LinkedIn Connections Analyzer
1.0.0
Diseñó un script de raspado web en Python utilizando selenio y hermosas bibliotecas de sopa para extraer información de todas las conexiones de LinkedIn del usuario, transformó los datos recopilados y realizó un análisis de datos básicos en los datos sintetizados. Luego desarrolló un panel de aplicaciones web utilizando el marco de DASH para presentar los hallazgos del análisis. Como se puede observar anteriormente, el proyecto se divide en 3 partes:
Usé las bibliotecas de Selenium y hermosas de sopa para realizar el raspado web para extraer información de los perfiles de los usuarios de LinkedIn. Usados 3 métodos: Iniciar sesión, Connections_Scraper y perfil_scraper. Estos se dividieron en 3 marcos de datos: Connections_Data, educación y experiencia.
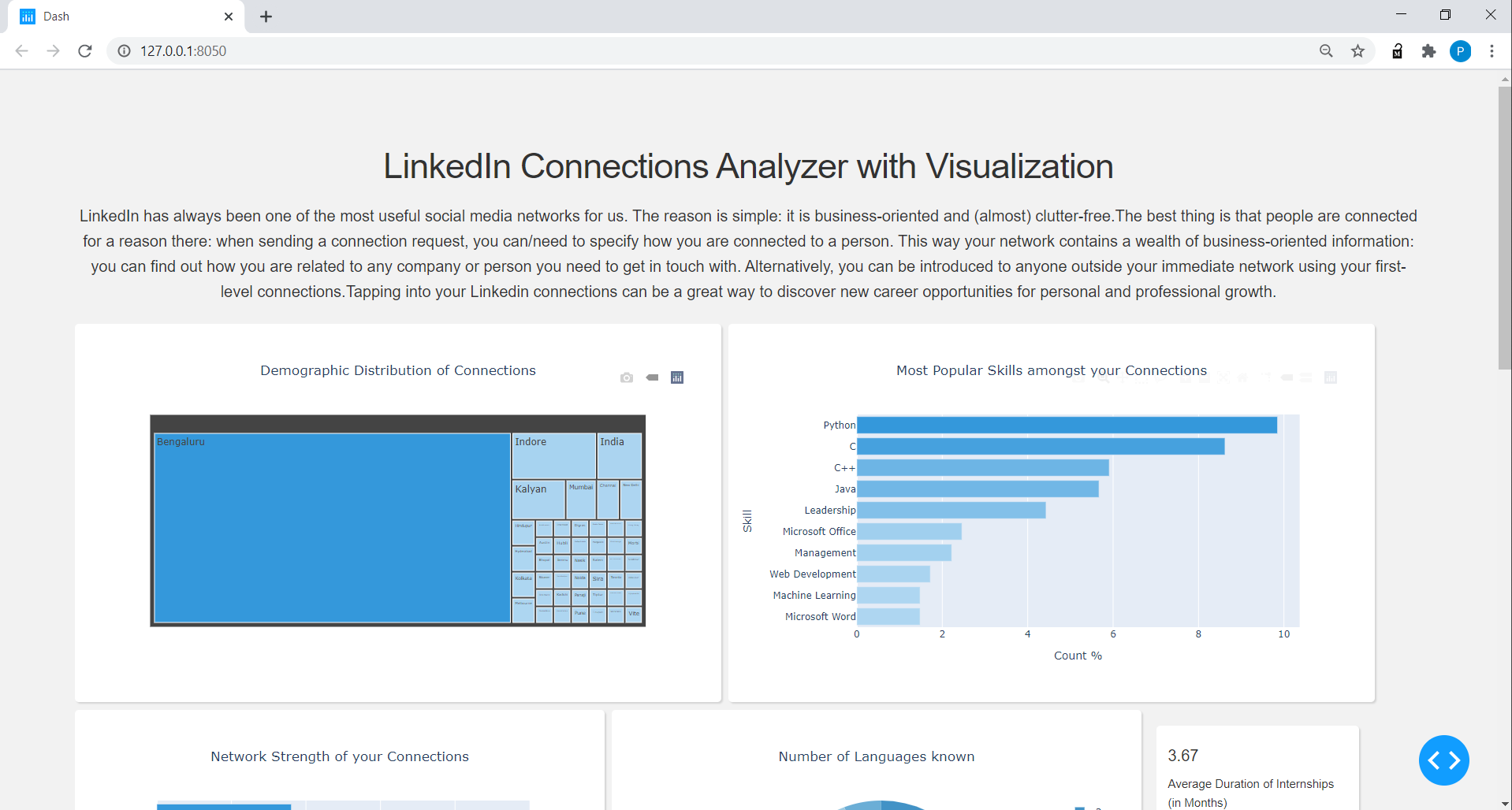
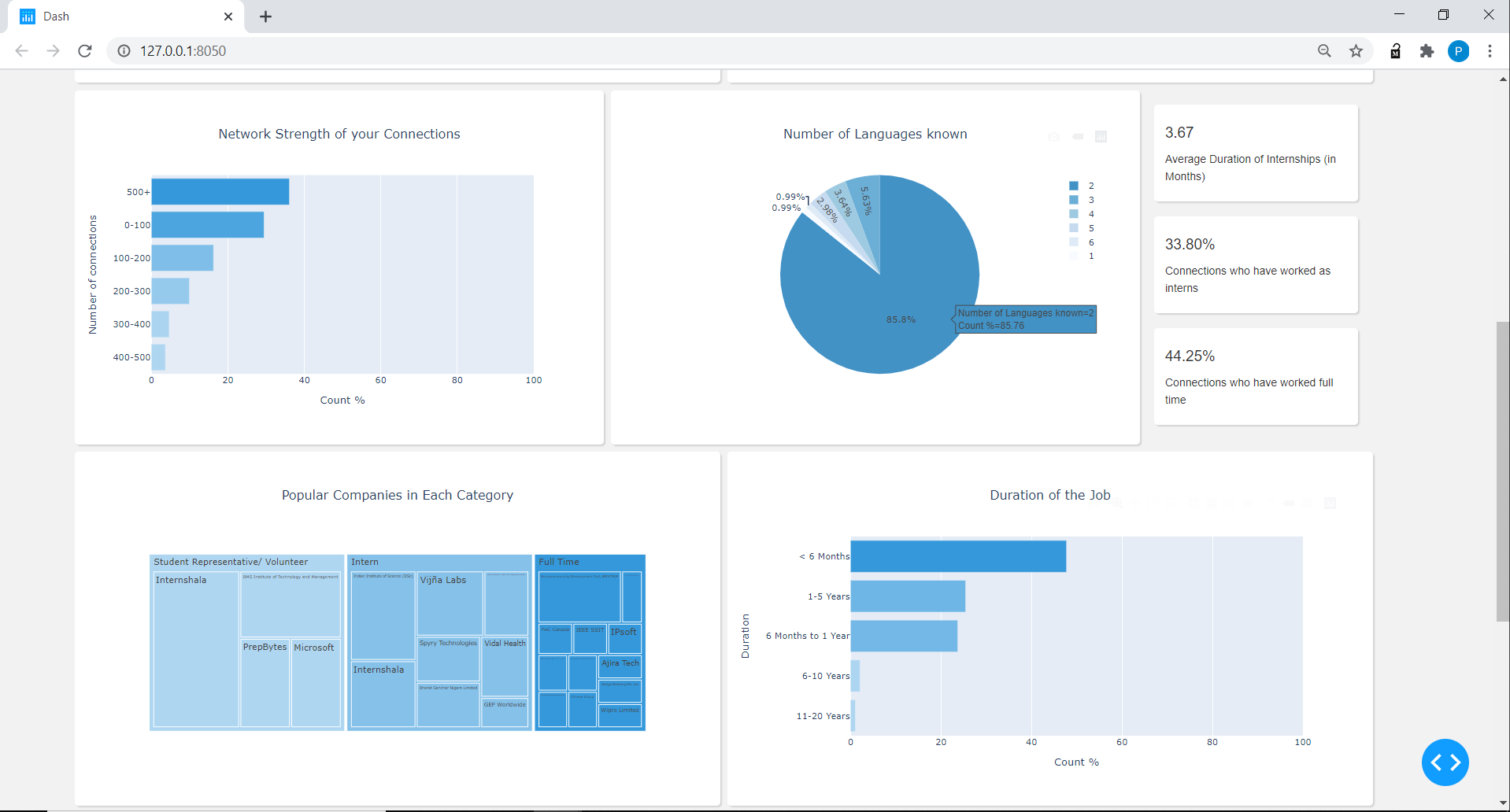
Connections_data: nombre extraído, título, ubicación, perfil, número de conexiones, número de proyectos, número de idiomas conocidos y habilidades principales para el Connections_Data.
