum softmax.
Topeng segitiga kausal semuanya dirawat untuk Anda jika Anda mengatur causal = True .
import torch
from reformer_pytorch import ReformerLM
CONTEXT_LEN = 512
SEQ_LEN = 8192
model = ReformerLM (
num_tokens = 20000 ,
dim = 1024 ,
depth = 1 ,
max_seq_len = SEQ_LEN ,
ff_chunks = 8 ,
causal = True
)
c = torch . randn ( 1 , CONTEXT_LEN , 1024 )
x = torch . randint ( 0 , 20000 , ( 1 , SEQ_LEN )). long ()
i_mask = torch . ones ( 1 , SEQ_LEN ). bool ()
c_mask = torch . ones ( 1 , CONTEXT_LEN ). bool ()
y = model ( x , keys = c , input_mask = i_mask , context_mask = c_mask )
# masking done correctly in LSH attention Embedding posisi default menggunakan embeddings putar.
Namun, Aran telah memberi tahu saya bahwa tim Reformer menggunakan embeddings posisi aksial dengan hasil yang bagus pada urutan yang lebih lama.
Anda dapat menyalakan embedding posisi aksial dan menyesuaikan bentuk dan dimensi embeddings aksial dengan mengikuti instruksi di bawah ini.
import torch
from reformer_pytorch import ReformerLM
model = ReformerLM (
num_tokens = 20000 ,
dim = 1024 ,
depth = 12 ,
max_seq_len = 8192 ,
ff_chunks = 8 ,
attn_chunks = 2 ,
causal = True ,
axial_position_emb = True , # set this to True
axial_position_shape = ( 128 , 64 ), # the shape must multiply up to the max_seq_len (128 x 64 = 8192)
)
x = torch . randint ( 0 , 20000 , ( 1 , 8192 )). long ()
y = model ( x ) # (1, 8192, 20000) Jika Anda lebih suka menggunakan embeddings posisi absolut, Anda dapat menyalakannya dengan absolute_position_emb = True pada inisialisasi.
Sejak versi 0.17.0 , dan beberapa koreksi untuk jaringan yang dapat dibalik, reformer Pytorch kompatibel dengan Deeped Microsoft! Jika Anda memiliki beberapa GPU lokal, Anda dapat mengikuti instruksi / contoh di sini.
Urutan reformer penuh → urutan, katakanlah terjemahan
import torch
from reformer_pytorch import ReformerLM
DE_SEQ_LEN = 4096
EN_SEQ_LEN = 4096
encoder = ReformerLM (
num_tokens = 20000 ,
emb_dim = 128 ,
dim = 1024 ,
depth = 12 ,
heads = 8 ,
max_seq_len = DE_SEQ_LEN ,
fixed_position_emb = True ,
return_embeddings = True # return output of last attention layer
). cuda ()
decoder = ReformerLM (
num_tokens = 20000 ,
emb_dim = 128 ,
dim = 1024 ,
depth = 12 ,
heads = 8 ,
max_seq_len = EN_SEQ_LEN ,
fixed_position_emb = True ,
causal = True
). cuda ()
x = torch . randint ( 0 , 20000 , ( 1 , DE_SEQ_LEN )). long (). cuda ()
yi = torch . randint ( 0 , 20000 , ( 1 , EN_SEQ_LEN )). long (). cuda ()
enc_keys = encoder ( x ) # (1, 4096, 1024)
yo = decoder ( yi , keys = enc_keys ) # (1, 4096, 20000)Gambar Reformator Penuh → Keterangan
import torch
from torch . nn import Sequential
from torchvision import models
from reformer_pytorch import Reformer , ReformerLM
resnet = models . resnet50 ( pretrained = True )
resnet = Sequential ( * list ( resnet . children ())[: - 4 ])
SEQ_LEN = 4096
encoder = Reformer (
dim = 512 ,
depth = 6 ,
heads = 8 ,
max_seq_len = 4096
)
decoder = ReformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
heads = 8 ,
max_seq_len = SEQ_LEN ,
causal = True
)
x = torch . randn ( 1 , 3 , 512 , 512 )
yi = torch . randint ( 0 , 20000 , ( 1 , SEQ_LEN )). long ()
visual_emb = resnet ( x )
b , c , h , w = visual_emb . shape
visual_emb = visual_emb . view ( 1 , c , h * w ). transpose ( 1 , 2 ) # nchw to nte
enc_keys = encoder ( visual_emb )
yo = decoder ( yi , keys = enc_keys ) # (1, 4096, 20000) Ada bug dalam versi < 0.21.0 . Harap upgrade ke setidaknya versi yang ditentukan untuk pembaru enkoder / decoder yang berfungsi.
