LinkedIn Connections Analyzer
1.0.0
Conçu un script de grattage Web dans Python à l'aide de sélénium et de belles bibliothèques de soupe pour extraire des informations de toutes les connexions LinkedIn de l'utilisateur, transformé les données collectées et effectué une analyse de base de base sur les données synthétisées. A ensuite développé un tableau de bord d'application Web à l'aide de Dash Framework pour présenter les résultats de l'analyse. Comme on peut le observer ci-dessus, le projet est divisé en 3 parties:
Utilisé le sélénium et les belles bibliothèques de soupe pour effectuer le grattage Web pour extraire les informations des profils des utilisateurs de LinkedIn. Utilisé 3 méthodes: Connexion, connexion_scraper et profil_scraper. Ceux-ci ont été divisés en 3 dataframes: Connections_data, l'éducation et l'expérience.
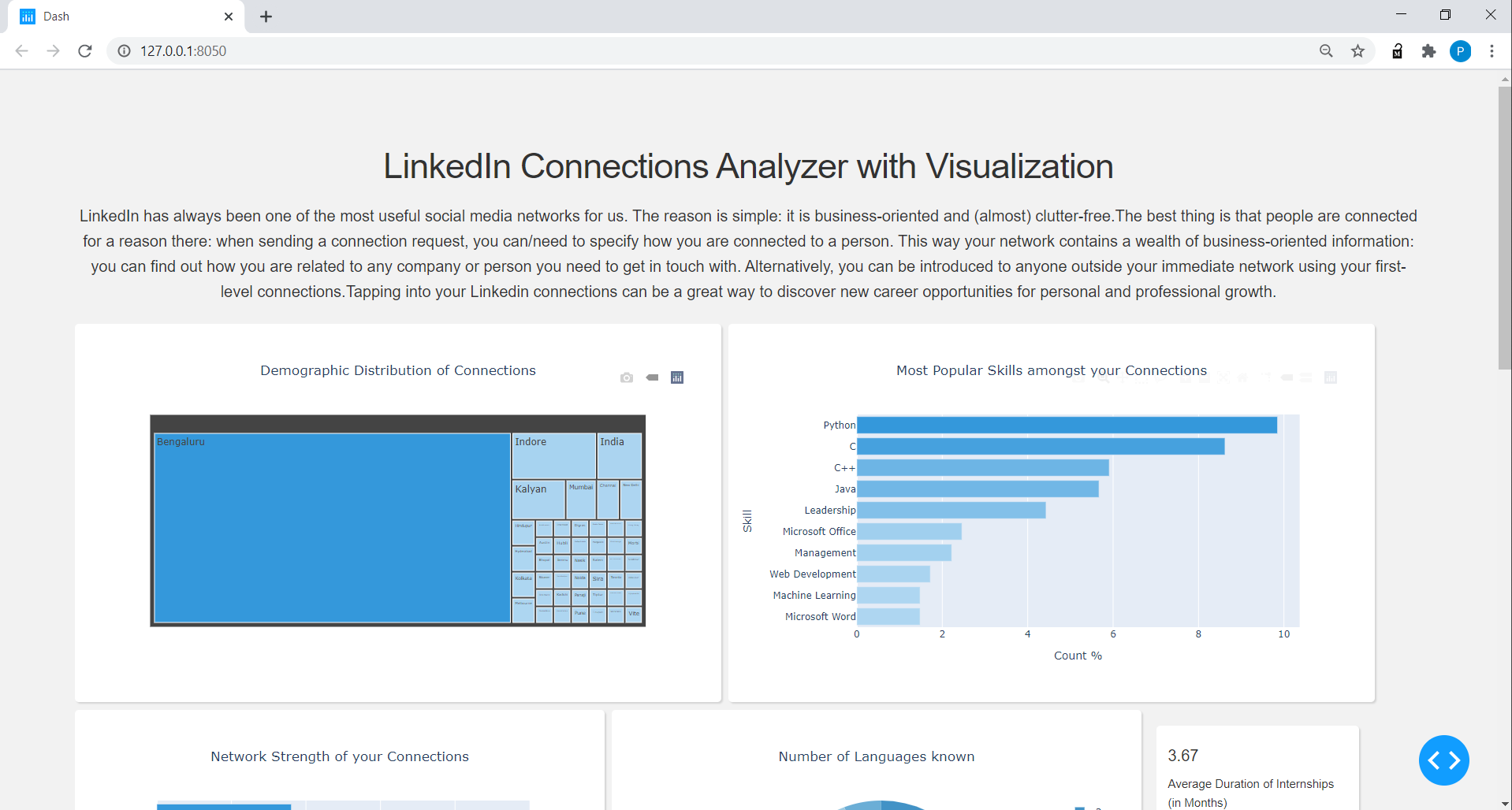
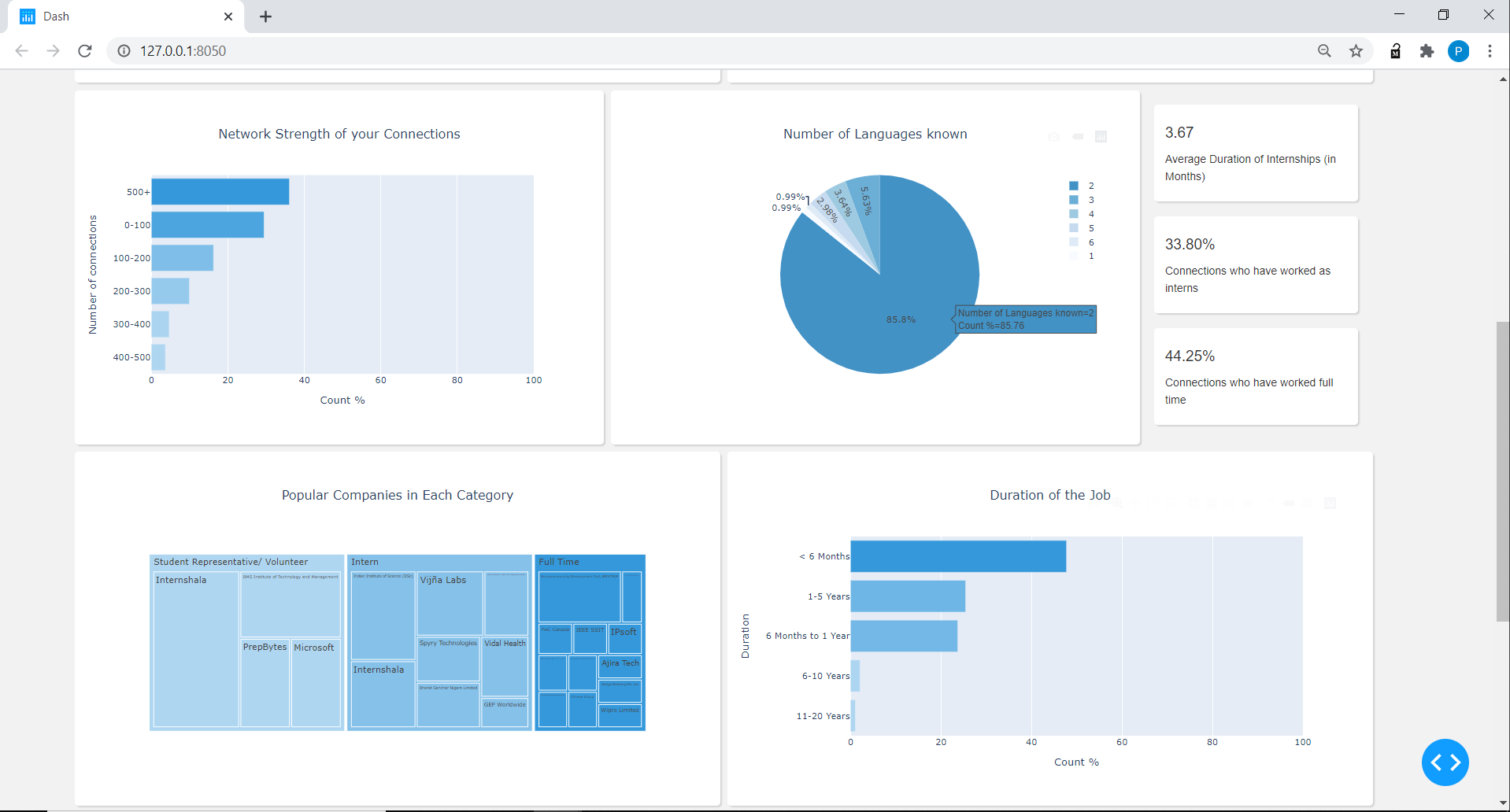
Connections_data: nom extrait, titre, emplacement, profil, nombre de connexions, nombre de projets, nombre de langues connues et compétences supérieures pour les connexions_data.
