WebSearchEngine
1.0.0
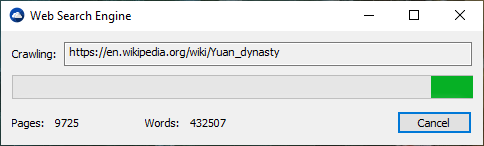
Eine Suchmaschine ist ein Softwaresystem, das für die Durchführung von Websuche entwickelt wurde. Sie suchen das World Wide Web auf systematische Weise nach bestimmten Informationen, die in einer Abfrage zur Textwebsuche angegeben sind. Die Suchergebnisse werden in einer Reihe von Ergebnissen im Allgemeinen dargestellt, die häufig als Suchmaschinenergebnisseiten (SERPs) bezeichnet werden. Die Informationen können eine Mischung aus Links zu Webseiten, Bildern, Videos, Infografiken, Artikeln, Forschungsarbeiten und anderen Arten von Dateien sein. Einige Suchmaschinen werden auch in Datenbanken oder geöffneten Verzeichnissen zur Verfügung stehen. Im Gegensatz zu Webverzeichnissen, die nur von menschlichen Redakteuren gepflegt werden, behalten Suchmaschinen auch Echtzeitinformationen bei, indem ein Algorithmus in einem Web-Crawler ausgeführt wird. Internetinhalte, die nicht in der Lage sind, von einer Web -Suchmaschine durchsucht zu werden, wird im Allgemeinen als Deep Web beschrieben.
Eine Suchmaschine führt die folgenden Prozesse nahezu in Echtzeit bei:
Web -Suchmaschinen erhalten ihre Informationen per Web -Crawling von Site zu Site. Die "Spinnen" prüft, ob der Standard -Dateiname Robots.txt angesprochen wird. Die Datei robots.txt enthält Anweisungen für Suchspinnen, die mitgeteilt werden, welche Seiten kriechen sollen und welche Seiten nicht kriechen sollen. Nachdem die Spinne nach Robots.txt geprüft und entweder gefunden oder nicht gefunden wurde, sendet die Spinne bestimmte Informationen zurück, um je nach Faktoren wie den Titeln, den Seiteninhalten, dem JavaScript, der Cascading -Style -Blätter (CSS), der Überschriften oder seinen Metadaten in HTML -Meta -Tags wieder indiziert zu werden. Nach einer bestimmten Anzahl von Seiten, die in indizierte oder auf der Website aufgewendete Datenmenge, die Spinne, hört die Kriechung auf und geht weiter. "[N] o Web -Crawler kann tatsächlich das gesamte erreichbare Web kriechen. Aufgrund unendlicher Websites, Spinnenfallen, Spam und anderen Erfordernissen des realen Webs wenden Crawler stattdessen eine Crawl -Richtlinie an, um zu bestimmen, wann das Kriechen einer Website ausreichend erachtet werden sollte. Einige Websites werden erschöpfend gekrawldiert, während andere nur teilweise gekrönt werden."
Indexierung bedeutet, Wörter und andere definierbare Token zu assoziieren, die auf Webseiten zu ihren Domain-Namen und HTML-basierten Feldern gefunden wurden. Die Verbände werden in einer öffentlichen Datenbank hergestellt, die für Websuchanfragen zur Verfügung gestellt wird. Eine Abfrage eines Benutzers kann ein einzelnes Wort, mehrere Wörter oder ein Satz sein. Der Index hilft dabei, Informationen über die Abfrage so schnell wie möglich zu finden. Einige der Techniken für die Indexierung und das Caching sind Geschäftsgeheimnisse, während das Web -Crawling ein unkomplizierter Prozess ist, bei dem alle Standorte systematisch besucht werden.
Zwischen den Besuchen der Spinne wird die zwischengespeicherte Version der Seite (einige oder alle Inhalte, die zum Rendern benötigt werden) im Suchmaschinen -Arbeitsspeicher schnell an einen Inquirer gesendet. Wenn ein Besuch überfällig ist, kann die Suchmaschine stattdessen als Web -Proxy fungieren. In diesem Fall kann sich die Seite von den indizierten Suchbegriffen unterscheiden. Die zwischengespeicherte Seite enthält das Erscheinungsbild der Version, deren Wörter zuvor indiziert wurden, sodass eine zwischengespeicherte Version einer Seite für die Website nützlich sein kann, wenn die tatsächliche Seite verloren gegangen ist. Dieses Problem wird jedoch auch als milde Form von Linkrot angesehen.