Dengan permintaan populer, saya telah mengkode pembungkus yang menghilangkan banyak pekerjaan manual dalam menulis arsitektur enkoder / dekoder generik. Untuk digunakan, Anda akan mengimpor kelas ReformerEncDec . Argumen Kata Kunci Encoder akan dilewati dengan awalan enc_ dan argumen kata kunci decoder dengan dec_ . Dimensi model ( dim ) harus bebas awalan dan akan dibagi antara encoder dan decoder. Kerangka kerja ini juga akan mengurus masker input enkoder ke topeng konteks decoder, kecuali secara eksplisit ditimpa.
import torch
from reformer_pytorch import ReformerEncDec
DE_SEQ_LEN = 4096
EN_SEQ_LEN = 4096
enc_dec = ReformerEncDec (
dim = 512 ,
enc_num_tokens = 20000 ,
enc_depth = 6 ,
enc_max_seq_len = DE_SEQ_LEN ,
dec_num_tokens = 20000 ,
dec_depth = 6 ,
dec_max_seq_len = EN_SEQ_LEN
). cuda ()
train_seq_in = torch . randint ( 0 , 20000 , ( 1 , DE_SEQ_LEN )). long (). cuda ()
train_seq_out = torch . randint ( 0 , 20000 , ( 1 , EN_SEQ_LEN )). long (). cuda ()
input_mask = torch . ones ( 1 , DE_SEQ_LEN ). bool (). cuda ()
loss = enc_dec ( train_seq_in , train_seq_out , return_loss = True , enc_input_mask = input_mask )
loss . backward ()
# learn
# evaluate with the following
eval_seq_in = torch . randint ( 0 , 20000 , ( 1 , DE_SEQ_LEN )). long (). cuda ()
eval_seq_out_start = torch . tensor ([[ 0. ]]). long (). cuda () # assume 0 is id of start token
samples = enc_dec . generate ( eval_seq_in , eval_seq_out_start , seq_len = EN_SEQ_LEN , eos_token = 1 ) # assume 1 is id of stop token
print ( samples . shape ) # (1, <= 1024) decode the tokens Untuk melihat manfaat menggunakan PKM, tingkat pembelajaran nilai harus ditetapkan lebih tinggi dari parameter lainnya. (Direkomendasikan untuk menjadi 1e-2 )
Anda dapat mengikuti instruksi di sini untuk mengaturnya dengan benar https://github.com/lucidrains/product-key-memory#learning-rates
Secara default, fungsi aktivasi adalah GELU . Jika Anda ingin fungsi aktivasi alternatif, Anda dapat lulus di kelas ke kata kunci ff_activation .
import torch
from reformer_pytorch import ReformerLM
from torch import nn
model = ReformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
max_seq_len = 8192 ,
ff_chunks = 8 ,
ff_dropout = 0.1 ,
ff_mult = 6 ,
ff_activation = nn . LeakyReLU ,
ff_glu = True # use GLU in feedforward, from paper 'GLU Variants Improve Transformer'
)
x = torch . randint ( 0 , 20000 , ( 1 , 8192 )). long ()
y = model ( x ) # (1, 8192, 20000) Untuk mengakses bobot perhatian dan distribusi bucket, cukup bungkus model instantiated dengan kelas pembungkus Recorder .
import torch
from reformer_pytorch import Reformer , Recorder
model = Reformer (
dim = 512 ,
depth = 12 ,
max_seq_len = 8192 ,
heads = 8 ,
lsh_dropout = 0.1 ,
causal = True
). cuda ()
model = Recorder ( model )
x = torch . randn ( 1 , 8192 , 512 ). cuda ()
y = model ( x )
model . recordings [ 0 ] # a list of attention weights and buckets for the first forward pass
model . turn_off () # stop recording
model . turn_on () # start recording
model . clear () # clear the recordings
model = model . eject () # recover the original model and remove all listeners Reformer dilengkapi dengan sedikit kelemahan bahwa urutannya harus dibagi dengan rapi dengan ukuran ember * 2. Saya telah menyediakan alat penolong kecil yang dapat membantu Anda secara otomatis. Panjang urutan ke kelipatan terbaik berikutnya.
import torch
from reformer_pytorch import ReformerLM , Autopadder
model = ReformerLM (
num_tokens = 20000 ,
dim = 1024 ,
depth = 12 ,
max_seq_len = 8192 ,
heads = 8 ,
lsh_dropout = 0.1 ,
causal = True ,
bucket_size = 63 , # odd bucket size
num_mem_kv = 77 # odd memory key length
). cuda ()
model = Autopadder ( model )
SEQ_LEN = 7777 # odd sequence length
keys = torch . randn ( 1 , 137 , 1024 ) # odd keys length
x = torch . randint ( 0 , 20000 , ( 1 , SEQ_LEN )). long (). cuda ()
y = model ( x , keys = keys ) # (1, 7777, 20000) Banyak pengguna hanya tertarik pada model bahasa regregresif otomatis (seperti GPT-2). Berikut adalah pembungkus pelatihan untuk memudahkan melatih dan mengevaluasi urutan panjang yang dipanjang dari token yang dikodekan. Anda harus mengurus pengkodean dan decoding sendiri.
