WebSearchEngine
1.0.0
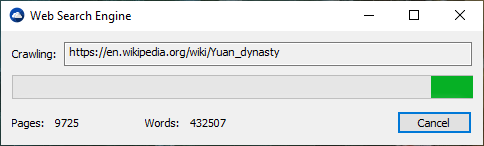
Mesin pencari adalah sistem perangkat lunak yang dirancang untuk melakukan pencarian web. Mereka mencari World Wide Web dengan cara sistematis untuk informasi tertentu yang ditentukan dalam kueri pencarian web tekstual. Hasil pencarian umumnya disajikan dalam garis hasil, sering disebut sebagai halaman hasil mesin pencari (SERP) Informasi ini mungkin merupakan campuran tautan ke halaman web, gambar, video, infografis, artikel, makalah penelitian, dan jenis file lainnya. Beberapa mesin pencari juga menambang data yang tersedia di database atau direktori terbuka. Tidak seperti direktori web, yang hanya dikelola oleh editor manusia, mesin pencari juga mempertahankan informasi waktu nyata dengan menjalankan algoritma pada perayap web. Konten Internet yang tidak mampu dicari oleh mesin pencari web umumnya digambarkan sebagai web yang dalam.
Mesin pencari mempertahankan proses berikut dalam waktu dekat:
Mesin pencari web mendapatkan informasi mereka dengan merangkak web dari situs ke situs. "Laba -laba" memeriksa robot file robots.txt standar, ditujukan padanya. File Robots.txt berisi arahan untuk laba -laba pencarian, memberi tahu halaman mana yang akan dirayapi dan halaman mana yang tidak dirayapi. Setelah memeriksa robot.txt dan menemukannya atau tidak, laba -laba mengirimkan informasi tertentu kembali untuk diindeks tergantung pada banyak faktor, seperti judul, konten halaman, javascript, lembaran gaya cascading (CSS), judul, atau metadata dalam tag meta HTML. Setelah sejumlah halaman merangkak, jumlah data yang diindeks, atau waktu yang dihabiskan di situs web, laba -laba berhenti merangkak dan melanjutkan. "[N] o Web Crawler sebenarnya dapat merangkak seluruh jaring yang dapat dijangkau. Karena situs web yang tak terbatas, perangkap laba -laba, spam, dan urgensi lain dari jaring yang sebenarnya, crawler malah menerapkan kebijakan merangkak untuk menentukan kapan merangkak situs harus dianggap cukup. Beberapa situs web merangkak secara mendalam, sementara yang lain merangkak hanya sebagian".
Pengindeksan berarti mengaitkan kata-kata dan token yang dapat ditentukan lainnya yang ditemukan di halaman web dengan nama domain dan bidang berbasis HTML mereka. Asosiasi dibuat dalam database publik, tersedia untuk pertanyaan pencarian web. Kueri dari pengguna dapat berupa satu kata, banyak kata atau kalimat. Indeks membantu menemukan informasi yang berkaitan dengan kueri secepat mungkin. Beberapa teknik untuk pengindeksan, dan caching adalah rahasia dagang, sedangkan perayapan web adalah proses langsung mengunjungi semua situs secara sistematis.
Antara kunjungan oleh laba -laba, versi yang di -cache dari halaman (beberapa atau semua konten yang diperlukan untuk membuatnya) yang disimpan dalam memori kerja mesin pencari dengan cepat dikirim ke penanya. Jika kunjungan terlambat, mesin pencari hanya dapat bertindak sebagai proxy web. Dalam hal ini, halaman mungkin berbeda dari istilah pencarian yang diindeks. Halaman yang di -cache memegang tampilan versi yang kata -katanya sebelumnya diindeks, sehingga versi halaman yang di -cache dapat berguna bagi situs web ketika halaman yang sebenarnya telah hilang, tetapi masalah ini juga dianggap sebagai bentuk ringan dari LinkRot.