Wenn ein Benutzer eine Abfrage in eine Suchmaschine eingibt, handelt es sich normalerweise um einige Schlüsselwörter. Der Index enthält bereits die Namen der Websites, die die Schlüsselwörter enthalten, und diese werden sofort aus dem Index erhalten. Die reale Verarbeitungslast besteht darin, die Webseiten zu generieren, die die Liste der Suchergebnisse sind: Jede Seite in der gesamten Liste muss nach Informationen in den Indizes gewichtet werden. Anschließend erfordert das obere Suchergebniselement die Suche, Rekonstruktion und Erschläge der Ausschnitte, die den Kontext der übereinstimmenden Schlüsselwörter zeigen. Diese sind nur ein Teil der Verarbeitung der Webseite der Suchergebnisse erforderlich, und weitere Seiten (neben oben) erfordern mehr von dieser Nachbearbeitung.
Suchmaschinen sind über einfache Keyword-Suchanlagen hinaus ihre eigenen Gui- oder Befehlsbetrieben und Suchparameter, um die Suchergebnisse zu verfeinern. Diese liefern die erforderlichen Steuerelemente für den Benutzer, der in den Feedback -Schleifennutzern beteiligt ist, die durch Filterung und Gewichtung erstellt werden, während die Suchergebnisse angesichts der ersten Seiten der ersten Suchergebnisse verfeinert werden. Ab 2007 hat die Google.com -Suchmaschine eine nach Datum filtern, indem Sie in der Spalte links in der Spalte der ersten Suchergebnisse auf "Suchwerkzeuge anzeigen" klicken und dann den gewünschten Datumsbereich auswählen. Es ist auch nach Datum möglich, da jede Seite eine Änderungszeit hat. Die meisten Suchmaschinen unterstützen die Verwendung der Booleschen Bediener und oder nicht, um Endbenutzern zu helfen, die Suchabfrage zu verfeinern. Boolesche Operatoren sind für buchstäbliche Suchanfragen gedacht, die es dem Benutzer ermöglichen, die Bedingungen der Suche zu verfeinern und zu erweitern. Der Motor sucht nach den Wörtern oder Phrasen genau wie eingegeben. Einige Suchmaschinen bieten eine erweiterte Funktion namens Proximity Search, mit der Benutzer den Abstand zwischen Schlüsselwörtern definieren können. Es gibt auch eine konzeptbasierte Suche, bei der die Forschung die statistische Analyse auf Seiten verwendet, die die von Ihnen gesuchten Wörter oder Phrasen enthalten.
Die Nützlichkeit einer Suchmaschine hängt von der Relevanz des von ihm zurückgegebenen Ergebnismengen ab. Während es möglicherweise Millionen von Webseiten gibt, die ein bestimmtes Wort oder eine bestimmte Phrase enthalten, sind einige Seiten möglicherweise relevanter, populärer oder maßgeblicher als andere. Die meisten Suchmaschinen verwenden Methoden, um die Ergebnisse zu bewerten, um zuerst die "besten" Ergebnisse zu erzielen. Wie eine Suchmaschine entscheidet, welche Seiten die besten Übereinstimmungen sind und in welcher Reihenfolge die Ergebnisse angezeigt werden sollten, variiert stark von einem Motor zu einem anderen. Die Methoden ändern sich auch im Laufe der Zeit, wenn sich die Internetnutzung ändert und sich neue Techniken entwickeln. Es gibt zwei Haupttypen von Suchmaschinen, die sich weiterentwickelt haben: Eines ist ein System vordefinierter und hierarchisch geordneter Schlüsselwörter, die Menschen ausgiebig programmiert haben. Das andere ist ein System, das einen "umgekehrten Index" durch Analyse von Texten erzeugt, die es lokalisiert. Diese erste Form hängt von dem Computer selbst viel stärker ab, um den Großteil der Arbeit zu erledigen.
Die meisten Web -Suchmaschinen sind kommerzielle Unternehmen, die von Werbeeinnahmen unterstützt werden. Einige von ihnen ermöglichen es den Werbetreibenden, ihre Auflistungen gegen eine Gebühr in den Suchergebnissen höher zu sein. Suchmaschinen, die kein Geld für ihre Suchergebnisse akzeptieren, verdienen Geld, indem Sie suchbezogene Anzeigen neben den regulären Suchmaschinenergebnissen ausführen. Die Suchmaschinen verdienen jedes Mal Geld, wenn jemand auf eine dieser Anzeigen klickt.
 .
.