import torch
from torch import randint
from reformer_pytorch import ReformerLM
from reformer_pytorch . generative_tools import TrainingWrapper
model = ReformerLM (
num_tokens = 20000 ,
dim = 1024 ,
depth = 12 ,
max_seq_len = 4096 ,
lsh_dropout = 0.1 ,
causal = True ,
full_attn_thres = 1024
)
# 0 is used for padding and no loss to be calculated on it
model = TrainingWrapper ( model , ignore_index = 0 , pad_value = 0 )
# the wrapper can handle evenly packed sequences
x_train = randint ( 0 , 20000 , ( 3 , 357 ))
# or if you have a list of uneven sequences, it will be padded for you
x_train = [
randint ( 0 , 20000 , ( 120 ,)),
randint ( 0 , 20000 , ( 253 ,)),
randint ( 0 , 20000 , ( 846 ,))
]
# when training, set return_loss equal to True
model . train ()
loss = model ( x_train , return_loss = True )
loss . backward ()
# when evaluating, just use the generate function, which will default to top_k sampling with temperature of 1.
initial = torch . tensor ([[ 0 ]]). long () # assume 0 is start token
sample = model . generate ( initial , 100 , temperature = 1. , filter_thres = 0.9 , eos_token = 1 ) # assume end token is 1, or omit and it will sample up to 100
print ( sample . shape ) # (1, <=100) token ids Andrea telah menemukan bahwa menggunakan tingkat optimisasi O2 ketika pelatihan dengan presisi campuran dapat menyebabkan ketidakstabilan. Harap gunakan O1 sebagai gantinya, yang dapat diatur dengan amp_level di Pytorch Lightning, atau opt_level di Perpustakaan Apex NVIDIA.
@inproceedings { kitaev2020reformer ,
title = { Reformer: The Efficient Transformer } ,
author = { Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=rkgNKkHtvB }
} @article { DBLP:journals/corr/abs-1907-01470 ,
author = { Sainbayar Sukhbaatar and
Edouard Grave and
Guillaume Lample and
Herv{'{e}} J{'{e}}gou and
Armand Joulin } ,
title = { Augmenting Self-attention with Persistent Memory } ,
journal = { CoRR } ,
volume = { abs/1907.01470 } ,
year = { 2019 } ,
url = { http://arxiv.org/abs/1907.01470 }
} @article { 1910.05895 ,
author = { Toan Q. Nguyen and Julian Salazar } ,
title = { Transformers without Tears: Improving the Normalization of Self-Attention } ,
year = { 2019 } ,
eprint = { arXiv:1910.05895 } ,
doi = { 10.5281/zenodo.3525484 } ,
} @inproceedings { fan2020reducing ,
title = { Reducing Transformer Depth on Demand with Structured Dropout } ,
author = { Angela Fan and Edouard Grave and Armand Joulin } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=SylO2yStDr }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=B1gjs6EtDr }
} @misc { bachlechner2020rezero ,
title = { ReZero is All You Need: Fast Convergence at Large Depth } ,
author = { Thomas Bachlechner and Bodhisattwa Prasad Majumder and Huanru Henry Mao and Garrison W. Cottrell and Julian McAuley } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2003.04887 }
} @misc { lample2019large ,
title = { Large Memory Layers with Product Keys } ,
author = { Guillaume Lample and Alexandre Sablayrolles and Marc'Aurelio Ranzato and Ludovic Denoyer and Hervé Jégou } ,
year = { 2019 } ,
eprint = { 1907.05242 } ,
archivePrefix = { arXiv }
} @misc { bhojanapalli2020lowrank ,
title = { Low-Rank Bottleneck in Multi-head Attention Models } ,
author = { Srinadh Bhojanapalli and Chulhee Yun and Ankit Singh Rawat and Sashank J. Reddi and Sanjiv Kumar } ,
year = { 2020 } ,
eprint = { 2002.07028 }
} @misc { dong2021attention ,
title = { Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth } ,
author = { Yihe Dong and Jean-Baptiste Cordonnier and Andreas Loukas } ,
year = { 2021 } ,
eprint = { 2103.03404 }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @misc { vaswani2017attention ,
title = { Attention Is All You Need } ,
author = { Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin } ,
year = { 2017 } ,
eprint = { 1706.03762 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
}♥