Educación: Instituto Extraído, Grado y Rango de Año para la Educación.
Experiencia: perfil extraído, posición, empresa, duración para la experiencia DataFrame.
Los datos recopilados estaban en forma sin procesar y tuvieron que limpiarse y transformarse para que se analizara y obtuviera información. Hay 3 marcos de datos, a saber: Connections_Data, experiencia y educación.
Para el cuadro de datos de Connections_Data, limpie la columna de ubicación para mostrar el nombre de la ciudad sin las palabras como 'área', el número dividido de conexiones en 6 categorías de rango, como 0-100, 100-200, ... a 500+, número de idiomas, número de proyectos y creó un diccionario para los 3 principales destacados de cada uno de las conexiones y luego finalmente contando el número de personas para cada habilidad para cada habilidad.
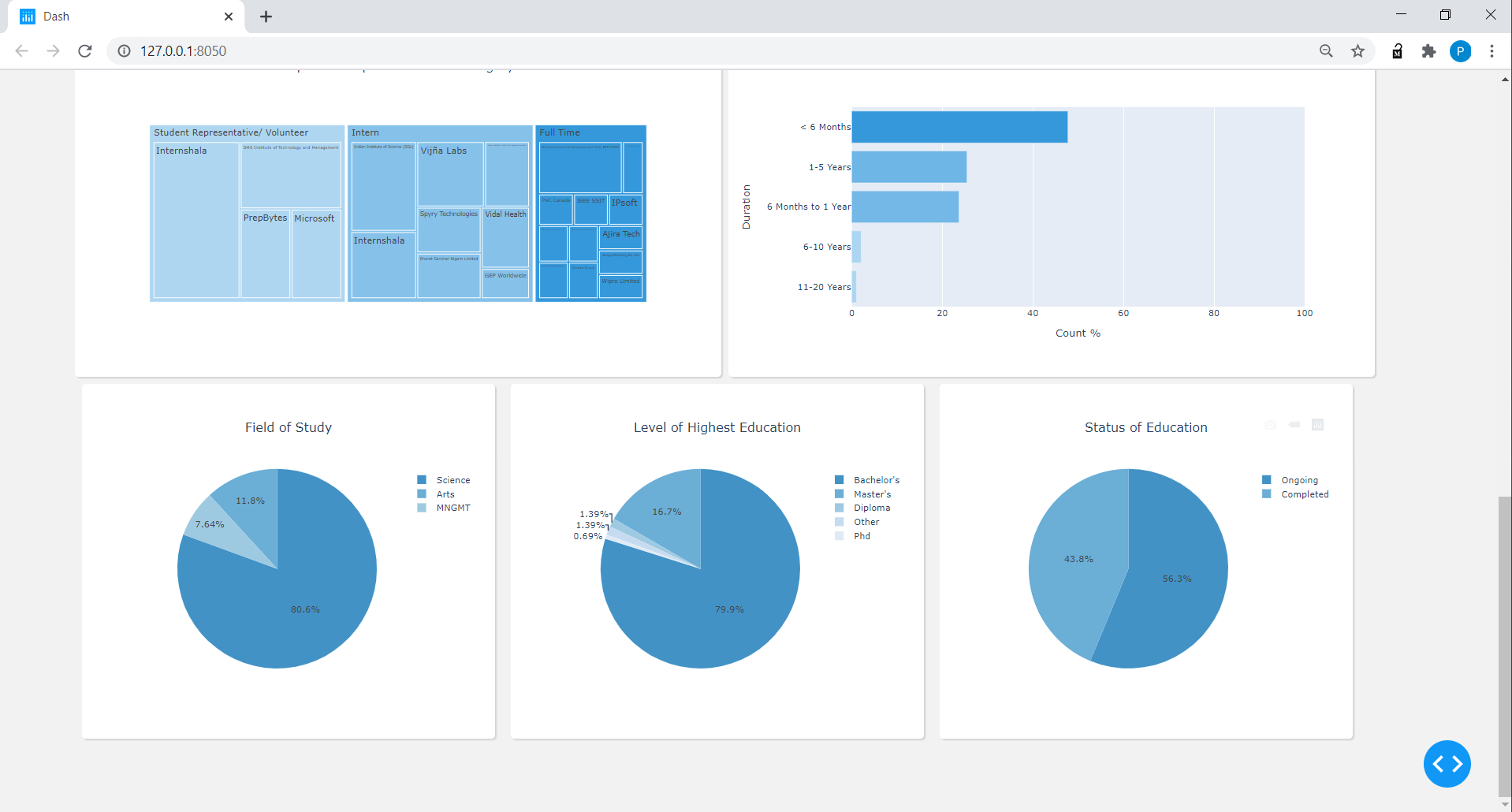
Para el marco de datos de educación, sobre la base del instituto y el nombre de grado clasificó el campo de estudio en 3 categorías (por el momento, por simplicidad): la ciencia, la gestión y las artes, descubrieron el estado de educación sobre la base del rango de año proporcionado en el perfil para un nivel educativo particular. También descubrió el más alto nivel de educación para las conexiones basadas en las palabras 'Bachiller's', 'Master's', etc. dada en el campo de la educación en el perfil.
Para la experiencia de DataFrame, dividió la columna de posición en 3 categorías: a tiempo completo, pasantes, representantes estudiantiles o voluntarios, realizó 6 categorías bajo la columna de duración a partir de <6 meses a más de 20 años.