Éducation: Institut extrait, diplôme et annuel pour l'éducation.
Expérience: Profil extrait, position, entreprise, durée de l'expérience DataFrame.
Les données collectées étaient sous une forme brute et devaient être nettoyées et transformées pour qu'elle soit analysée et acquise des informations. Il y a 3 dataframes à savoir: Connections_data, l'expérience et l'éducation.
Pour les connexions_data dataframe, nettoyé la colonne de localisation pour afficher simplement le nom de la ville sans les mots comme «zone», le nombre divisé de connexions en 6 catégories de plage telles que 0-100, 100-200, ... à 500+, nombre de langues, le nombre de projets et ont créé un dictionnaire pour les compétences en tête.
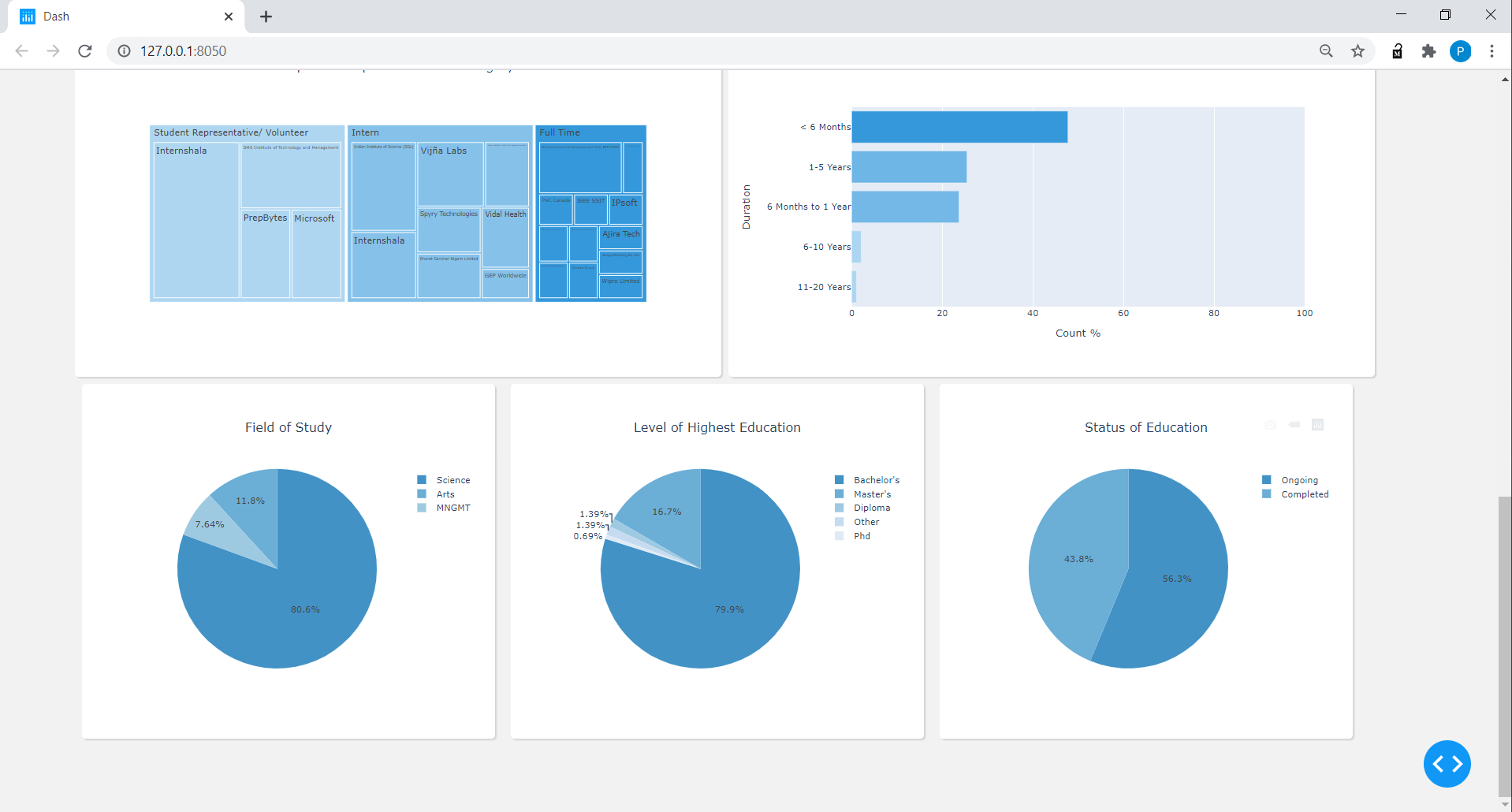
Pour l'éducation, DataFrame, sur la base de l'institut et du nom de diplôme, a classé le domaine d'étude en 3 catégories (pour le moment, pour la simplicité): science, gestion et arts, a trouvé le statut de l'éducation sur la base de la gamme de l'année fournie sur le profil d'un niveau d'éducation particulier. J'ai également découvert le plus haut niveau d'éducation pour les connexions en fonction des mots «baccalauréat», «maître», etc., etc. donné dans le domaine de l'éducation sur le profil.
Pour l'expérience DataFrame, divisé la colonne de position en 3 catégories: temps plein, stagiaires, représentants étudiants ou bénévoles, a fait 6 catégories dans la colonne de durée en commençant par <6 mois à 20 ans et plus.