Biasanya ketika pengguna memasukkan kueri ke dalam mesin pencari itu adalah beberapa kata kunci. Indeks sudah memiliki nama situs yang berisi kata kunci, dan ini langsung diperoleh dari indeks. Beban pemrosesan nyata adalah dalam menghasilkan halaman web yang merupakan daftar hasil pencarian: Setiap halaman di seluruh daftar harus ditimbang sesuai dengan informasi dalam indeks. Kemudian item hasil pencarian atas membutuhkan pencarian, rekonstruksi, dan markup cuplikan yang menunjukkan konteks kata kunci yang cocok. Ini hanya bagian dari pemrosesan yang diperlukan setiap halaman Web Hasil Pencarian, dan halaman lebih lanjut (di sebelah atas) membutuhkan lebih banyak pasca-pemrosesan ini.
Di luar pencarian kata kunci sederhana, mesin pencari menawarkan operator mereka sendiri atau yang digerakkan oleh perintah dan parameter pencarian untuk memperbaiki hasil pencarian. Ini memberikan kontrol yang diperlukan untuk pengguna yang terlibat dalam loop umpan balik yang dibuat pengguna dengan memfilter dan bobot saat memperbaiki hasil pencarian, mengingat halaman awal dari hasil pencarian pertama. Misalnya, dari tahun 2007 mesin pencari Google.com telah memungkinkan seseorang untuk memfilter berdasarkan tanggal dengan mengklik "Tampilkan Alat Pencarian" di kolom paling kiri dari halaman Hasil Pencarian Awal, dan kemudian memilih rentang tanggal yang diinginkan. Ini juga dimungkinkan untuk berat berdasarkan tanggal karena setiap halaman memiliki waktu modifikasi. Sebagian besar mesin pencari mendukung penggunaan operator Boolean dan, atau dan tidak membantu pengguna akhir memperbaiki kueri pencarian. Operator Boolean untuk pencarian literal yang memungkinkan pengguna untuk memperbaiki dan memperluas ketentuan pencarian. Mesin mencari kata atau frasa persis seperti yang dimasukkan. Beberapa mesin pencari menyediakan fitur canggih yang disebut Proximity Search, yang memungkinkan pengguna untuk menentukan jarak antara kata kunci. Ada juga pencarian berbasis konsep di mana penelitian melibatkan penggunaan analisis statistik pada halaman yang berisi kata atau frasa yang Anda cari.
Kegunaan mesin pencari tergantung pada relevansi set hasil yang diberikannya kembali. Meskipun mungkin ada jutaan halaman web yang mencakup kata atau frasa tertentu, beberapa halaman mungkin lebih relevan, populer, atau otoritatif daripada yang lain. Sebagian besar mesin pencari menggunakan metode untuk memberi peringkat hasil untuk memberikan hasil "terbaik" terlebih dahulu. Bagaimana mesin pencari memutuskan halaman mana yang paling cocok, dan urutan apa hasilnya harus ditunjukkan, sangat bervariasi dari satu mesin ke mesin lainnya. Metode ini juga berubah seiring waktu ketika perubahan penggunaan internet dan teknik baru berkembang. Ada dua jenis utama mesin pencari yang telah berevolusi: satu adalah sistem kata kunci yang telah ditentukan sebelumnya dan dipesan secara hierarkis yang telah diprogram manusia secara luas. Yang lainnya adalah sistem yang menghasilkan "indeks terbalik" dengan menganalisis teks yang ditempatkannya. Formulir pertama ini jauh lebih bergantung pada komputer itu sendiri untuk melakukan sebagian besar pekerjaan.
Sebagian besar mesin pencari web adalah usaha komersial yang didukung oleh pendapatan iklan dan dengan demikian beberapa di antaranya memungkinkan pengiklan memiliki peringkat daftar mereka lebih tinggi dalam hasil pencarian dengan biaya. Mesin pencari yang tidak menerima uang untuk hasil pencarian mereka menghasilkan uang dengan menjalankan iklan terkait pencarian di samping hasil mesin pencari reguler. Mesin pencari menghasilkan uang setiap kali seseorang mengklik salah satu iklan ini.
 .
.