Dash es el marco de confianza más descargado para construir aplicaciones web de ML y ciencias de datos. Las aplicaciones completas de pila que generalmente requerirían un equipo frontal, de backend y Dev Ops ahora pueden ser construidos e implementados en horas por científicos de datos con Dash. Con el código abierto de Dash, las aplicaciones DASH se ejecutan en su computadora portátil o estación de trabajo local, pero otros en su organización no pueden acceder fácilmente. Para leer más y comprender a Dash, visite https://plotly.com/dash/
La biblioteca de gráficos de Python de Plotly hace gráficos interactivos de calidad de publicación. El módulo de Express (generalmente importado como PX) contiene funciones que pueden crear figuras completas a la vez, y se conoce como Plotly Express o PX. Plotly Express es una parte incorporada de la biblioteca Plotly, y es el punto de partida recomendado para crear figuras más comunes. Para saber más sobre Plotly, visite https://plotly.com/python/
Dado que esta es la primera vez que usamos Dash, el tablero se ve bastante simple (que consiste en gráficos de barras interactivos y gráficos de pasteles con azulejos y mapas de árboles), pero muy informativos. Planeamos incorporar más cambios con respecto a las complejidades en el nivel o el campo de estudio/trabajo más adelante.
Nota: Es importante tener la carpeta de activos en la misma carpeta en la que implementa su aplicación, ya que es necesario para los fines estadios.