DASH est le cadre de confiance le plus téléchargé pour créer des applications Web ML & Data Science. Des applications complètes qui nécessiteraient généralement une équipe frontale, backend et Dev Ops peuvent désormais être construites et déployées en heures par des scientifiques de données avec Dash. Avec Dash Open Source, les applications DASH s'exécutent sur votre ordinateur portable local ou votre poste de travail, mais ne peuvent pas être facilement accessibles par d'autres membres de votre organisation. Pour en savoir plus et comprendre Dash, visitez https://plotly.com/dash/
La bibliothèque graphique Python de Plotly fabrique des graphiques interactifs de qualité de publication. Le module Plotly.Express (généralement importé en PX) contient des fonctions qui peuvent créer des chiffres entières à la fois, et qui est appelé Plotly Express ou PX. Plotly Express est une partie intégrée de la bibliothèque Plotly, et est le point de départ recommandé pour créer des chiffres les plus courants. Pour en savoir plus sur Plotly, visitez https://plotly.com/python/
Comme c'est la première fois que nous utilisons Dash, le tableau de bord semble assez simple (composé de graphiques à barres interactifs et de graphiques à tarte avec carreaux et cartes d'arbres), mais très informative. Nous prévoyons d'incorporer plus de changements en ce qui concerne les subtilités dans le niveau ou le domaine d'étude / travail plus tard.
Remarque: il est important d'avoir le dossier Assets dans le même dossier dans lequel vous implémentez votre application, car il est nécessaire aux fins de Stlying.